STEPN distributes 100 million FSL Points to users. The airdrop aims to reward loyal community members and fuel engagement within the STEPN ecosystem. STEPN is also expected to announce a partnership with a leading global sports brand soon. According to a post on X, Move-to-earn lifestyle app, STEPN, has completed an extensive airdrop campaign, allocating […]
Image by author and ChatGPT. “Design an illustration, focusing on a basketball player in action, this time the theme is on using pyspark to generate features for machine leaning models in a graphic novel style” prompt. ChatGPT, 4, OpenAI, 4 April. 2024. https://chat.openai.com.
A Huge thanks to Martim Chaves who co-authored this post and developed the example scripts.
In our previous post we took a high level view of how to train a machine learning model in Microsoft Fabric. In this post we wanted to dive deeper into the process of feature engineering.
Feature engineering is a crucial part of the development lifecycle for any Machine Learning (ML) systems. It is a step in the development cycle where raw data is processed to better represent its underlying structure and provide additional information that enhance our ML models. Feature engineering is both an art and a science. Even though there are specific steps that we can take to create good features, sometimes, it is only through experimentation that good results are achieved. Good features are crucial in guaranteeing a good system performance.
As datasets grow exponentially, traditional feature engineering may struggle with the size of very large datasets. This is where PySpark can help — as it is a scalable and efficient processing platform for massive datasets. A great thing about Fabric is that it makes using PySpark easy!
In this post, we’ll be going over:
How does PySpark Work?
Basics of PySpark
Feature Engineering in Action
By the end of this post, hopefully you’ll feel comfortable carrying out feature engineering with PySpark in Fabric. Let’s get started!
How does PySpark work?
Spark is a distributed computing system that allows for the processing of large datasets with speed and efficiency across a cluster of machines. It is built around the concept of a Resilient Distributed Dataset (RDD), which is a fault-tolerant collection of elements that can be operated on in parallel. RDDs are the fundamental data structure of Spark, and they allow for the distribution of data across a cluster of machines.
PySpark is the Python API for Spark. It allows for the creation of Spark DataFrames, which are similar to Pandas DataFrames, but with the added benefit of being distributed across a cluster of machines. PySpark DataFrames are the core data structure in PySpark, and they allow for the manipulation of large datasets in a distributed manner.
At the core of PySpark is the SparkSession object, which is what fundamentally interacts with Spark. This SparkSession is what allows for the creation of DataFrames, and other functionalities. Note that, when running a Notebook in Fabric, a SparkSession is automatically created for you, so you don’t have to worry about that.
Having a rough idea of how PySpark works, let’s get to the basics.
Basics of PySpark
Although Spark DataFrames may remind us of Pandas DataFrames due to their similarities, the syntax when using PySpark can be a bit different. In this section, we’ll go over some of the basics of PySpark, such as reading data, combining DataFrames, selecting columns, grouping data, joining DataFrames, and using functions.
The Data
The data we are looking at is from the 2024 US college basketball tournaments, which was obtained from the on-going March Machine Learning Mania 2024 Kaggle competition, the details of which can be found here, and is licensed under CC BY 4.0 [1]
Reading data
As mentioned in the previous post of this series, the first step is usually to create a Lakehouse and upload some data. Then, when creating a Notebook, we can attach it to the created Lakehouse, and we’ll have access to the data stored there.
PySpark Dataframes can read various data formats, such as CSV, JSON, Parquet, and others. Our data is stored in CSV format, so we’ll be using that, like in the following code snippet:
In this code snippet, we’re reading the detailed results data set of the final women’s basketball college tournament matches. Note that the “header” option being true means that the names of the columns will be derived from the first row of the CSV file. The inferSchema option tells Spark to guess the data types of the columns – otherwise they would all be read as strings. .cache() is used to keep the DataFrame in memory.
If you’re coming from Pandas, you may be wondering what the equivalent of df.head() is for PySpark – it’s df.show(5). The default for .show() is the top 20 rows, hence the need to specifically select 5.
Combining DataFrames
Combining DataFrames can be done in multiple ways. The first we will look at is a union, where the columns are the same for both DataFrames:
# Combine (union) the DataFrames combined_results = m_data.unionByName(w_data)
Here, unionByName joins the two DataFrames by matching the names of the columns. Since both the women’s and the men’s detailed match results have the same columns, this is a good approach. Alternatively, there’s also union, which combines two DataFrames, matching column positions.
Selecting Columns
Selecting columns from a DataFrame in PySpark can be done using the .select() method. We just have to indicate the name or names of the columns that are relevant as a parameter.
