Victoria, Seychelles, April 12th, 2024, Chainwire Bitget, a world-leading cryptocurrency exchange and Web3 platform, is excited to announce the launch of its latest feature, Pre-market. This new feature aims to meet the demand for pre-listing trading of the latest tokens and enhance the liquidity and trading experience for users. The first supported token on the […]
The overall proportion of total illicit crypto funds is shrinking by 9% on a year-on-year basis, although bad actors still handled over $34 billion in 2023. The total volume of illicit crypto funds decreased by nearly one-third in 2023, according…
USDT’s reserves on Tron accounted for more than 52% of its total circulating supply.
USDT and Tron have gained notoriety in the past for links to terrorism.
Aptos teams up with io.net to broaden AI access, enhancing blockchain applications. Meanwhile, analysts foresee a parabolic surge for Cardano, with the gaming token NuggetRush also expected to reach impressive heights. #partnercontent
Amid the search for promising low-cost cryptocurrencies, Cardano (ADA), Tron (TRX), and KangaMoon (KANG) emerge as frontrunners, with analysts highlighting KangaMoon’s potential to hit $1 in 2024. #sponsored
MarginFi, a popular lending platform on Solana, witnessed a massive number of withdrawals.
Despite the rise in negative sentiment, the overall state of Solana remained fine.
Explore the details behind the power of transformers
There has been a new development in our neighborhood.
A ‘Robo-Truck,’ as my son likes to call it, has made its new home on our street.
It is a Tesla Cyber Truck and I have tried to explain that name to my son many times but he insists on calling it Robo-Truck. Now every time I look at Robo-Truck and hear that name, it reminds me of the movie Transformers where robots could transform to and from cars.
And isn’t it strange that Transformers as we know them today could very well be on their way to powering these Robo-Trucks? It’s almost a full circle moment. But where am I going with all these?
Well, I am heading to the destination — Transformers. Not the robot car ones but the neural network ones. And you are invited!
Image by author (Our Transformer — ‘Robtimus Prime’. Colors as mandated by my artist son.)
What are Transformers?
Transformers are essentially neural networks. Neural networks that specialize in learning context from the data.
But what makes them special is the presence of mechanisms that eliminate the need for labeled datasets and convolution or recurrence in the network.
What are these special mechanisms?
There are many. But the two mechanisms that are truly the force behind the transformers are attention weighting and feed-forward networks (FFN).
What is attention-weighting?
Attention-weighting is a technique by which the model learns which part of the incoming sequence needs to be focused on. Think of it as the ‘Eye of Sauron’ scanning everything at all times and throwing light on the parts that are relevant.
Fun-fact: Apparently, the researchers had almost named the Transformer model ‘Attention-Net’, given Attention is such a crucial part of it.
What is FFN?
In the context of transformers, FFN is essentially a regular multilayer perceptron acting on a batch of independent data vectors. Combined with attention, it produces the correct ‘position-dimension’ combination.
How do Attention and FFN work?
So, without further ado, let’s dive into how attention-weighting and FFN make transformers so powerful.
This discussion is based on Prof. Tom Yeh’s wonderful AI by Hand Series on Transformers . (All the images below, unless otherwise noted, are by Prof. Tom Yeh from the above-mentioned LinkedIn posts, which I have edited with his permission.)
So here we go:
The key ideas here : attention weighting and feed-forward network (FFN).
Keeping those in mind, suppose we are given:
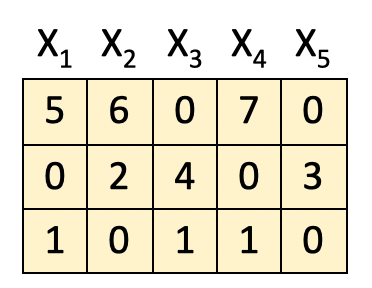
5 input features from a previous block (A 3×5 matrix here, where X1, X2, X3, X4 and X5 are the features and each of the three rows denote their characteristics respectively.)
