How many new Web3 solutions have you encountered recently? What was their value proposition? Most likely it was transaction scalability, fee reduction, speed optimization, or a new token for yet another payment system. It almost seems that the blockchain industry is stuck in a Groundhog Day of exclusively solving a single task: transferring currency from […]
How to Make the Most Out of LLM Production Data: Simulated User Feedback
A novel approach to use production data to simulate user feedback for testing and evaluating your LLM app
Image by author and ChatGPT. “Image of two llamas, one with a thumbs up and another with thumbs down” prompt. ChatGPT, 4, OpenAI, April 10th 2024. https://chat.openai.com.
A series of blog posts to share our perspectives on how to evaluate and improve your GenAI application pipelines
(written by Pasquale Antonante and Yi Zhang at Relari.ai)
The world of LLM app development is always on the move — new tricks, models, and apps pop up every week. As tech gets better, what users expect keeps ramping up. Staying ahead in this game is key to making sure it’s the one users keep coming back to.
The problem now becomes: how do you measure performance improvements? When you’re fiddling with prompts, tweaking the temperature, or switching up models, do you ever pause and think, “Will my users actually like this more?
In this post, we’ll walk through how in-app user feedback from earlier deployments (or internal human evaluation) can be instrumental in quickly shaping future versions of a product. We’ll discuss the limitations of traditional feedback mechanisms and introduce a new technique that allows AI developers to use feedback data directly in offline testing and iterations (before a new deployment), making the development cycle more adaptable and responsive to user preferences.
Understanding the Value of User Feedback
Why User Feedback Matters and Its Challenges
When developing LLM-based applications, we are often faced with a particular problem we want to address, e.g., a specific type of question has a low accuracy. As we experiment with tweaks in prompts, parameters, architecture, etc., we want to evaluate performance of the new pipeline, in particular whether users will like the new version(s) of your AI application. The most straightforward way is to A/B test each change with the end users and collect their feedback data such as thumbs up / down, score rating, or written comments, but practically it is challenging for a few reasons:
Slow to collect: Unless your application is already seeing huge volume, you don’t have that much feedback data. Anecdotally, we’ve seen the feedback participation rate in our customers’ AI applications range from <1% (normal) to ~10% (exceptional, often through deliberate UI/UX design to encourage more feedback). As a result, it can take a long time before you get enough feedback data to make a statistically confident judgment of whether a particular change resonated positively or negatively with your users.
Risk of jeopardizing user relationships: Testing directly with users is the most effective way to gain insights, but there’s a real risk of damaging your relationship with them if they encounter an unsatisfactory version. Users can be quick to judge, potentially dismissing your application at the first sign of a mistake. Consequently, developers tend to opt for more conservative or less disruptive changes for A/B testing with users, reserving the bolder, more innovative updates for internal testing. This approach allows for experimentation while minimizing the risk of alienating the user base.
Inconsistent measurement: With most AI applications being fairly open-ended, it is often difficult to get truly apples-to-apples comparison of feedback data given different users can interact with your product in a different way. As a result, feedback data A/B testing for LLM-based applications tends to be more noisy than those from traditional applications.
In the next section, we’ll introduce a novel approach that we’ve deployed to multiple customers to help them make the most out of their user feedback data in offline development.
A Novel Approach: Simulate User Feedback
In response to these challenges in collecting user feedback, we have developed a novel approach to simulate user feedback using a small sample of user (or internally labeled) feedback data. Specifically, we use metric ensembling and conformal prediction to learn user preferences and use them offline during the development phase. At its core, we learn how users weigh different criteria (e.g., tone, conciseness, etc) and leverage conformal prediction to provide predictions to quantify confidence. This method drastically accelerates LLM app development by providing a way to anticipate how users might react to new features or changes before they are fully implemented.
To evaluate its effectiveness, we compared this approach with the more conventional one of using a single LLM call that assesses different aspects of the response to make a judgment. To compare the two alternatives (the proposed approach vs. the single LLM call), we conducted an experiment using the Unified-Feedback dataset. We generated many potential …..We used Kendall’s tau, a measure of rank correlation, to compare the rankings produced by our user feedback simulation and the single LLM call approach against the ground truth established by human evaluations. This analysis allows us to assess not only the degree of agreement, but also the order of preference that each method predicts compared to the human rankings.
