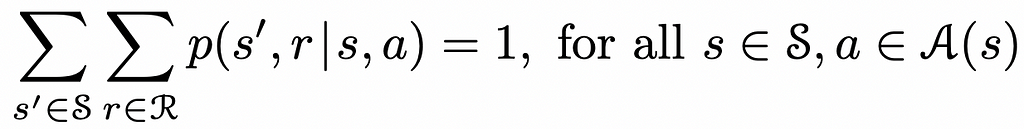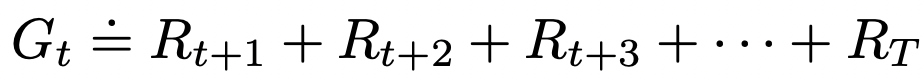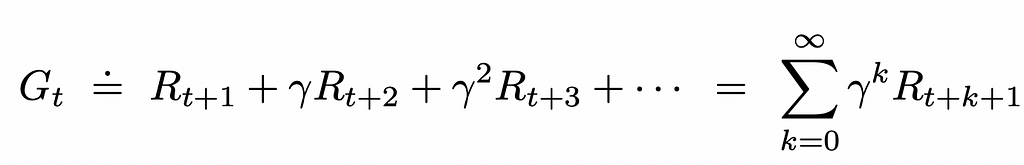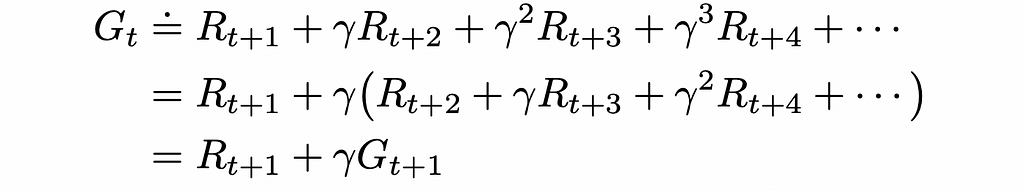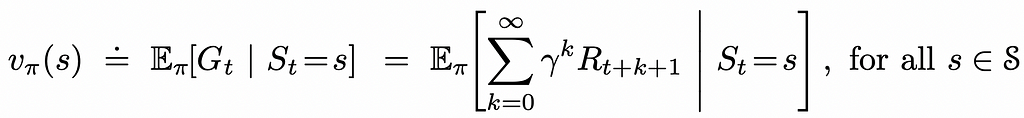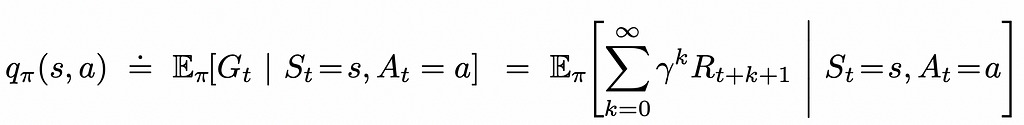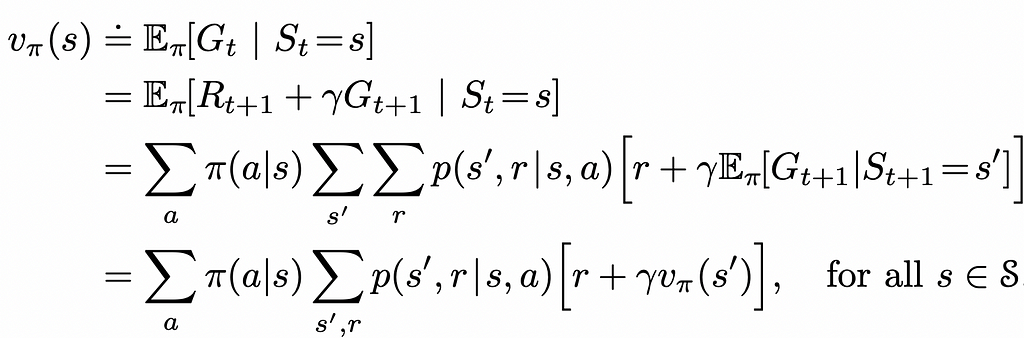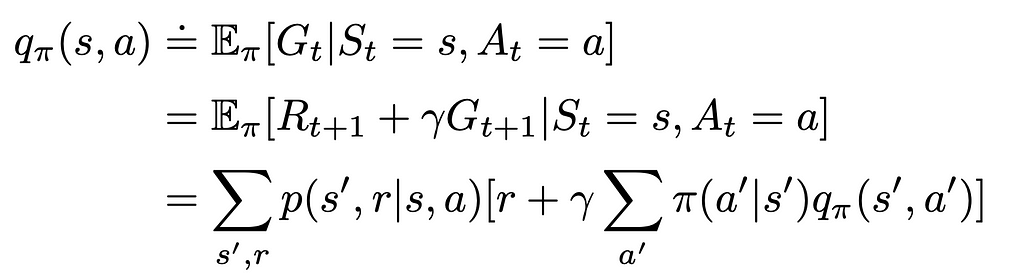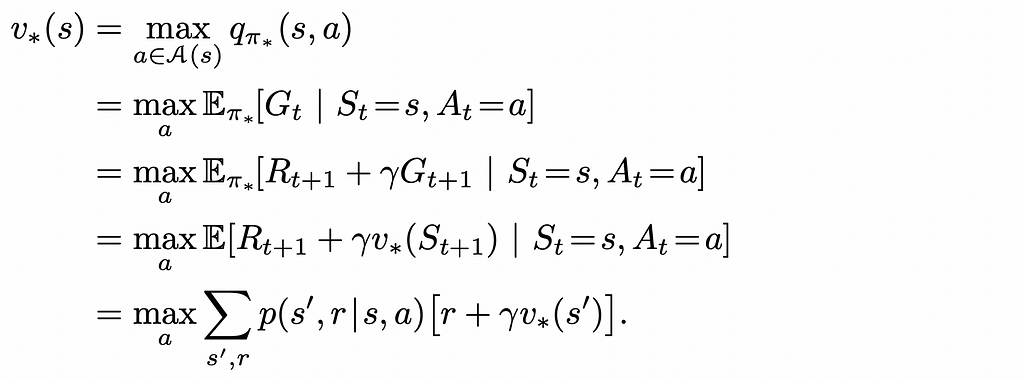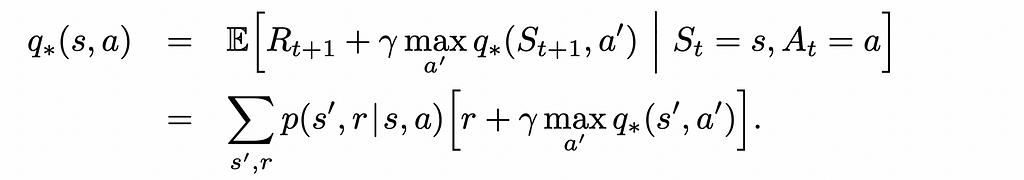TLDR Funding rates have soared recently and could affect the bullish trajectory of Bitcoin (BTC). Yet many market analysts believe BTC can rebound by the end of the year to reach a price of $98,190. Several experts have suggested Rebel Satoshi ($RBLZ) could be one of the best crypto investment opportunities right now amid a […]
NEO price soared more than 40% to hit a two-year high above $22. Toncoin extended gains seen on Monday as price discovery drove TON to a new all-time high. The crypto market recorded a decent bounce on Monday, with Bitcoin price hitting highs above $72,000 to buoy multiple altcoins. Toncoin and NEO are some of […]
The U.S. Treasury is pushing for more authority to tackle the growing misuse of crypto by Iran, Russia, and North Korea. According to a report from Bloomberg, Deputy Secretary Adewale Adeyemo emphasized in written testimony ahead of a Senate hearing…
Ripple announces plans to introduce a stablecoin, while Starknet slashes its declaration fee by 30x. Meanwhile, analysts spotlight NuggetRush as the upcoming standout in the crypto gaming landscape. #partnercontent
March heralded a resurgence in the cryptocurrency market, highlighted by a significant surge in spot Bitcoin ETF volumes, Polkadot’s strategic advancements, and the rise of Borroe Finance (ROE). #partnercontent
Ethereum showed signs of accumulation from investors in the past three weeks.
The momentum when disbelief turns into FOMO could usher in even more gains for ETH.
Making the first step into the world of reinforcement learning
Introduction
Reinforcement learning is a special domain in machine learning that differs a lot from the classic methods used in supervised or unsupervised learning.
The ultimate objective consists of developing a so-called agent that will perform optimal actions in environments. From the start, the agent usually performs very poorly but as time goes on, it adapts its strategy from the trial and error approach by interacting with the environment.
The beauty of reinforcement learning is that the same algorithms can be used to make the agent adapt to absolutely different, unknown, and complex conditions.
Reinforcement learning has a wide range of applications and mostly used when a given problem cannot be solved by classic methods:
Games. Existing approaches can design optimal game strategies and outperform humans. The most well-known examples are chess and Go.
Robotics. Advanced algorithms can be incorporated into robots to help them move, carry objects or complete routine tasks at home.