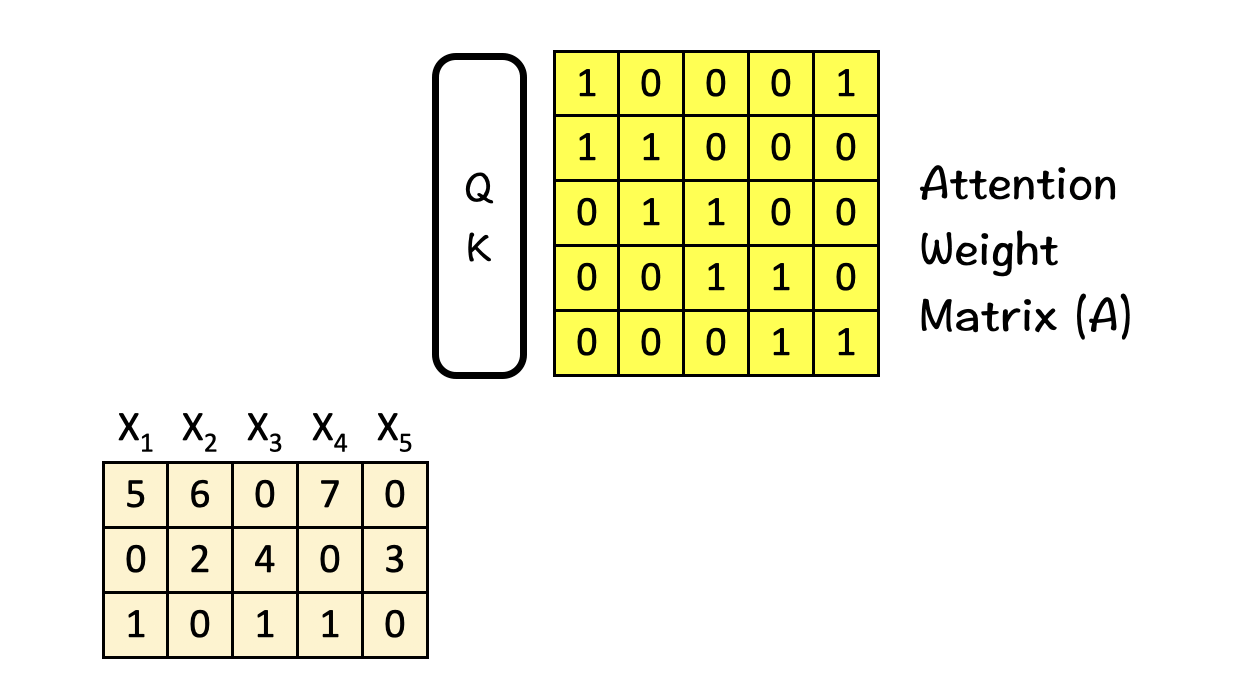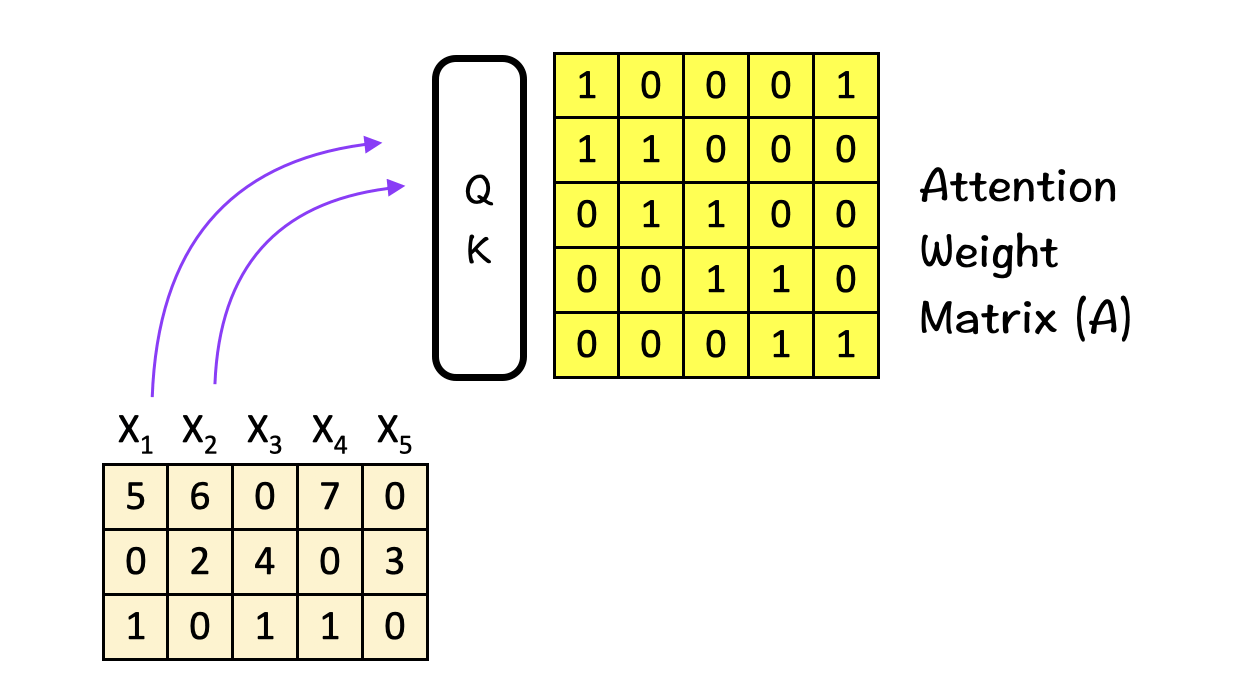
[1] Obtain attention weight matrix A
The first step in the process is to obtain the attention weight matrix A. This is the part where the self-attention mechanism