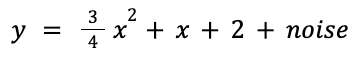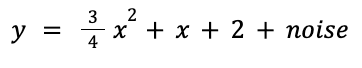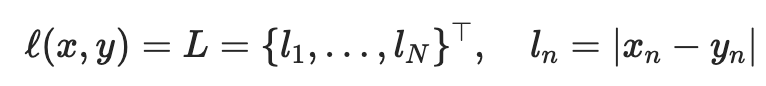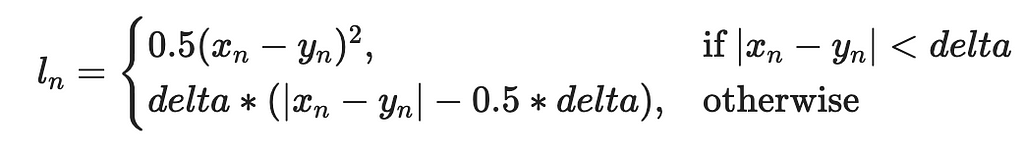Earlier on Monday, renowned crypto analyst highlighted on X the resemblance between the current price action of DOGE and patterns seen in its previous bull markets…
Prying behind the interface to see the effects of SGD parameters on your model training
Behind the simple interfaces of modern machine learning frameworks lie large amounts of complexity. With so many dials and knobs exposed to us, we could easily fall into cargo cult programming if we don’t understand what’s going on underneath. Consider the many parameters of Torch’s stochastic gradient descent (SGD) optimizer:
Besides the familiar learning rate lr and momentum parameters, there are several other that have stark effects on neural network training. In this article we’ll visualize the effects of these parameters on a simple ML objective with a variety of loss functions.
Toy Problem
To start we construct a toy problem of performing linear regression over a set of points. To make it interesting we’re going to use a quadratic function plus noise so that the neural network will have to make trade-offs—and we’ll also get to observe more of the impact of the loss functions:
We start off just using numpy and matplotlib to visualization our data—no torch required yet:
import numpy as np import matplotlib.pyplot as plt
np.random.seed(20240215) n = 50 x = np.array(np.random.randn(n), dtype=np.float32) y = np.array( 0.75 * x**2 + 1.0 * x + 2.0 + 0.3 * np.random.randn(n), dtype=np.float32)
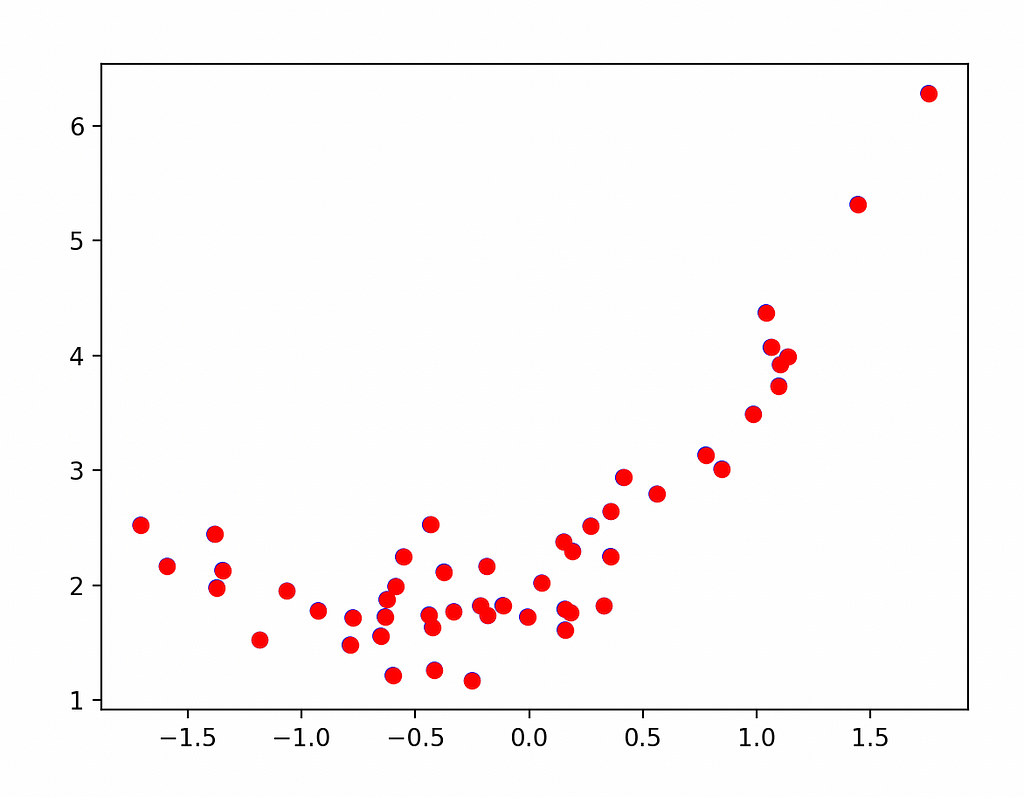
plt.scatter(x, y, facecolors='none', edgecolors='b') plt.scatter(x, y, c='r') plt.show()
Figure 1. Toy problem set of points.