Autopilot. Reinforcement learning methods can be developed to automatically drive cars, control helicopters or drones.
Some of the reinforcement learning applications
About this article
Though reinforcement learning is a very exciting and unique area, it is still one of the most sophisticated topics in machine learning. In addition, it is absolutely critical from the beginning to understand all of its basic terminology and concepts.
For these reasons, this article introduces only the key theoretical concepts and ideas that will help the reader to further advance in reinforcement learning.
Additionally, this article is based on the third chapter of the famous book “Reinforcement Learning” written by Richard S. Sutton and Andrew G. Barto, whichI would highly recommend to everyone interested in delving deeper.
Apart from that, this book contains practical exercises. Their solutions can be found in this repository.
Reinforcement learning framework
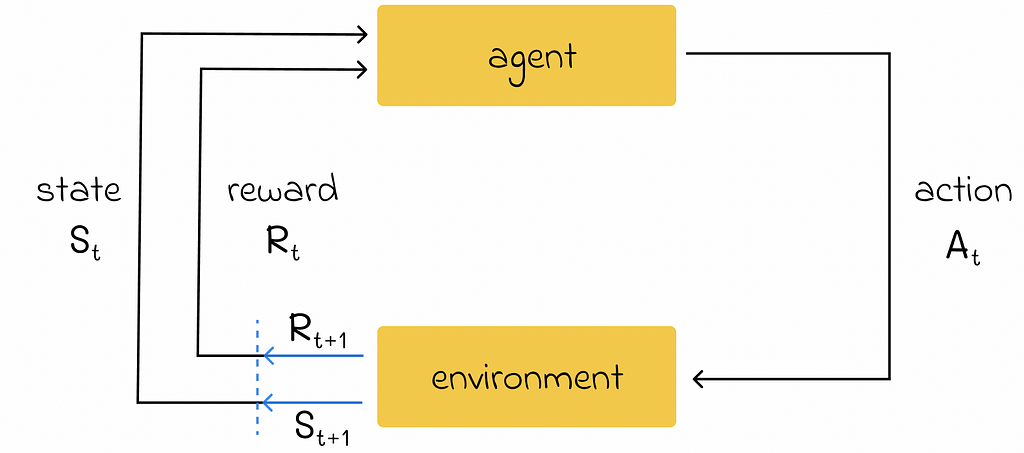
First of all, let us understand the reinforcement learning framework which contains several important terms:
Agent represents an object whose goal is to learn a strategy to optimize a certain process;
Environment acts as a world in which the agent is located and consists of a set of different states;
At each timestamp, the agent can perform an action in the environment that will change the environment’s state to a new one. Additionally, the agent will receive feedback indicating how good or bad the chosen action was. This feedback is called a reward and is represented in the numerical form.
By using feedback from different states and actions, the agent gradually learns the optimal strategy to maximize the totalreward over time.
In many cases, given the current state and the agent’s action in that state, the change to a new state can result in different rewards (rather a single one) where each of them corresponds to its own probability.
The formula below considers this fact by summing up over all possible next states and rewards that correspond to them.
To make things more clear, we are going to use the prime ’ symbol to designate a variable in its next step. For example, if s represents the agent’s current state, then s’ will refer to the next agent’s state.
Reward types
To formally define the total reward in the long run, we need to introduce the term the “cumulative reward” (also called “return”) which can take several forms.
Simple formulation
Let us denote Rᵢ as the reward received by the agent at timestamp i, then the cumulative reward can be defined as the sum of rewards received between the next timestamp and the final timestamp T:
Most of the time, the discounted cumulative reward is used. It represents the same reward system as before except for the fact that every individual reward in the sum is now multiplied by an exponentially decayed discount coefficient.
The γ (also sometimes denoted as α) parameter in the formula above is called the discount rate and can take a value between 0 and 1. The introduction of discounted reward makes sure that the agent prioritizes actions that result in more short-term rewards. Ultimately, the discounted cumulative reward can be expressed in the recursive form:
In some cases, the interaction between an agent and the environment can include a set of independent episodes. In this scenario, every episode starts independently from others and its beginning state is sampled from the distribution of states.
For instance, imagine that we want the agent to learn the optimal strategy to play a game. To do that, we will run a set of independent games where in each of them a robot can either win or lose. The received rewards in every episode will gradually influence the strategy that the robot will be using in the following games.
Episodes are also referred to as trials.
Continuing tasks
At the same time, not all types of tasks are episodic: some of them can be continuing meaning that they do not have a terminal state. In such cases, it is not always possible to define the cumulative return because the number of timestamps is infinite.