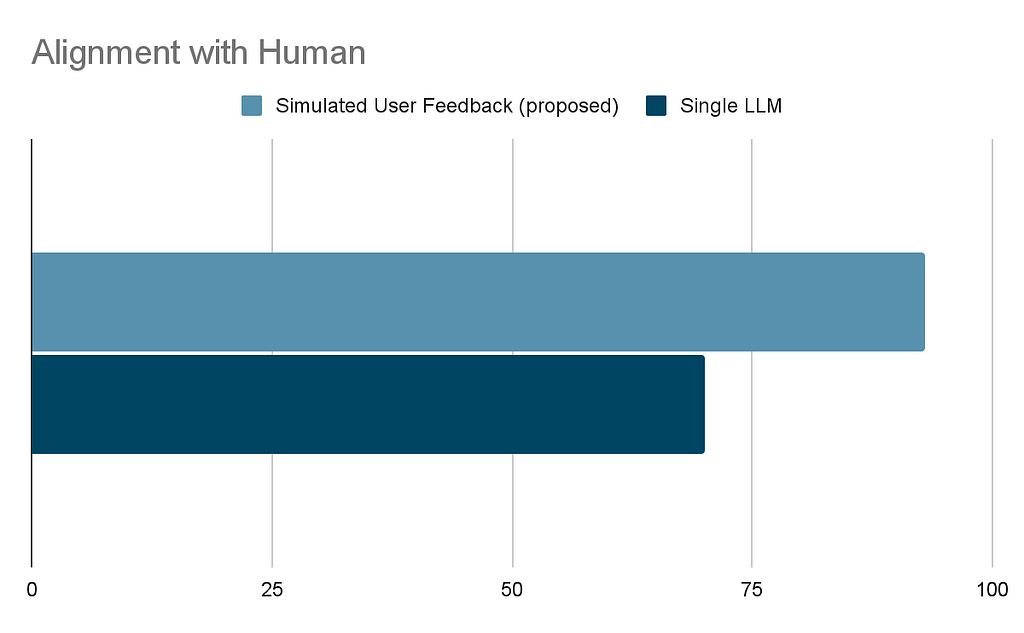
Our experiment revealed that the user feedback simulation has a correlation of 93% that significantly exceeded that of the single LLM call approach, which attains roughly 70% correlation. This indicates that, in terms of ranking , the simulated user feedback simulation provides a closer approximation to human judgment.
Kendall’s tau of the two methods. Higher values indicate a stronger correlation between the ranking produced by the method and the human. Simulated User Feedback (proposed, lighter blue) shows higher agreement with humans when tasked with identifying improvements, suggesting that it more accurately reflects human judgment in identifying and evaluating improvements. Image by the author.
The reason why the simulated user feedback performs better is twofold:
it learns from actual user feedback the importance of different criteria, making the approach custom to your use case
while individual criteria may have appeared in the LLM training set, the complex (and potentially large) set of different criteria likely have not appeared in the training data, making it more difficult for the LLM evaluator to get right.
While single LLM calls can identify major improvements in the pipeline, they fall short of detecting the more frequent, minor enhancements critical in mature pipelines. Simulated user feedback, however, exhibits a high correlation with human judgment, enabling the detection of these incremental advances.
As a side note, while we could have used the data to fine-tune an LLM, this has the typical drawback of requiring more data and not being as interpretable.
In the next section, we will walk through an example on how to create your simulated user feedback.
How It Works
In this section we will show how we can use the open-source library continuous-eval to create simulated user feedback.
Consider a Q&A chatbot application. After deployment, users begin rating responses with thumbs up or down, indicating a need for performance enhancement. For this example we will use the example named correctness in continuous-eval:
# Samples are annotated with "correct", "incorrect" or "refuse-to-answer" # We remove the samples where the LLL refused to answer (i.e., said "I don't know") dataset.filter(lambda x: x["annotation"] != "refuse-to-answer") dataset.sample(300) # Only for this example: randomly sample 300 examples
As we mentioned, we want to create some custom criteria. We leverage the LLMBasedCustomMetric class to define the Tone and Conciseness metrics. To do so we need to define the metric and provide a scoring rubric.