Next we’ll break out the torch and introduce a simple training loop for a single-neuron network. To get consistent results when we vary the loss function, we’ll start our training from the same set of parameters each time with the neuron’s first “guess” being the equation y = 6*x — 3 (which we effect via the neuron’s weight and bias parameters):
import torch
model = torch.nn.Linear(1, 1) model.weight.data.fill_(6.0) model.bias.data.fill_(-3.0)
for epoch in range(epochs): inputs = torch.from_numpy(x).requires_grad_().reshape(-1, 1) labels = torch.from_numpy(y).reshape(-1, 1)
optimizer.zero_grad() outputs = model(inputs) loss = loss_fn(outputs, labels) loss.backward() optimizer.step() print('epoch {}, loss {}'.format(epoch, loss.item()))
Running this gives us text output that shows us the loss is decreasing, eventually down to a minimum, as expected:
epoch 0, loss 53.078269958496094 epoch 1, loss 34.7295036315918 epoch 2, loss 22.891206741333008 epoch 3, loss 15.226042747497559 epoch 4, loss 10.242652893066406 epoch 5, loss 6.987757682800293 epoch 6, loss 4.85075569152832 epoch 7, loss 3.4395809173583984 epoch 8, loss 2.501774787902832 epoch 9, loss 1.8742430210113525 ... epoch 97, loss 0.4994412660598755 epoch 98, loss 0.4994412362575531 epoch 99, loss 0.4994412660598755
To visualize our fit, we take the learned bias and weight out of our neuron and plot the fit against the points:
Figure 2. L2-learned linear boundary on toy problem.
Visualizing the Loss Function
The above seems a reasonable fit, but so far everything has been handled by high-level Torch functions like optimizer.zero_grad(), loss.backward(), and optimizer.step(). To understand where we’re going next, we’ll need to visualize the journey our model is taking through the loss function. To visualize the loss, we’ll sample it in a grid of 101-by-101 points, then plot it using imshow:
def get_loss_map(loss_fn, x, y): """Maps the loss function on a 100-by-100 grid between (-5, -5) and (8, 8).""" losses = [[0.0] * 101 for _ in range(101)] x = torch.from_numpy(x) y = torch.from_numpy(y) for wi in range(101): for wb in range(101): w = -5.0 + 13.0 * wi / 100.0 b = -5.0 + 13.0 * wb / 100.0 ywb = x * w + b losses[wi][wb] = loss_fn(ywb, y).item()
return list(reversed(losses)) # Because y will be reversed.