Policies and value functions
Policy
Policy πis a mapping between all possible states s ∈ S to probabilities p of performing any possible action from that state s.
If an agent follows a policy π, then the agent’s probability p(a | s) of performing the action a from state s is equal to p(a | s) = π(s).
By definition, any policy can be represented in the form of a table of size |S| x |A|.
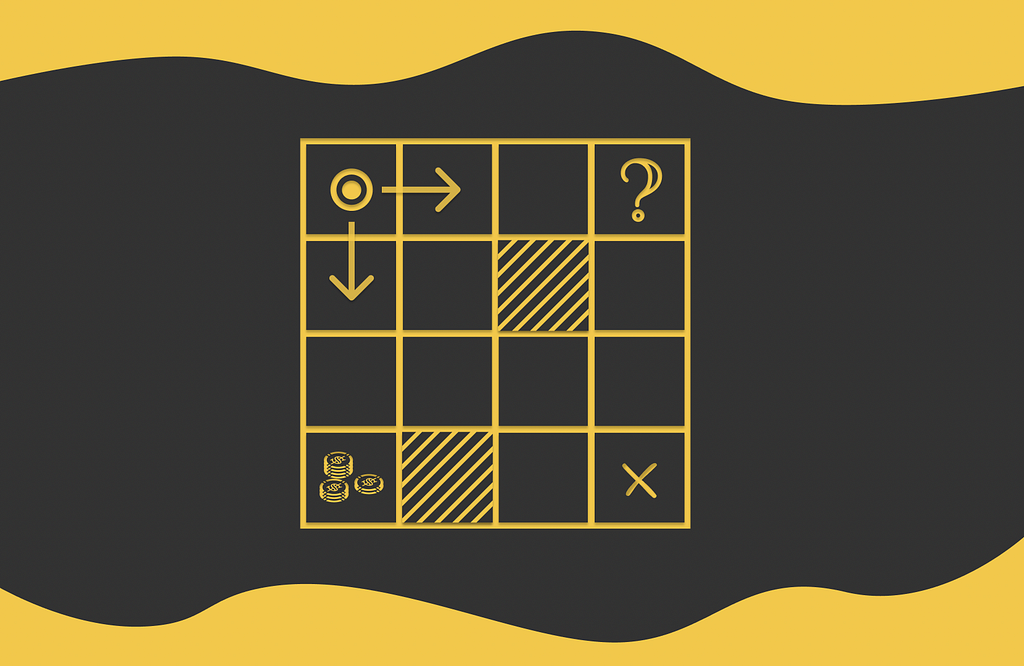
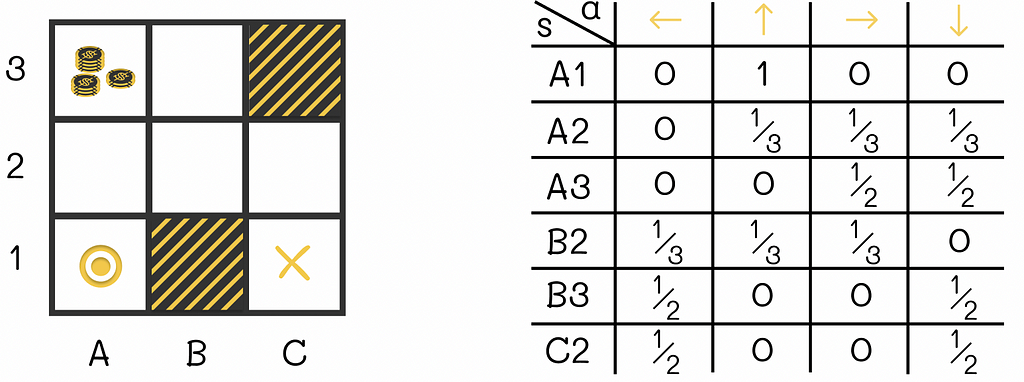
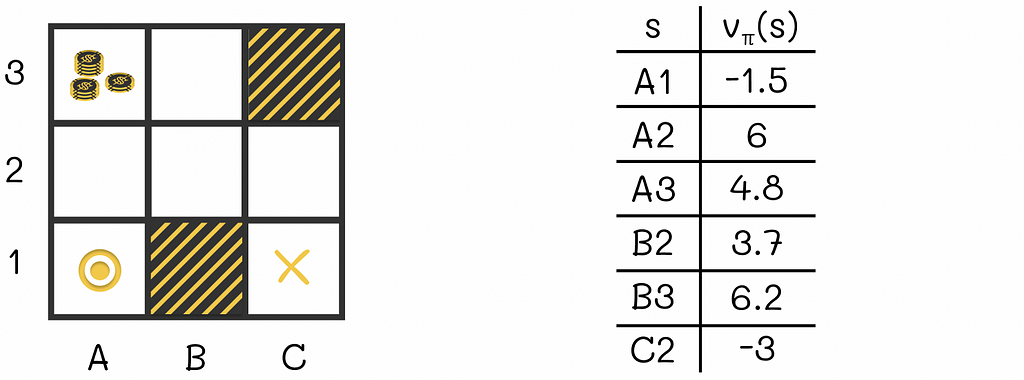
Let us look at the example of the maze game below. The agent that is initially located at the A1 cell. During each step, the agent has to move either horizontally or vertically (not diagonally) to an adjacent cell. The game ends when the agent reaches the terminal state located at C1. The cell A3 contains a large reward that an agent can collect if it steps on it. The cells B1 and C3 are maze walls that cannot be reached.