Here’s the output for w_scores.show(5):
# Selecting a single column w_scores = w_data.select("WScore")
Grouping allows us to carry out certain operations for the groups that exist within the data and is usually combined with a aggregation functions. We can use .groupBy() for this:
# Grouping and aggregating winners_average_scores = winners.groupBy("TeamID").avg("Score")
In this example, we are grouping by “TeamID”, meaning we’re considering the groups of rows that have a distinct value for “TeamID”. For each of those groups, we’re calculating the average of the “Score”. This way, we get the average score for each team.
Here’s the output of winners_average_scores.show(5), showing the average score of each team:
Joining two DataFrames can be done using the .join() method. Joining is essentially extending the DataFrame by adding the columns of one DataFrame to another.
# Joining on Season and TeamID final_df = matches_df.join(stats_df, on=['Season', 'TeamID'], how='left')
In this example, both stats_df and matches_df were using Season and TeamID as unique identifiers for each row. Besides Season and TeamID, stats_df has other columns, such as statistics for each team during each season, whereas matches_df has information about the matches, such as date and location. This operation allows us to add those interesting statistics to the matches information!
Functions
There are several functions that PySpark provides that help us transform DataFrames. You can find the full list here.
In the code snippet above, a “HighScore” column is created when the score is higher than 80. For each row in the “Score” column (indicated by the .col() function), the value “Yes” is chosen for the “HighScore” column if the “Score” value is larger than 80, determined by the .when() function. .otherwise(), the value chosen is “No”.
Feature Engineering in Action
Now that we have a basic understanding of PySpark and how it can be used, let’s go over how the regular season statistics features were created. These features were then used as inputs into our machine learning model to try to predict the outcome of the final tournament games.
The starting point was a DataFrame, regular_data, that contained match by match statistics for the regular seasons, which is the United States College Basketball Season that happens from November to March each year.
Each row in this DataFrame contained the season, the day the match was held, the ID of team 1, the ID of team 2, and other information such as the location of the match. Importantly, it also contained statistics for each team for that specific match, such as “T1_FGM”, meaning the Field Goals Made (FGM) for team 1, or “T2_OR”, meaning the Offensive Rebounds (OR) of team 2.
The first step was selecting which columns would be used. These were columns that strictly contained in-game statistics.
# Columns that we'll want to get statistics from boxscore_cols = [ 'T1_FGM', 'T1_FGA', 'T1_FGM3', 'T1_FGA3', 'T1_OR', 'T1_DR', 'T1_Ast', 'T1_Stl', 'T1_PF', 'T2_FGM', 'T2_FGA', 'T2_FGM3', 'T2_FGA3', 'T2_OR', 'T2_DR', 'T2_Ast', 'T2_Stl', 'T2_PF' ]
If you’re interested, here’s what each statistic’s code means:
FGM: Field Goals Made
FGA: Field Goals Attempted
FGM3: Field Goals Made from the 3-point-line
FGA3: Field Goals Attempted for 3-point-line goals
OR: Offensive Rebounds. A rebounds is when the ball rebounds from the board when a goal is attempted, not getting in the net. If the team that attempted the goal gets possession of the ball, it’s called an “Offensive” rebound. Otherwise, it’s called a “Defensive” Rebound.
DR: Defensive Rebounds
Ast: Assist, a pass that led directly to a goal
Stl: Steal, when the possession of the ball is stolen
PF: Personal Foul, when a player makes a foul
From there, a dictionary of aggregation expressions was created. Basically, for each column name in the previous list of columns, a function was stored that would calculate the mean of the column, and rename it, by adding a suffix, “mean”.
from pyspark.sql import functions as F from pyspark.sql.functions import col # select a column
agg_exprs = {col: F.mean(col).alias(col + 'mean') for col in boxscore_cols}
Then, the data was grouped by “Season” and “T1_TeamID”, and the aggregation functions of the previously created dictionary were used as the argument for .agg().
Note that the grouping was done by season and the ID of team 1 — this means that “T2_FGAmean”, for example, will actually be the mean of the Field Goals Attempted made by the opponents of T1, not necessarily of a specific team. So, we actually need to rename the columns that are something like “T2_FGAmean” to something like “T1_opponent_FGAmean”.