Now we can capture the model parameters while running gradient descent to show us how the optimizer is performing:
model = torch.nn.Linear(1, 1) ... models = [[model.weight.item(), model.bias.item()]] for epoch in range(epochs): ... print('epoch {}, loss {}'.format(epoch, loss.item())) models.append([model.weight.item(), model.bias.item()])
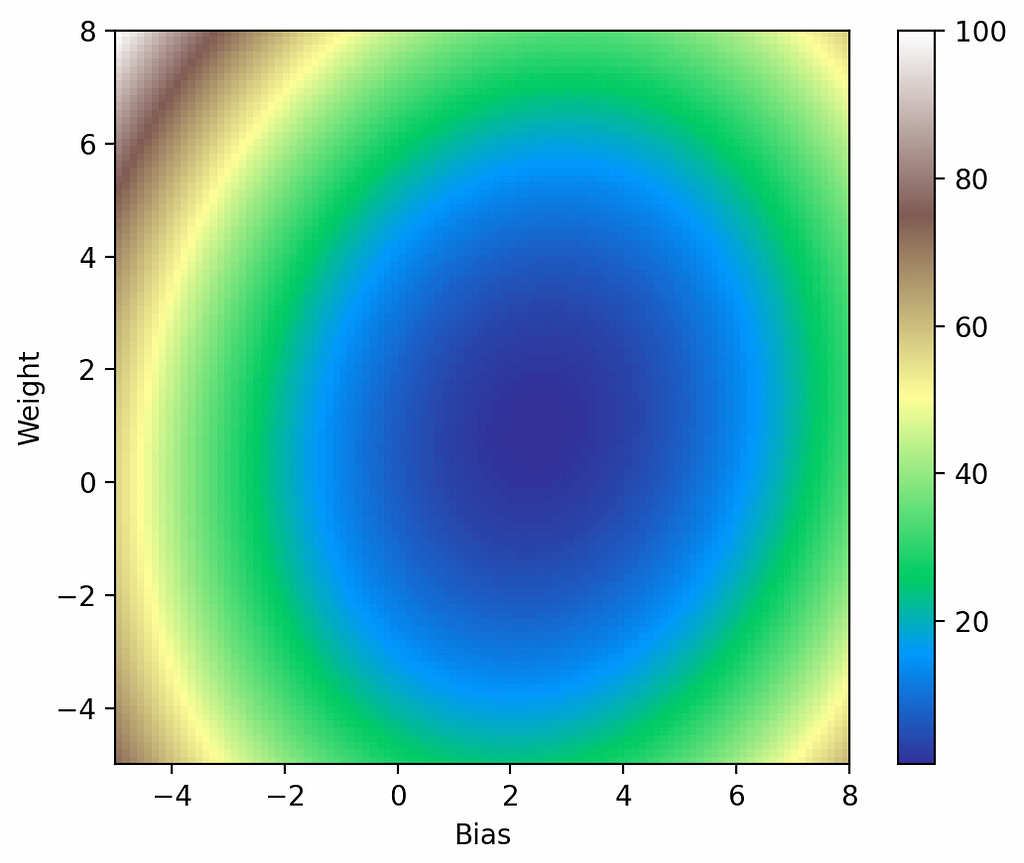
# Plot model parameters against the loss map. cm = pylab.get_cmap('terrain') fig, ax = plt.subplots() plt.xlabel('Bias') plt.ylabel('Weight') i = ax.imshow(losses, cmap=cm, interpolation='nearest', extent=[-5, 8, -5, 8])
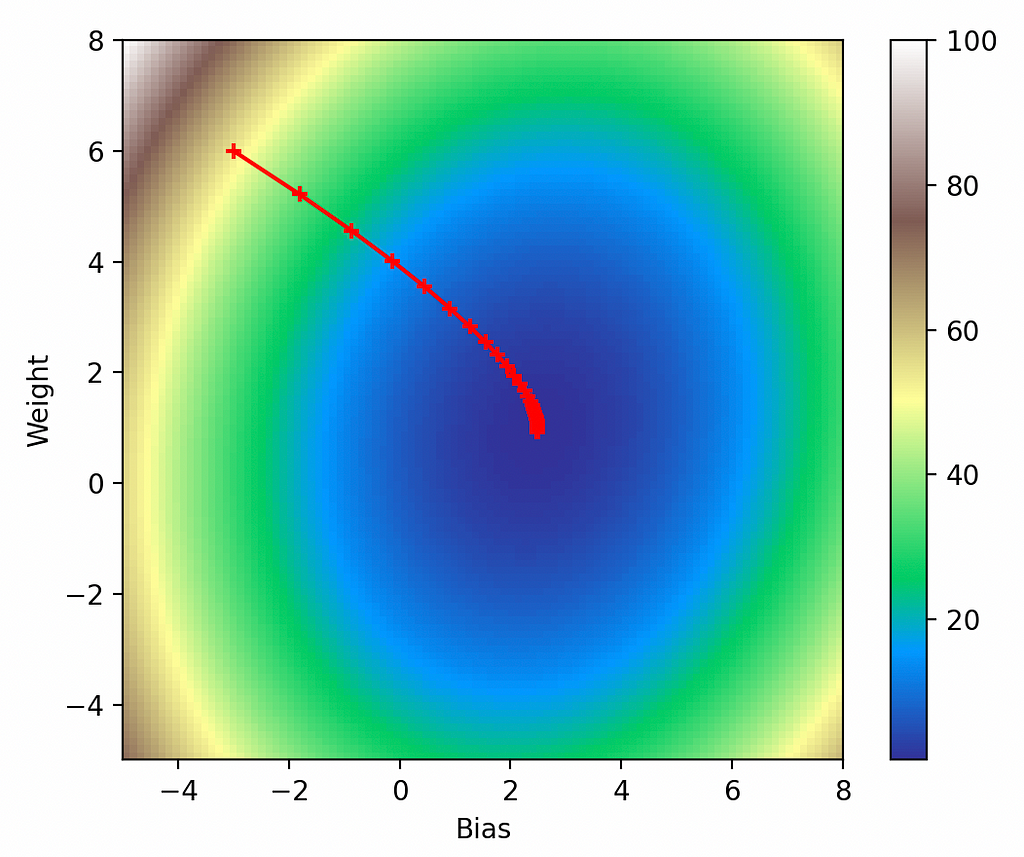