Maze example with 7 possible states (the cells B1 and C3 are maze walls). The game starts with the agent being put at A1 and ends when the agent reaches C1. The cell A3 contains a large reward.
One of the simplest policies that can be used is random: at each state, the agent randomly moves to any allowed cell with equal probability. The corresponding policy for this strategy is illustrated in the figure above.
The demonstrated maze is also an example of an episodic task. After reaching the terminal state and obtaining a certain reward, a new independent game can be initialized.
Apart from policies, in reinforcement learning, it is common to use the notion of value functions which describe how good or bad (in terms of the expected reward) it is for the agent to be in a given state or to take a certain action given the current state.
State-value function
State-value function v(s) (or simply V-function) is a mapping from every environment state to the cumulative expected reward the agent would receive if it were initially placed at that state following a certain policy π.
V-function can be represented as a 1-dimensional table of size |S|.
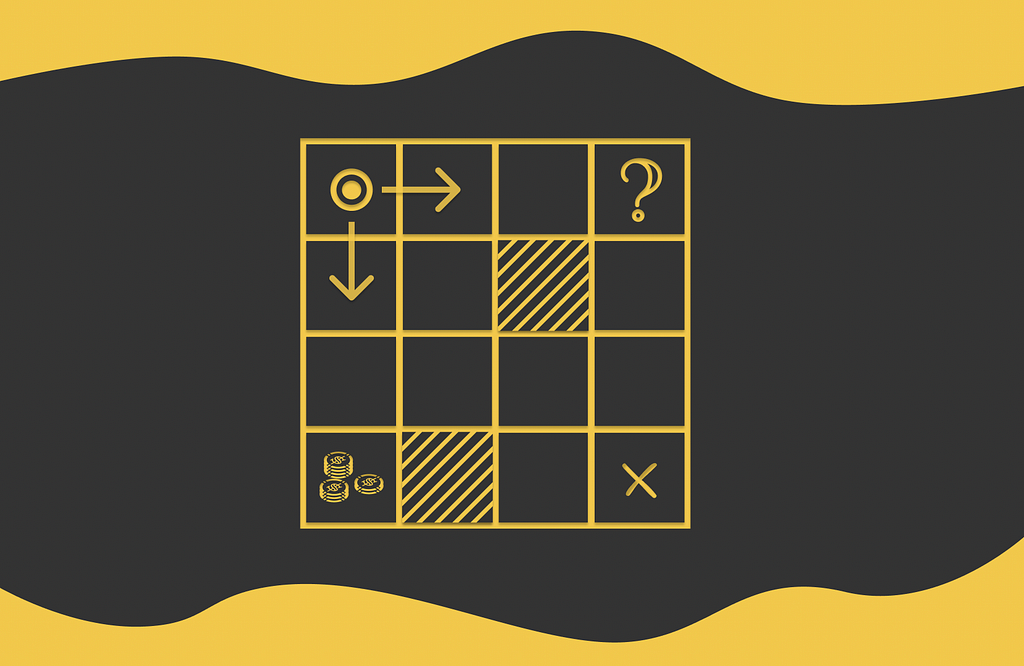
To better understand the definition of the V-function, let us refer to the previous example. We can see that cells located in the neighbourhood of A3 (which are A2, A3 and B3) have higher V-values than those located further from it (like A1, B2 and C2). This makes sense because being located near a large reward at A3, the agent has a higher chance to collect it.
V-function example. Every game state corresponds to a cumulative reward the agent would receive if it were initially placed in it.
The V-value for terminal states is equal to 0.
Action-value function
Action-value functions have similar concept, in comparison to state-value functions. However, they also take into account a possible action the agent can take under a given policy.