comes to play. What it is trying to do is find the most relevant parts in this input sequence.
We do it by feeding the input features into the query-key (QK) module. For simplicity, the details of the QK module are not included here.
[2] Attention Weighting
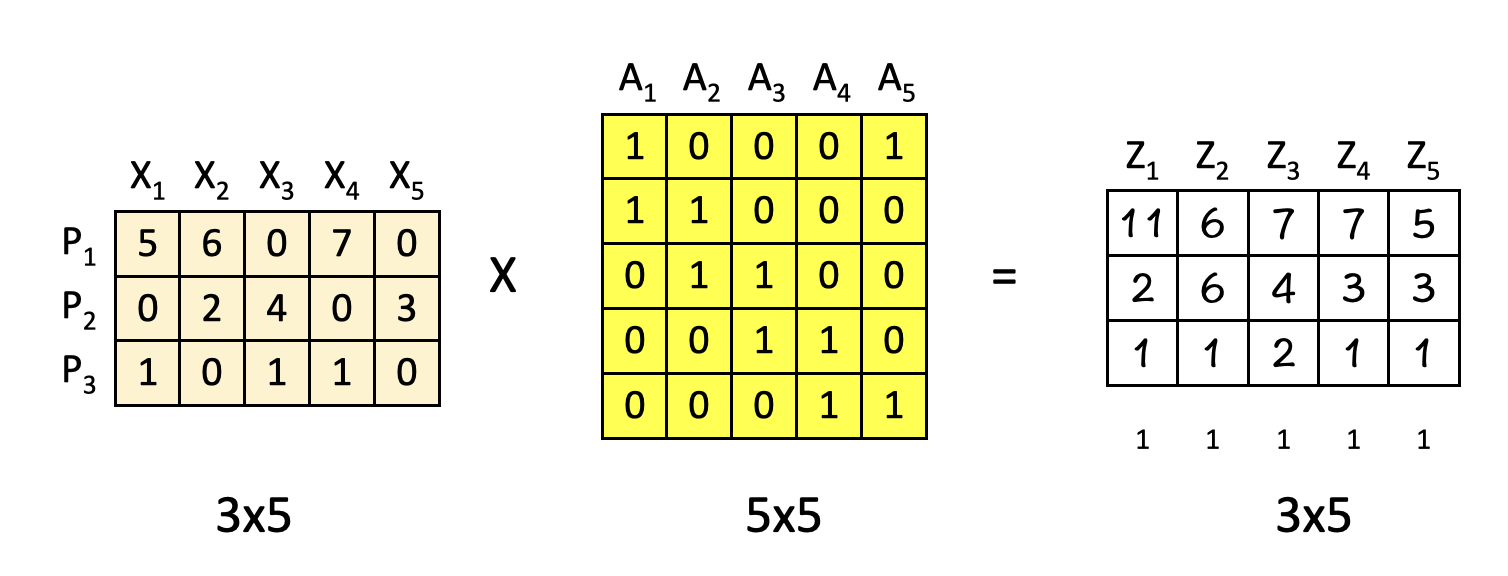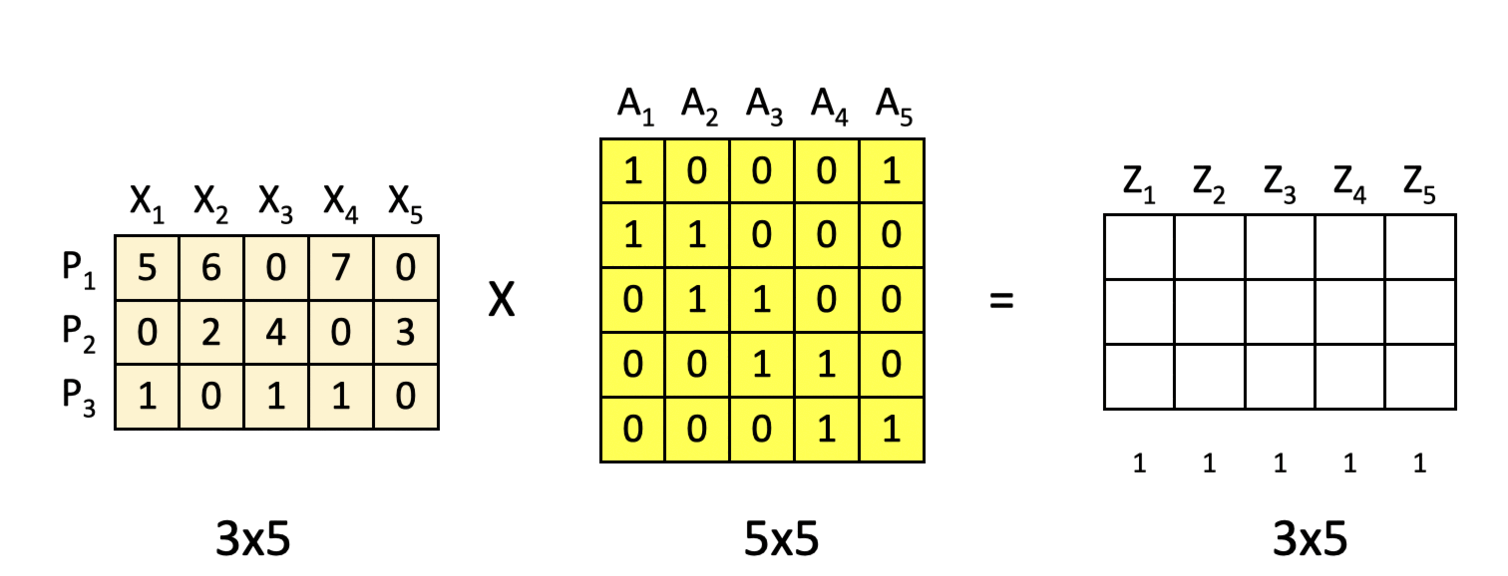
Once we have the attention weight matrix A (5×5), we multiply the input features (3×5) with it to obtain the attention-weighted features Z.