Figure 4. Visualized gradient descent down loss function.
From inspection this looks exactly as it should: the model starts off at our force-initialized parameters of (-3, 6), it takes progressively smaller steps in the direction of the gradient, and it eventually bottoms-out in the global minimum.
Visualizing the Other Parameters
Loss Function
Now we’ll start examining the effects of the other parameters on gradient descent. First is the loss function, for which we used the standard L2 loss:
L2 loss (torch.nn.MSELoss) accumulates the squared error. Source: link. Screen capture by author.
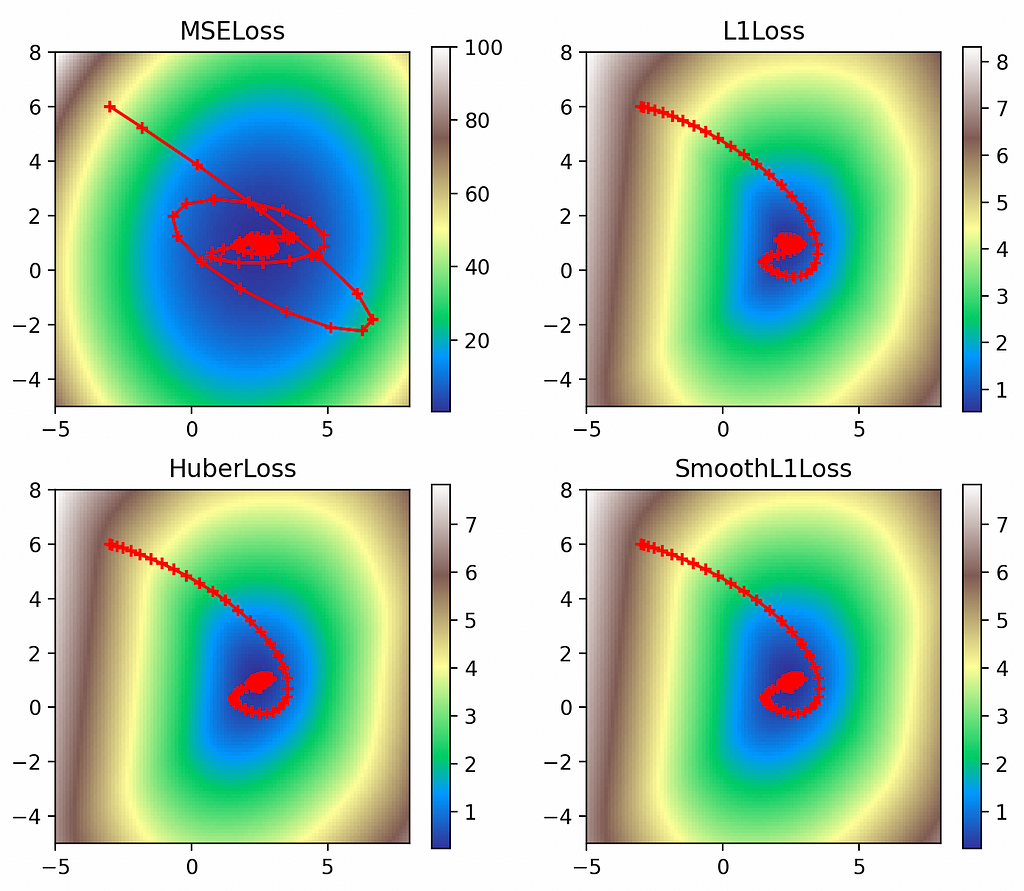
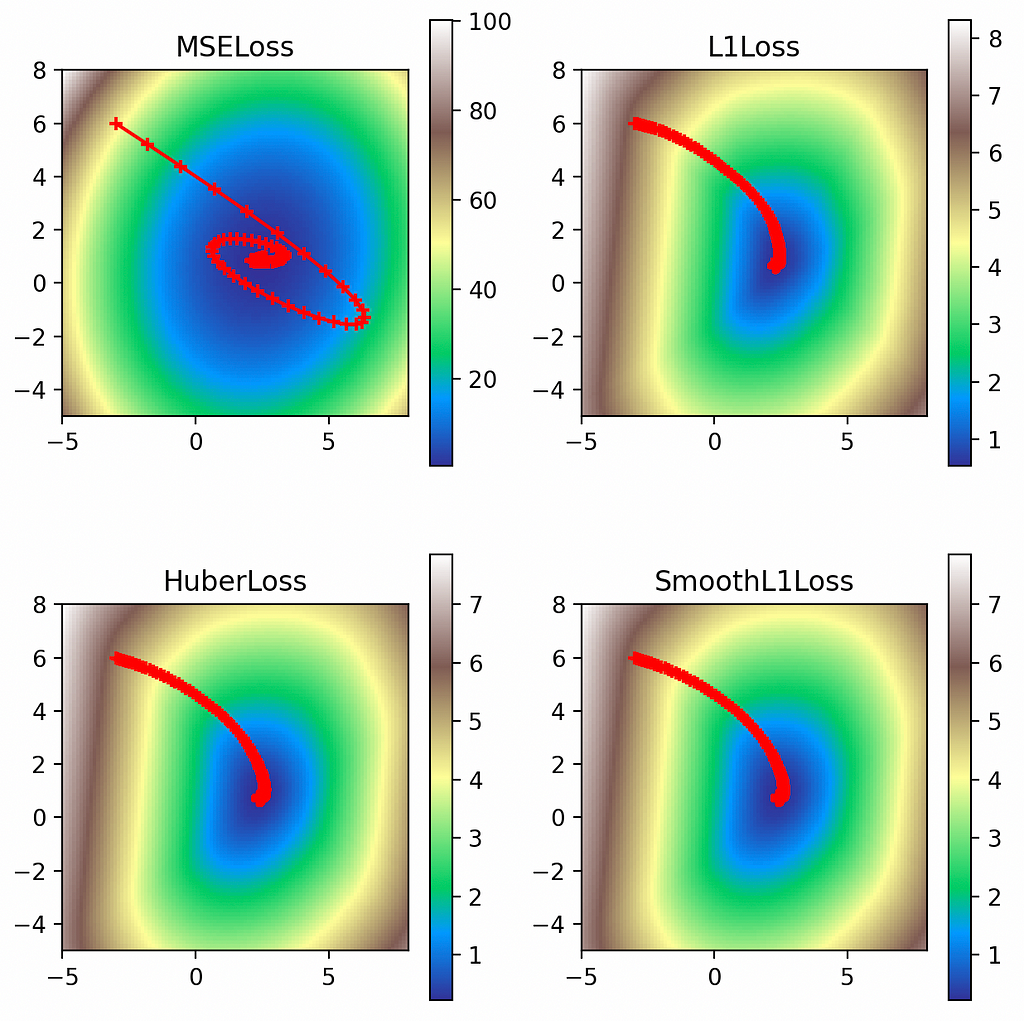
But there are several other loss functions we could use:
L1 loss (torch.nn.L1Loss) accumulates absolute errors. Source: link. Screen capture by author.Huber loss (torch.nn.HuberLoss) uses L2 for small errors and L1 for large. Source: link. Screen capture by author.Smooth L1 loss (torch.nn.SmoothL1Loss) is roughly equivalent to Huber loss with an extra beta parameter. Source: link. Screen capture by author.