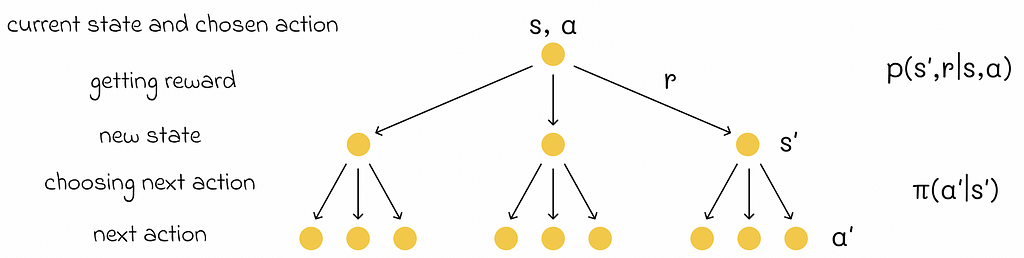
Action-value function q(s, a) (or simply Q-function) is a mapping from each environment state s ∈ S and each possible agent’s action a ∈ A to the expected reward the agent would receive if it were initially placed at that state and had to take that action following a certain policy π.
Q-function can be represented in the form of table of size |S| x |A|.
The difference between state and action functions is only in the fact that the action-value function takes additional information about the action the agent is going to take in the current state. The state function only considers the current state and does not take into account the next agent’s action.
Both V- and Q-functions are learned from the agent’s experience.
A subtility on V- and Q-values
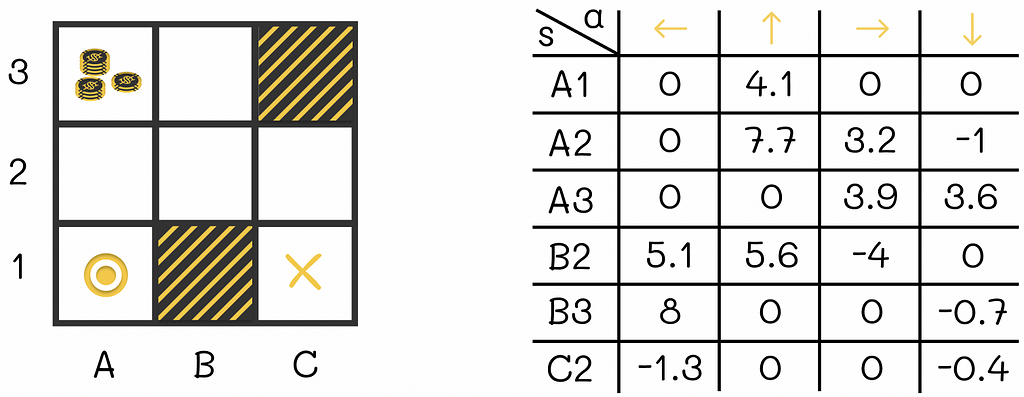
Why is q(s, a) ≠ v(s’), i.e.why the expected reward of an agent being in state s and taking the action a leading to next state s’ is not equal to the expected reward of an agent being in state s’?
This question might seem logical at first. Indeed, let us take the agent from the example above who is at cell B2 and assume that it then makes a transition to B3. From the Q-table we can see that the expected reward q(B2, “up”) = 5.6. At the same time, the V-table shows the expected reward v(B3) = 6.2. While 5.6 is relatively close to 6.2, both values are still not equal. So the ultimate question is why q(B2, “up”) ≠ v(B3)?
The answer to this question lies in the fact that despite choosing an action in the current state s that deterministically leads to the next state s’, the reward received by the agent from that transition is taken into account by the Q-function but not by the V-function. In other words, if the current timestamp is t, then the expected reward q(s, a) will consider the discounted sum starting from the step t: Rₜ + αRₜ₊₁ … . The expected reward corresponding to v(s’) will not have the term Rₜ in its sum: Rₜ₊₁ + αRₜ₊₂ + … .
It is worth additionally noting that sometimes an action a taken at some state s can lead to multiple possible next states. The simple maze example above does not demonstrate this concept. But we can add the following condition, for instance, to the agent’s actions: when the agent chooses a direction to move in the maze, there is a 20% chance that the light in the new cell will be turned off and because of that the agent will ultimately move by 90° relatively to that direction.
The introduced concept demonstrates how the same action from the same state can lead to different states. As a consequence, the rewards received by the agent from the same action and state can differ. That is another aspect that contributes to the inequality between q(s, a) and v(s’).