The important part here is that the features here are combined based on their positions P1, P2 and P3 i.e. horizontally.
To break it down further, consider this calculation performed row-wise:
P1 X A1 = Z1 → Position [1,1] = 11
P1 X A2 = Z2 → Position [1,2] = 6
P1 X A3 = Z3 → Position [1,3] = 7
P1 X A4 = Z4 → Position [1,4] = 7
P1 X A5 = Z5 → Positon [1,5] = 5
.
.
.
P2 X A4 = Z4 → Position [2,4] = 3
P3 X A5 = Z5 →Position [3,5] = 1
As an example:
It seems a little tedious in the beginning but follow the multiplication row-wise and the result should be pretty straight-forward.
Cool thing is the way our attention-weight matrix A is arranged, the new features Z turn out to be the combinations of X as below:
Z1 = X1 + X2
Z2 = X2 + X3
Z3 = X3 + X4
Z4 = X4 + X5
Z5 = X5 + X1
(Hint : Look at the positions of 0s and 1s in matrix A).
[3] FFN : First Layer
The next step is to feed the attention-weighted features into the feed-forward neural network.
However, the difference here lies in combining the values across dimensions as opposed to positions in the previous step. It is done as below:
What this does is that it looks at the data from the other direction.
– In the attention step, we combined our input on the basis of the original features to obtain new features.
– In this FFN step, we consider their characteristics i.e. combine features vertically to obtain our new matrix.
Eg: P1(1,1) * Z1(1,1)
+ P2(1,2) * Z1 (2,1)
+ P3 (1,3) * Z1(3,1) + b(1) = 11, where b is bias.
Once again element-wise row operations to the rescue. Notice that here the number of dimensions of the new matrix is increased to 4 here.
[4] ReLU
Our favorite step : ReLU, where the negative values obtained in the previous matrix are returned as zero and the positive value remain unchanged.
[5] FFN : Second Layer
Finally we pass it through the second layer where the dimensionality of the resultant matrix is reduced from 4 back to 3.
The output here is ready to be fed to the next block (see its similarity to the original matrix) and the entire process is repeated from the beginning.
The two key things to remember here are:
The attention layer combines across positions (horizontally).
The feed-forward layer combines across dimensions (vertically).
And this is the secret sauce behind the power of the transformers — the ability to analyze data from different directions.
To summarize the ideas above, here are the key points:
The transformer architecture can be perceived as a combination of the attention layer and the feed-forward layer.
The attention layer combines the features to produce a new feature. E.g. think of combining two robots Robo-Truck and Optimus Prime to get a new robot Robtimus Prime.
The feed-forward (FFN) layer combines the parts or the characteristics of the a feature to produce new parts/characteristics. E.g. wheels of Robo-Truck and Ion-laser of Optimus Prime could produce a wheeled-laser.
The ever powerful Transformers
Neural networks have existed for quite some time now. Convolutional Neural Networks (CNN) and Recurrent Neural Networks (RNN) had been reigning supreme but things took quite an eventful turn once Transformers were introduced in the year 2017. And since then, the field of AI has grown at an exponential rate — with new models, new benchmarks, new learnings coming in every single day. And only time will tell if this phenomenal idea will one day lead the way for something even bigger — a real ‘Transformer’.
But for now it would not be wrong to say that an idea can really transform how we live!
Image by author
P.S. If you would like to work through this exercise on your own, here is the blank template for your use.
The NYT Mini crossword might be a lot smaller than a normal crossword, but it isn’t easy. If you’re stuck with today’s crossword, we’ve got answers for you here.
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept”, you consent to the use of ALL the cookies.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checkbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.