We wrap everything we’ve done so far in a loop to try out all the loss functions and plot them together:
Figure 5. Visualized gradient descent down all loss functions.
Here we can see the interesting contours of the non-L2 loss functions. While the L2 loss function is smooth and exhibits large values up to 100, the other loss functions have much smaller values as they reflect only the absolute errors. But the L2 loss’s steeper gradient means the optimizer makes a quicker approach to the global minimum, as evidenced by the greater spacing between its early points. Meanwhile the L1 losses all display much more gradual approaches to their minima.
Momentum
The next most interesting parameter is the momentum, which dictates how much of the last step’s gradient to add in to the current gradient update going froward. Normally very small values of momentum are sufficient, but for the sake of visualization we’re going to set it to the crazy value of 0.9—kids, do NOT try this at home:
multi_plot(lr=0.1, epochs=100, momentum=0.9)
Figure 6. Visualized gradient descent down all loss functions with high momentum.
Thanks to the outrageous momentum value, we can clearly see its effect on the optimizer: it overshoots the global minimum and has to swerve sloppily back around. This effect is most pronounced in the L2 loss, whose steep gradients carry it clean over the minimum and bring it very close to diverging.
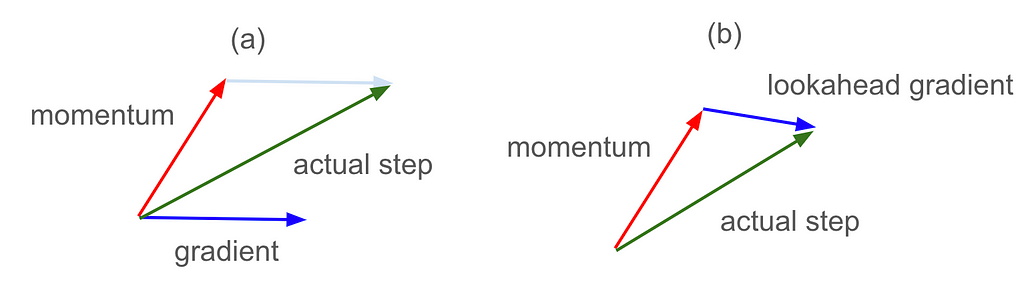
Nesterov Momentum
Nesterov momentum is an interesting tweak on momentum. Normal momentum adds in some of the gradient from the last step to the gradient for the current step, giving us the scenario in figure 7(a) below. But if we already know where the gradient from the last step is going to carry us, then Nesterov momentum instead calculates the current gradient by looking ahead to where that will be, giving us the scenario in figure 7(b) below:
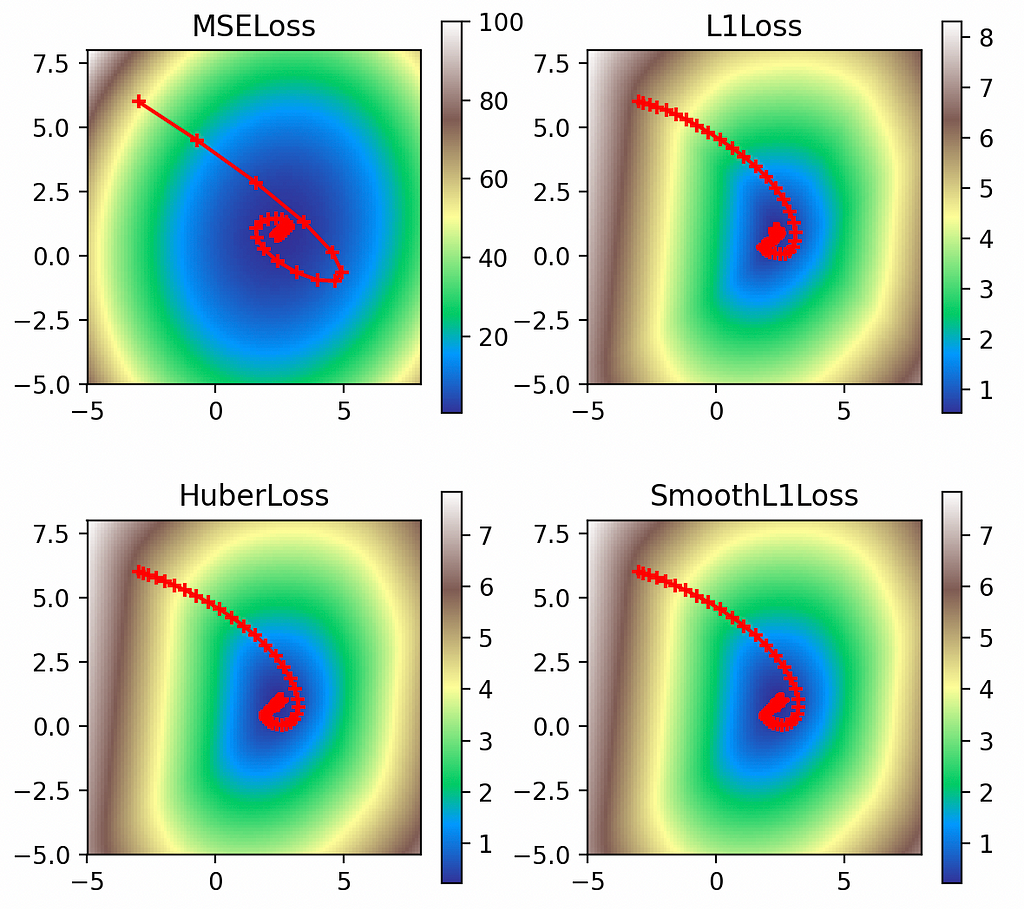