Bellman equation
Bellman equation is one of the fundamental equations in reinforcement learning! In simple words, it recursively establishes the state / action function values at the current and next timestamps.
V-function
By using the definition of the expected value, we can rewrite the expression of the state value function to use the V-function of the next step:
What this equality states is simply the fact that the v-value of the current state s equals the expected value of the sum of the reward received by the agent from transitioning to that state s and the discounted v-value of the next state s’.
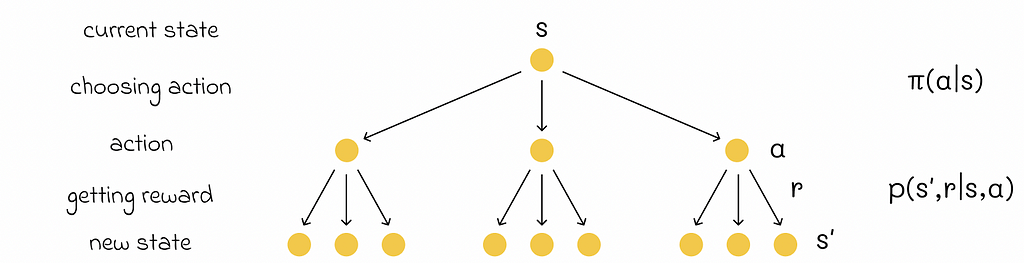
In their book, Richard S. Sutton and Andrew G. Barto use so-called “backup diagrams” that allow to better understand the flow of state functions and capture the logic behind the probability multiplication which take places in the Bellman equation. The one used for the V-function is demonstrated below.
Let us define the comparison operation between different policies.
A policy π₁ is said to be better than or equal to policy π₂ if the expected reward of π₁ is greater than or equal to the expected reward of π₂ for all states s ∈ S.
A policy π⁎ is said to be optimal if it is better than or equal to any other policy.
Every optimal policy also has the optimal V⁎- and Q⁎-functions associated with it.
Bellman optimality equation
We can rewrite Bellman equations for optimal policies. In reality, they look very similar to normal Bellman equations we saw before except for the fact that that the policy term π(a|s) is removed and the max function is added to deterministically get the maximum reward from choosing the best action a from the current state s.
These equations can be mathematically solved for every state. If either the optimal V⁎-function or Q⁎-function is found, the optimal policy π⁎ can also be easily calculated which will always greedily choose the actions that maximise the expected reward.
Unfortunately, it is very hard in practice to mathematically solve Bellman equations because the number of states in most problems is usually huge. For this reason, reinforcement learning methods are used that can approximately calculate optimal policies with much fewer computations and memory requirements.
Conclusion
In this article, we have discussed how agents learn through experience by the trial and error approach. The simplicity of the introduced reinforcement learning framework generalizes well for many problems, yet provides a flexible way to use the notions of policy and value functions. At the same time, the utlimate algorithm objective consists of calculating the optimal V⁎– and Q⁎– functions maximizing the expected reward.
Most of the existing algorithms try to approximate the optimal policy function. While the best solution is almost impossible to get in real-world problems due to memory and computation constraints, approximation methods work very well in most situations.
Logitech has unveiled the G Pro X 60, its latest mechanical gaming keyboard. Similar to the peripheral maker’s G Pro X TKL from last year, this is a wireless model aimed at competitive-minded gamers first and foremost. Unlike that device, it has a smaller 60 percent layout, which means it lacks a dedicated function row, number pad, arrow keys and nav cluster but takes up much less space on a desk. This can be a boon for games because it leaves more room to flick a mouse around while retaining the most common action keys. Naturally, it’s also more portable.
The G Pro X 60 is up for pre-order today for $179 in the US or €229 in Europe. It’s available in three colors (black, white or pink) with either the linear or tactile version of Logitech’s GX Optical switches. The company says it’ll be available at major retailers in “late April.”
I’ve had the keyboard on hand for a few days prior to today’s announcement and have mostly been impressed, though I’d have a hard time calling it a great value.
Let’s start with the good: This thing is well-built. Its aluminum top plate is surrounded by a plastic frame, but it all feels sturdy, with no real flex or give when you press down. Its doubleshot PBT keycaps are pleasingly crisp and should avoid any of the shininess that’d develop with cheaper ABS plastic over time. The legends on the keycaps are neatly printed and transparent, so any RGB backlight effects you set will come through cleanly. All the keys are angled comfortably, and there’s a set of flip-out feet on the back.