# Rename columns for T1 for col in boxscore_cols: season_statistics = season_statistics.withColumnRenamed(col + 'mean', 'T1_' + col[3:] + 'mean') if 'T1_' in col else season_statistics.withColumnRenamed(col + 'mean', 'T1_opponent_' + col[3:] + 'mean')
At this point, it’s important to mention that the regular_data DataFrame actually has two rows per each match that occurred. This is so that both teams can be “T1” and “T2”, for each match. This little “trick” is what makes these statistics useful.
Note that we “only” have the statistics for “T1”. We “need” the statistics for “T2” as well — “need” in quotations because there are no new statistics being calculated. We just need the same data, but with the columns having different names, so that for a match with “T1” and “T2”, we have statistics for both T1 and T2. So, we created a mirror DataFrame, where, instead of “T1…mean” and “T1_opponent_…mean”, we have “T2…mean” and “T2_opponent_…mean”. This is important because, later on, when we’re joining these regular season statistics to tournament matches, we’ll be able to have statistics for both team 1 and team 2.
season_statistics_T2 = season_statistics.select( *[F.col(col).alias(col.replace('T1_opponent_', 'T2_opponent_').replace('T1_', 'T2_')) if col not in ['Season'] else F.col(col) for col in season_statistics.columns] )
Now, there are two DataFrames, with season statistics for “both” T1 and T2. Since the final DataFrame will contain the “Season”, the “T1TeamID” and the “T2TeamID”, we can join these newly created features with a join!
First created by Arpad Elo, Elo is a rating system for zero-sum games (games where one player wins and the other loses), like basketball. With the Elo rating system, each team has an Elo rating, a value that generally conveys the team’s quality. At first, every team has the same Elo, and whenever they win, their Elo increases, and when they lose, their Elo decreases. A key characteristic of this system is that this value increases more with a win against a strong opponent than with a win against a weak opponent. Thus, it can be a very useful feature to have!
We wanted to capture the Elo rating of a team at the end of the regular season, and use that as feature for the tournament. To do this, we calculated the Elo for each team on a per match basis. To calculate Elo for this feature, we found it more straightforward to use Pandas.
Central to Elo is calculating the expected score for each team. It can be described in code like so:
# Function to calculate expected score def expected_score(ra, rb): # ra = rating (Elo) team A # rb = rating (Elo) team B # Elo function return 1 / (1 + 10 ** ((rb - ra) / 400))
Considering a team A and a team B, this function computes the expected score of team A against team B.
For each match, we would update the teams’ Elos. Note that the location of the match also played a part — winning at home was considered less impressive than winning away.
# Function to update Elo ratings, keeping T1 and T2 terminology def update_elo(t1_elo, t2_elo, location, T1_Score, T2_Score): expected_t1 = expected_score(t1_elo, t2_elo) expected_t2 = expected_score(t2_elo, t1_elo)
# Determine K based on game location # The larger the K, the bigger the impact # team1 winning at home (location=1) less impressive than winning away (location = -1) if actual_t1 == 1: # team1 won if location == 1: k = 20 elif location == 0: k = 30 else: # location = -1 k = 40 else: # team2 won if location == 1: k = 40 elif location == 0: k = 30 else: # location = -1 k = 20
new_t1_elo = t1_elo + k * (actual_t1 - expected_t1) new_t2_elo = t2_elo + k * (actual_t2 - expected_t2)
return new_t1_elo, new_t2_elo
To apply the Elo rating system, we iterated through each season’s matches, initializing teams with a base rating and updating their ratings match by match. The final Elo available for each team in each season will, hopefully, be a good descriptor of the team’s quality.