Figure 8. Visualized gradient descent down all loss functions with high Nesterov momentum.
When viewed graphically, we can see that Nesterov momentum has cut down the overshooting we observed with plain momentum. Especially in the L2 case, since our momentum carried us clear over the global minimum, using Nesterov to lookahead where we were going to land allowed us to mix in countervailing gradients from the opposite side of the objective function, in effect course-correcting earlier.
Weight Decay
Next weight decay adds a regularizing L2 penalty on the values of the parameters (the weight and bias of our linear network):
Figure 9. Visualized gradient descent down all loss functions with high Nesterov momentum and weight decay.
In all cases, the regularizing factor has pulled the solutions away from their rightful global minima and closer to the origin (0, 0). The effect is least pronounced with the L2 loss, however, since the loss values are large enough to offset the L2 penalties on the weights.
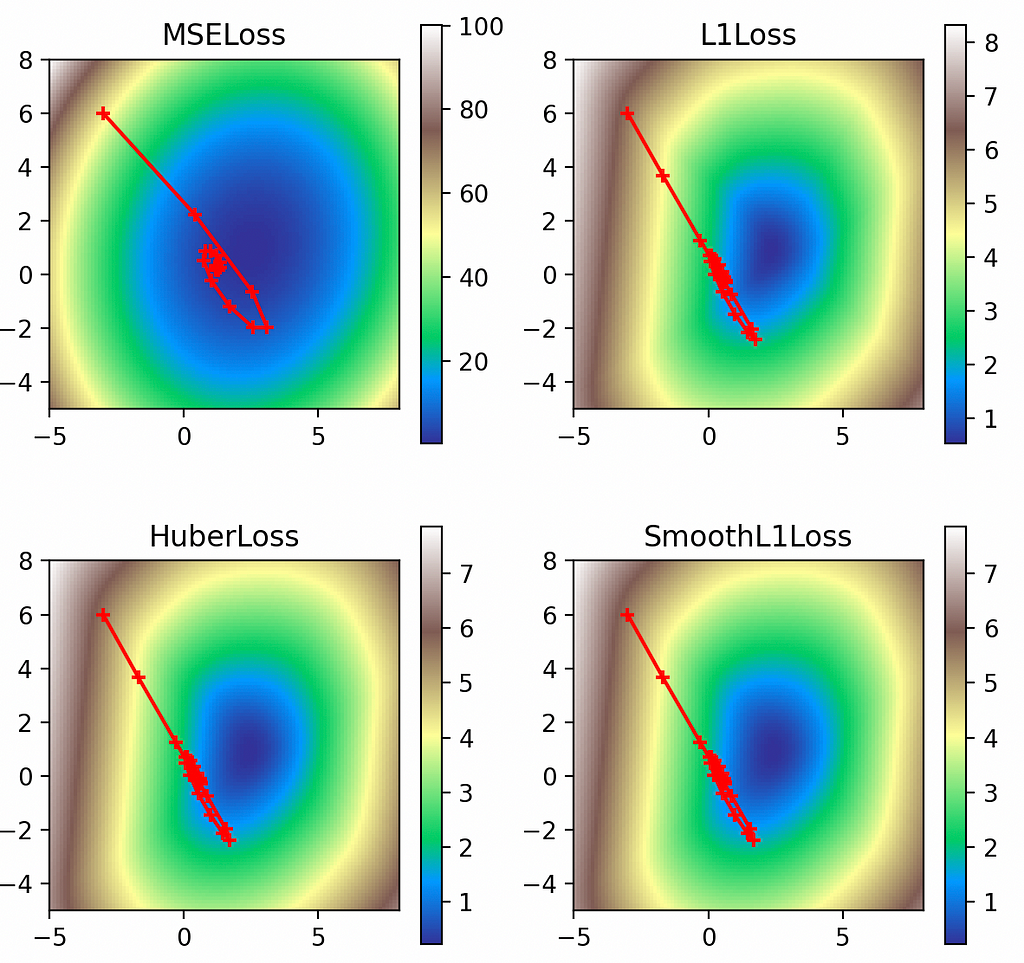
Dampening
Finally we have dampening, which discounts the momentum by the dampening factor. Using a dampening factor of 0.8 we see how it effectively moderates the momentum path through the loss function.
Less than a year since its founding, Paris-based Mistral is launching a new AI flagship model for developers, Mistral Large — just a few months after the release of its first model, Mistral 7B. Much like its predecessor, Mistral Large is an open-source generative AI model. According to the startup, it boasts “top-tier” reasoning capabilities and is proficient in code and mathematics. It’s also multilingual and fluent in five languages (English, French, German, Spanish, and Italian). “This is a significant milestone for us, as the unparalleled performance of this multilingual model will continue to push the boundaries of what is…