Logitech
I’m not crazy about the side-mounted volume roller — once you’ve blessed your keyboard with a full-on rotary knob, it’s hard to give up — but it’s easy to reach with your pinky, so you can adjust volume without having to lift your other fingers during the heat of a game. There’s also a dedicated switch for flipping on Logitech’s “game mode,” which deactivates keys you might otherwise hit by accident; those include the Windows and Fn keys by default, but you can add others through Logitech’s G Hub software.
The keyboard can connect over a detachable USB-C cable, Bluetooth or a 2.4GHz wireless dongle. Per usual with Logitech gear, the latter’s connection is rock solid; I’ve had none of the hiccups or stuttering I’ve seen with some wireless keyboards from less established brands, particularly when waking the device from sleep. There are buttons to swap between Bluetooth or the 2.4GHz connection built into the board, as well as a handy compartment for stashing the adapter itself. You can also connect the G Pro X 60 and certain Logitech mice simultaneously using one dongle. Logitech rates the battery life at up to 65 hours; that sounds about right based on my testing so far, but the exact amount will fluctuate based on how bright you set the RGB backlight.
The best thing about the G Pro X 60 might have nothing to do with the keyboard at all — it’s the fact that Logitech includes a hard carrying case in the box. More companies should do this! It makes the device much easier to transport.
Alas, this probably isn’t a keyboard you’d want to take to the office. The linear GX Optical switches in my test unit feel totally pleasant: They’re fast enough for gaming, and they come pre-lubricated, so each press goes down smoothly. Since they’re optical, and thus not reliant on any physical contact points, they should also prove durable over time.
Logitech
But they aren’t exactly quiet. Logitech has fit a couple layers of silicone rubber inside the board, but there isn’t the wealth of sound-dampening foam you’d find in some other options in this price range. To peel back the curtain a bit: I received the G Pro X 60 just after testing a bunch of mechanical keyboards for an upcoming buying guide, so I’m a little spoiled on this point. Some people may like the obvious clack of each press here, too. I can’t imagine their coworkers or roommates being as thrilled, though, and some modifier and nav keys like Alt, Ctrl and Tab sound hollower than others.
Besides that, my issues with the G Pro X 60 are more about what’s missing than anything the keyboard does wrong. For one, its switches aren’t hot-swappable, so you can’t easily remove and replace them without desoldering. Yes, this is a niche thing, but so are $180 gaming keyboards as a whole. Being able to pop in new switches isn’t just a plus for long-term repairability; it’s half the fun for some keyboard enthusiasts in the first place. Swapping keycaps is straightforward, though.
Taking a step back, a growing number of the G Pro X 60’s peers have some sort of analog functionality, which means they can respond to varying levels of pressure. The top pick in our gaming keyboard buyer’s guide, the Wooting 60HE+, is a good example: Its magnetic Hall effect sensors let you set custom actuation points, so you can make each key extra sensitive while playing a fast FPS, then make them feel heavier and more deliberate while typing. They also enable a “rapid trigger” feature that lets you repeat inputs faster, which can be helpful for, say, strafing back and forth during an in-game shootout. Other models from Razer and SteelSeries provide similar functionality. But the G Pro X 60 lacks any sort of adjustable actuation or rapid trigger mode. That’s probably not a dealbreaker for most people, but the people who would use those features are the kind of hardcore gamers Logitech is targeting with this device.
Logitech
What is here is a new remapping system called “Keycontrol.” Through G Hub, this allows you to assign several different commands or macros to each key, with three separate control layers. This is a convenient way to get around some of the design’s missing keys: I made it so holding Alt temporarily turns WASD into arrow keys, for example. But it also lets you base different actions on whether you press, hold or release a key, so you could tie complementary actions in a game — casting a couple of buffs in an RPG, perhaps — to one press. Some of the analog keyboards noted above can work like this, too, and you need to have G Hub open for some bindings to stay active. Still, it’s better to have this sort of flexibility than not. Logitech says more of its keyboards will receive Keycontrol support in the future but declined to give more specific details.
All of this makes for a keyboard that’s solid in a vacuum but faces some stiff competition. Rival gaming keyboards like the Wooting 60HE+ and SteelSeries Apex Pro Mini Wireless are a little richer with performance-focused features, while a slightly larger option like the ASUS ROG Azoth sounds better and offers more customizable hardware for keyboard geeks. There are plenty of great non-gaming keyboards that cost much less, too. But the G Pro X 60 isn’t a bad choice if you want something compact and wireless, so it might be worthwhile during a sale.
This article originally appeared on Engadget at https://www.engadget.com/logitechs-tiny-g-pro-x-60-gaming-keyboard-has-some-big-competition-070154542.html?src=rss
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept”, you consent to the use of ALL the cookies.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checkbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.