For the tone:
tone = LLMBasedCustomMetric( name="Tone", definition="The Tone/Content Issues metric evaluates the appropriateness and accuracy of the tone and content in responses to specific questions. It focuses on ensuring that the tone is professional and suitable for the context, and that the content accurately addresses the question without unnecessary deviations or inaccuracies. This metric is crucial for maintaining a professional image and ensuring clear, direct communication.", scoring_rubric="""Use the following rubric to assign a score to the answer based on its tone: - Score 1: The response is inappropriate or inaccurate, with a tone that is either too informal, overly strong, or not suited to the professional context. The content may be irrelevant, incorrect, or fail to directly address the question posed. - Score 2: The response is mostly appropriate and accurate but may contain minor tone or content issues. The tone is generally professional but may slip into informality or unnecessary strength in places. The content addresses the question but may include minor inaccuracies or unnecessary details. - Score 3: The response is appropriate and accurate, with a tone that is professional and suited to the context. The content directly and correctly addresses the question without unnecessary deviations or inaccuracies.""", scoring_function=ScoringFunctions.Numeric(min_val=1, max_val=3), model_parameters={"temperature": 0}, )
while for conciseness:
conciseness = LLMBasedCustomMetric( name="Conciseness", definition="Conciseness in communication refers to the expression of ideas in a clear and straightforward manner, using the fewest possible words without sacrificing clarity or completeness of information. It involves eliminating redundancy, verbosity, and unnecessary details, focusing instead on delivering the essential message efficiently. ", scoring_rubric="""Use the following rubric to assign a score to the answer based on its conciseness: - Score 1: The answer is overly verbose, containing a significant amount of unnecessary information, repetition, or redundant expressions that do not contribute to the understanding of the topic. - Score 2: The answer includes some unnecessary details or slightly repetitive information, but the excess does not severely hinder understanding. - Score 3: The answer is clear, direct, and to the point, with no unnecessary words, details, or repetition.""", scoring_function=ScoringFunctions.Numeric(min_val=1, max_val=3), model_parameters={"temperature": 0}, )
We use Tone and Conciseness together with more standard metrics, in particular we will consider the
Answer Correctness (DeterministicAnswerCorrectens and LLMBasedAnswerCorrectness)
Answer Relevance (LLMBasedAnswerRelevance)
Style Consistency (LLMBasedStyleConsistency)
Readability (FleschKincaidReadability)
The next step is to put all the metrics together and specify what field of the dataset should be used to compute the metrics. To do that we can use the SingleModulePipeline
and run all the metrics using the EvaluationManager
eval_manager = EvaluationManager(pipeline) # The dataset already contains the model output so we just set the evaluation results eval_manager.evaluation.results = dataset.data eval_manager.run_metrics() # Note: there is no progress bar, it might take a few minutes
The next step is to train simulated user feedback predictor
datasplit = DataSplit( X=eval_manager.metrics.to_pandas(), y=map(lambda x: 1 if x == "correct" else 0, dataset["annotation"]), split_ratios=SplitRatios(train=0.6, test=0.2, calibration=0.2), )
# We use the train and calibration sets to train the classifier predictor = EnsembleMetric(training=datasplit.train, calibration=datasplit.calibration)
This simulated user feedback predictor is able to correctly predict the human feedback in the test split 96.67% of the time.
We can leverage the proposed approach to better understand what is important to the user. Below is the learned importance of every metric by the simulated user feedback predictor.