def calculate_elo_through_seasons(regular_data):
# For this feature, using Pandas regular_data = regular_data.toPandas()
# Set value of initial elo initial_elo = 1500
# DataFrame to collect final Elo ratings final_elo_list = []
for season in sorted(regular_data['Season'].unique()): print(f"Season: {season}") # Initialize elo ratings dictionary elo_ratings = {}
print(f"Processing Season: {season}") # Get the teams that played in the season season_teams = set(regular_data[regular_data['Season'] == season]['T1_TeamID']).union(set(regular_data[regular_data['Season'] == season]['T2_TeamID']))
# Initialize season teams' Elo ratings for team in season_teams: if (season, team) not in elo_ratings: elo_ratings[(season, team)] = initial_elo
# Update Elo ratings per game season_games = regular_data[regular_data['Season'] == season] for _, row in season_games.iterrows(): t1_elo = elo_ratings[(season, row['T1_TeamID'])] t2_elo = elo_ratings[(season, row['T2_TeamID'])]
# Only keep the last season rating elo_ratings[(season, row['T1_TeamID'])] = new_t1_elo elo_ratings[(season, row['T2_TeamID'])] = new_t2_elo
# Collect final Elo ratings for the season for team in season_teams: final_elo_list.append({'Season': season, 'TeamID': team, 'Elo': elo_ratings[(season, team)]})
# Convert list to DataFrame final_elo_df = pd.DataFrame(final_elo_list)
# Separate DataFrames for T1 and T2 final_elo_t1_df = final_elo_df.copy().rename(columns={'TeamID': 'T1_TeamID', 'Elo': 'T1_Elo'}) final_elo_t2_df = final_elo_df.copy().rename(columns={'TeamID': 'T2_TeamID', 'Elo': 'T2_Elo'})
# Convert the pandas DataFrames back to Spark DataFrames final_elo_t1_df = spark.createDataFrame(final_elo_t1_df) final_elo_t2_df = spark.createDataFrame(final_elo_t2_df)
return final_elo_t1_df, final_elo_t2_df
Ideally, we wouldn’t calculate Elo changes on a match-by-match basis to determine each team’s final Elo for the season. However, we couldn’t come up with a better approach. Do you have any ideas? If so, let us know!
Value Added
The feature engineering steps demonstrated show how we can transform raw data — regular season statistics — into valuable information with predictive power. It is reasonable to assume that a team’s performance during the regular season is indicative of its potential performance in the final tournaments. By calculating the mean of observed match-by-match statistics for both the teams and their opponents, along with each team’s Elo rating in their final match, we were able to create a dataset suitable for modelling. Then, models were trained to predict the outcome of tournament matches using these features, among others developed in a similar way. With these models, we only need the two team IDs to look up the mean of their regular season statistics and their Elos to feed into the model and predict a score!
Conclusion
In this post, we looked at some of the theory behind Spark and PySpark, how that can be applied, and a concrete practical example. We explored how feature engineering can be done in the case of sports data, creating regular season statistics to use as features for final tournament games. Hopefully you’ve found this interesting and helpful — happy feature engineering!
The full source code for this post and others in the series can be found here.
This blog post is co-written with Caroline Chung from Veoneer. Veoneer is a global automotive electronics company and a world leader in automotive electronic safety systems. They offer best-in-class restraint control systems and have delivered over 1 billion electronic control units and crash sensors to car manufacturers globally. The company continues to build on a […]
Preorder deals are in effect now on Samsung’s 2024 line of Bespoke intelligent appliances, discounting the smart home gear by up to $1,200. Plus, get free installation and haul away on qualifying items.
Save up to $1,200 on Samsung’s new Bespoke AI appliances.
Tired of moving your laundry from the washer to the dryer? Samsung’s 2024 Bespoke AI Laundry Combo eliminates the need to transfer loads, saving you time and space.
And now the all-in-one laundry combo is on sale for $2,199, a discount of $1,100. The Bespoke AI Laundry Combo installs easily with a 120V standard outlet — and no dryer vent exhaust system is needed. You must have water lines and a drain hose installed where the unit is placed.
Apple has been having no luck arguing against the EU’s Digital Markets Act, and it’s paid the price in fines and forced changes to its App Store — so now it’s looking for a European head of PR.
Apple logo superimposed on a European Union flag
It perhaps says a lot about Apple’s success in promoting itself across Europe that it’s not been possible to confirm that the Head of Corporate PR role is actually new. Even in a famously secretive company, the issue of who runs PR shouldn’t be a mystery.
And there have definitely been people in charge, they just don’t appear to have had this particular title. Tanya Ridd, for instance, was reportedly Apple’s head of PR for north and south Europe, which you’d think would just mean Europe.