Game developers are expressing frustration about Apple Arcade, as payments plummet and projects get axed by Apple’s leadership.
Apple Arcade
As an all-you-can-eat model, Apple Arcade offers developers a way to create games without relying on players opening up their wallets. However, in the years since its introduction, developers are getting worried about it, with one describing Apple Arcade as having the “smell of death.”
Developer sources of MobileGamer.Bizsaid that initial upfront payments from Apple were generous at launch, and that most games released in the opening years were profitable from the first day. Numerous developers were positive about the service, making the development of premium games on mobile more viable.
A month-end deal at Best Buy delivers the lowest price on record on Apple’s upgraded 15-inch MacBook Air with 16GB RAM and a 1TB SSD.
Save up to $400 on MacBook Air models at Best Buy.
The AppleInsider15-inch MacBook Air Price Guide is tracking the record-breaking discount on the premium model that’s currently on sale for $1,499 at Best Buy.
Some European lawmakers allege that Apple is shirking its responsibility to comply with the Digital Markets Act by removing Progressive Web Apps — and are preparing to launch an investigation.
EU prepares to probe Apple over Progressive Web App issues
In early February, European Union users began noticing that Progressive Web Apps weren’t working properly in iOS 17.4. At the time, the issue wasn’t immediately clear.
It was later found out that, due to security and privacy considerations, Apple opted to remove the Home Screen web apps feature in the EU. The company cited concerns about potential misuse by malicious web apps, given that third-party browsers will be available.
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept”, you consent to the use of ALL the cookies.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checkbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.