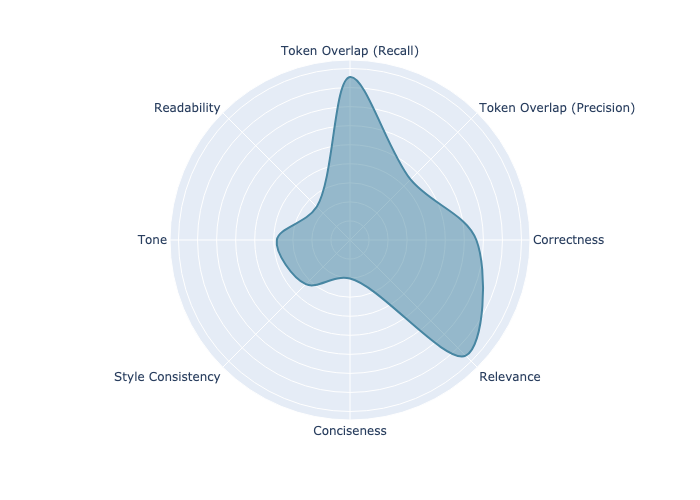
Learned importance of every metric by the simulated user feedback predictor. Image by the author.
Looking at the plot, we see that Correctness (including token overlap, which is another measure for correctness) and Relevance to the question are the most important predictors of user preference. But the user also weighs tone and style consistency into the decision. At the same time, we can see that conciseness and readability are not as important. Reviewing this graph provides valuable insight into user preferences, giving a clear indication of what elements are essential and what can be adjusted if compromises need to be made.
Wrapping Up
Collecting user feedback is challenging, yet it is the most important information for developers of large language models (LLMs). By simulating user feedback during offline testing, we significantly reduces the time it takes for feedback to travel from the field back to developers, while maintaining positive user relationships.
In practice, our approach has proven to closely mirror actual human responses, outperforming traditional methods that rely on isolated LLM responses. This strategy allows for the incremental improvement of generative AI applications, fostering continuous refinement and greater congruence with what users expect.
—
Note: We will soon publish a research paper with more details on this methodology. Stay tuned!
No matter what you use your Mac for, there may come a time when Command + Q just doesn’t cut it. For closing out those persistently frozen apps that just won’t go away, there are a couple of ways to get the job done.
For those apps that just won’t close, sometimes you need a little Force.
The primary two methods for getting rid of an app that just won’t go away come down to Force Quit and Activity Monitor. Both options will get the job done in almost any use case you may need to use either for and will go that extra step beyond simply quitting the app in question.
Blizzard is taking mid-match leaves on Overwatch 2 more seriously and is implementing harsher punishments when Season 10 arrives. People playing Unranked games won’t be able to join a queue for five minutes after leaving two of their last 20 games. And if they leave at least 10 out of the last 20, they’ll be suspended for 48 hours. Players probably want to be even more careful when it comes to leaving Competitive games, though, because doing so 10 times out of 20 will get them banned for the rest of the season. In its announcement, Blizzard said that while it’s aware not everyone abandons a game on purpose, these changes “should help curb those players who deliberately choose to leave a match.”
Blizzard
The developer is also making it easier for groups of friends to play together in Competitive mode, no matter their rank, by introducing “wide groups.” A wide group is defined by having players from a wide range of ranks, from Diamond to tiers up to five Skill Divisions lower. Blizzard admits that opting for the new queue option will mean longer wait times, since it has to pair a wide group with another wide group with similar ranks in order to be fair. But it’s hoping that the new feature will eliminate the need to use an alt account when playing with friends.
The company is also adding new features designed to help prevent abuse and harassment in-game. People will soon be able to add up to 10 players in their “Avoid as Teammate” list instead of just three. It’s also making it easy to report disruptive behavior by updating its reporting interface. Finally, Blizzard is blocking a player’s access to text or voice chat in their matches if they were found to have engaged in abusive behavior and have broken the company’s code of conduct. They can only get those privileges back if they spend time playing Overwatch 2 in their best behavior.
This article originally appeared on Engadget at https://www.engadget.com/overwatch-2-introduces-harsher-punishments-for-players-who-leave-mid-match-021319507.html?src=rss
Quick Take The latest US inflation data has surprised analysts, with headline inflation year-over-year (YoY) coming in at 3.5% — 0.1% above forecasts. The development is significant considering the Federal Reserve’s most aggressive hiking cycle in decades, according to Statista, which aimed to tame the rampant inflation that the central bank initially claimed was transitory. […]
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept”, you consent to the use of ALL the cookies.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checkbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.