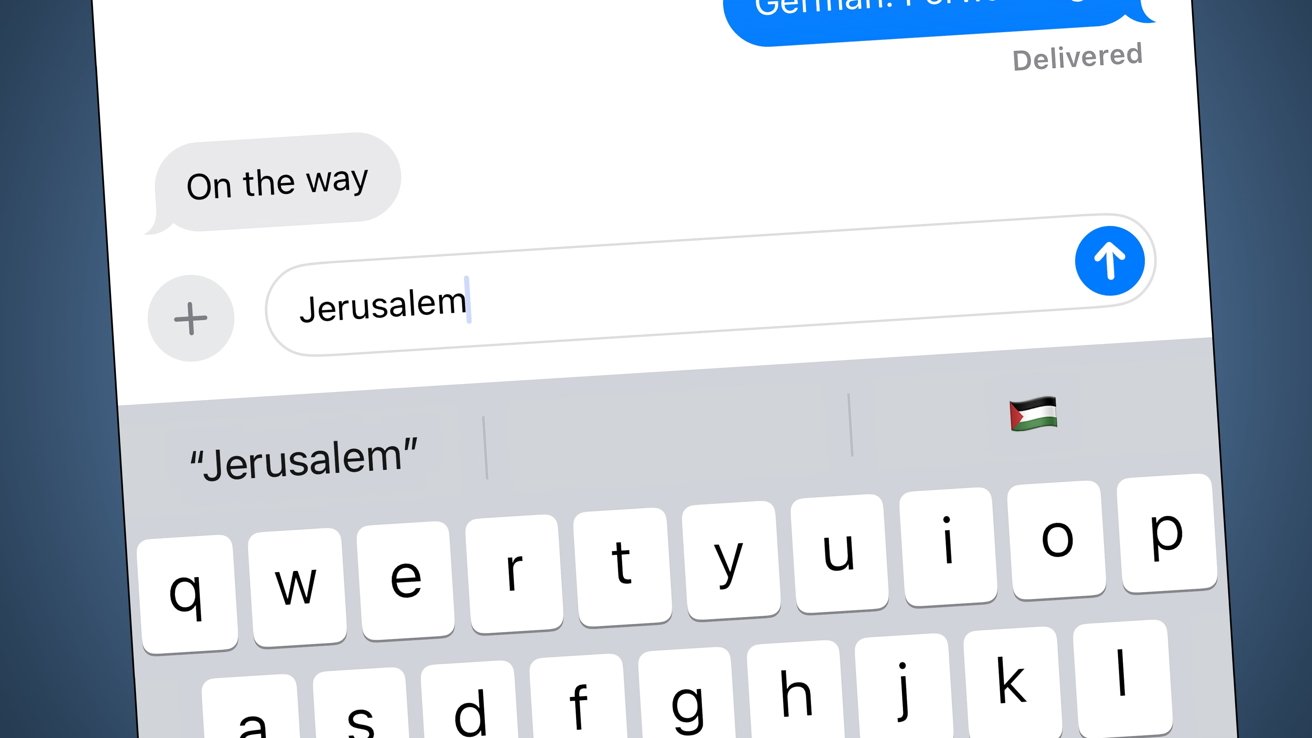
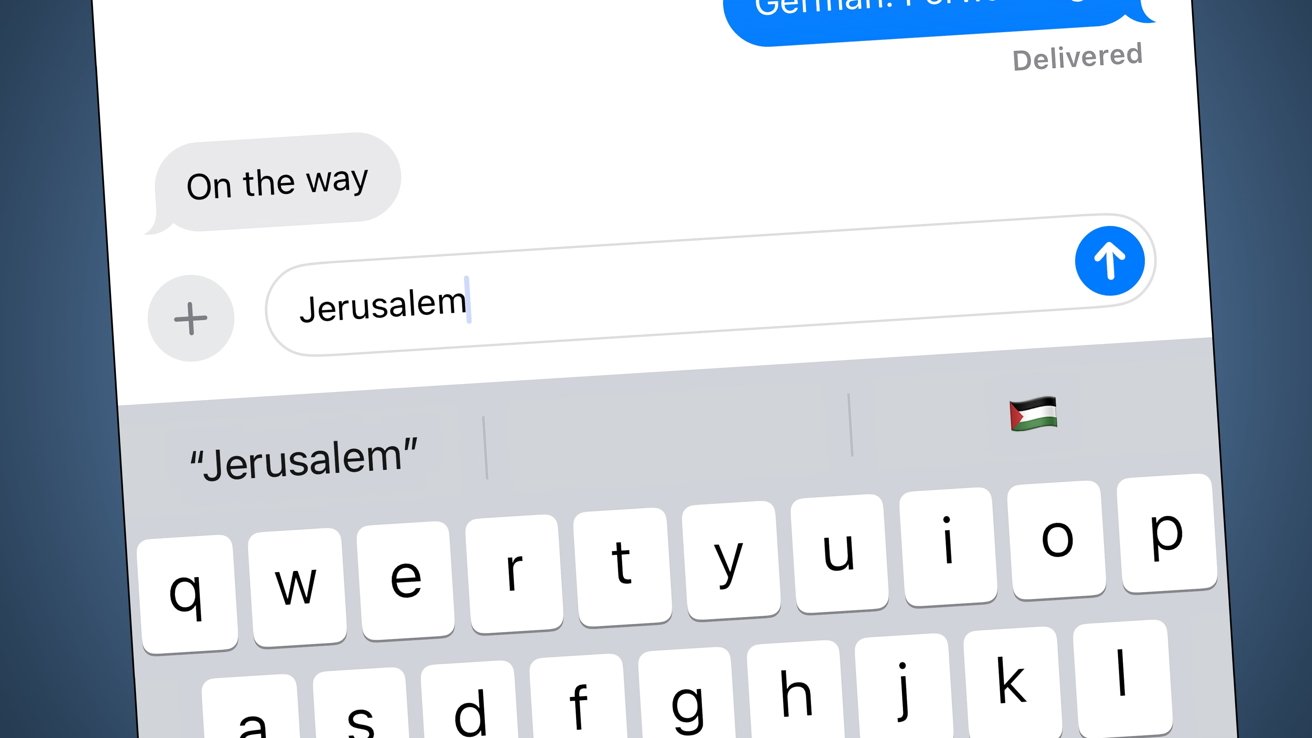
Apple’s predictive text system has prompted claims of antisemitism against the iPhone maker, by serving the Palestinian flag after users type in Jerusalem.
An example of the Palestinian flag showing as a predictive text suggestion for Jerusalem in iMessage
Apple’s latest software update to iOS 17, bringing it to iOS 17.4.1, has seemingly introduced a change to the autocorrect system. A change that some social media users are using to criticize the company with allegations of antisemitism.
For some users of iOS, typing in Jerusalem brings up the Palestinian flag as an optional emoji to add in iMessage. The problem isn’t limited to the predictive text system, as searching for the city under the emoji search comes up with the same result.
Apple Music emerges as the top choice for HomePod users — with Spotify also very strong on the platform.
Is Amazon Music evidence of a monopoly?
Recent research from Consumer Intelligence Research Partners (CIRP) has shed light on the competitive music streaming hardware landscape. It reveals that Amazon’s in-house music services, Prime Music and Amazon Music Unlimited, are gaining significant traction.
The popularity of Amazon Music, however, raises concerns about fair competition, as roughly one-third of consumers use Amazon Prime Music. Meanwhile, 14% opt for Amazon Music Unlimited, potentially impacting the market share of rivals like Apple Music, Spotify, and Google’s YouTube Music.
Amazon has decided to cut off paid perks for Alexa developers. The company confirmed to Engadget on Wednesday that it will end the Alexa Developer Rewards Program at the end of June. A second program that rewards developers for using Amazon Web Services as the backend for their Alexa apps will wrap up at the same time.
Amazon described the move as a case of phasing out an old project that had run its course. “These are older programs launched back in 2017 as a way to help newer developers interested in building skills accelerate their progress,” an Amazon spokesperson wrote to Engadget. “Today, there are over 160,000 skills available for customers, a well-established Alexa developer community, and new LLM-powered tools that will help developers build new experiences for Alexa. These older programs have simply run their course, so we decided to sunset them.”
The company told me the program launched when developers were still learning to make voice apps, and it was designed to help them get started. Amazon told Engadget that fewer than one percent of developers were using the program. It said Alexa developers will still get paid for in-app purchases from their Alexa skills, adding that the cost of making them has gone down while developer knowledge has gone up.
The Alexa Developer Rewards Program was created to incentivize developers who made high-quality skills for the assistant. Launched in 2017, when Alexa was all the rage, the program paid developers bonuses for skills that met engagement thresholds in specific categories. It was part of Amazon’s quest to turn Alexa Skills into a booming app store for a new generation of voice-first devices, a vision that never fully came to fruition.
Now, the renewed interest in AI assistants is about generative AI, which can handle many of the same tasks as Alexa’s skills (likely much better in some cases). At its fall 2023 devices event, Amazon previewed a next-generation version of Alexa with ChatGPT-like generative AI abilities. The company has also gradually integrated the next-gen tech into its seller tools and product pages.
Bloomberg reports that third-party apps weren’t making Amazon much money (unsurprising, given today’s news). The company cut the available funds for Alexa developer payments in 2020. Amazon also laid off several hundred employees in its Alexa division late last year. Meanwhile, Google threw in the towel long ago: It eliminated third-party voice apps for Google Assistant altogether in 2022.
This article originally appeared on Engadget at https://www.engadget.com/amazon-will-stop-paying-bonuses-to-alexa-developers-171610161.html?src=rss
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept”, you consent to the use of ALL the cookies.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checkbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.