QED, the world’s first zk-Native blockchain protocol, announced today it has raised $3 million in a funding round led by Arrington Capital with participation from several prominent venture capital fir
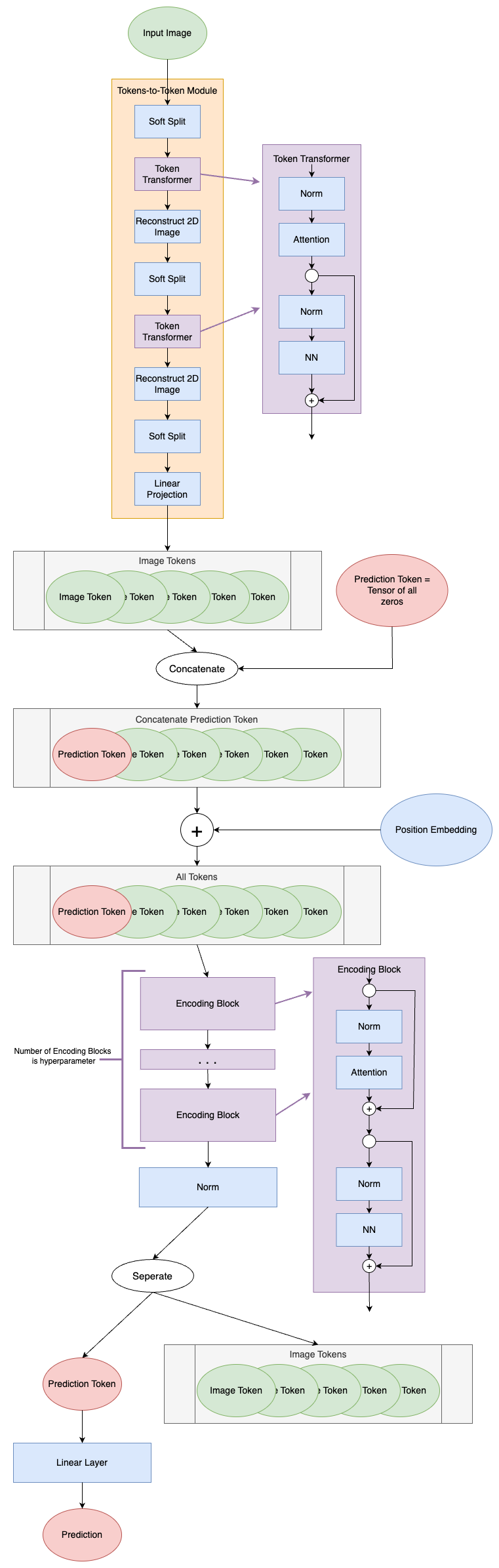
A Full Walk-Through of the Tokens-to-Token Vision Transformer, and Why It’s Better than the Original
Since their introduction in 2017 with Attention is All You Need¹, transformers have established themselves as the state of the art for natural language processing (NLP). In 2021, An Image is Worth 16×16 Words² successfully adapted transformers for computer vision tasks. Since then, numerous transformer-based architectures have been proposed for computer vision.
In 2021, Tokens-to-Token ViT: Training Vision Transformers from Scratch on ImageNet³ outlined the Tokens-to-Token (T2T) ViT. This model aims to remove the heavy pretraining requirement present in the original ViT². This article walks through the T2T-ViT, including open-source code for T2T-ViT, as well as conceptual explanations of the components. All of the code uses the PyTorch Python package.
This article is part of a collection examining the internal workings of Vision Transformers in depth. Each of these articles is also available as a Jupyter Notebook with executable code. The other articles in the series are:
The first vision transformers able to match the performance of CNNs on computer vision tasks required pre-training on large datasets and then transferring to the benchmark of interest². However, pre-training on such datasets is not always feasible. For one, the pre-training dataset that achieved the best results in An Image is Worth 16×16 Words (the JFT-300M dataset) is not publicly available². Furthermore, vistransformers designed for tasks other than traditional image classification may not have such large pre-training datasets available.
In 2021, Tokens-to-Token ViT: Training Vision Transformers from Scratch on ImageNet³ was published, presenting a methodology that would circumvent the heavy pre-training requirement of previous vistransformers. They achieved this by replacing the patch tokenization in the ViT model² with the a Tokens-to-Token (T2T) module.
T2T-ViT Model Diagram (image by author)
Since the T2T module is what makes the T2T-ViT model unique, it will be the focus of this article. For a deep dive into the ViT components see the Vision Transformers article. The code is based on the publicly available GitHub code for Tokens-to-Token ViT³ with some modifications. Changes to the source code include, but are not limited to, modifying to allow for non-square input images and removing dropout layers.
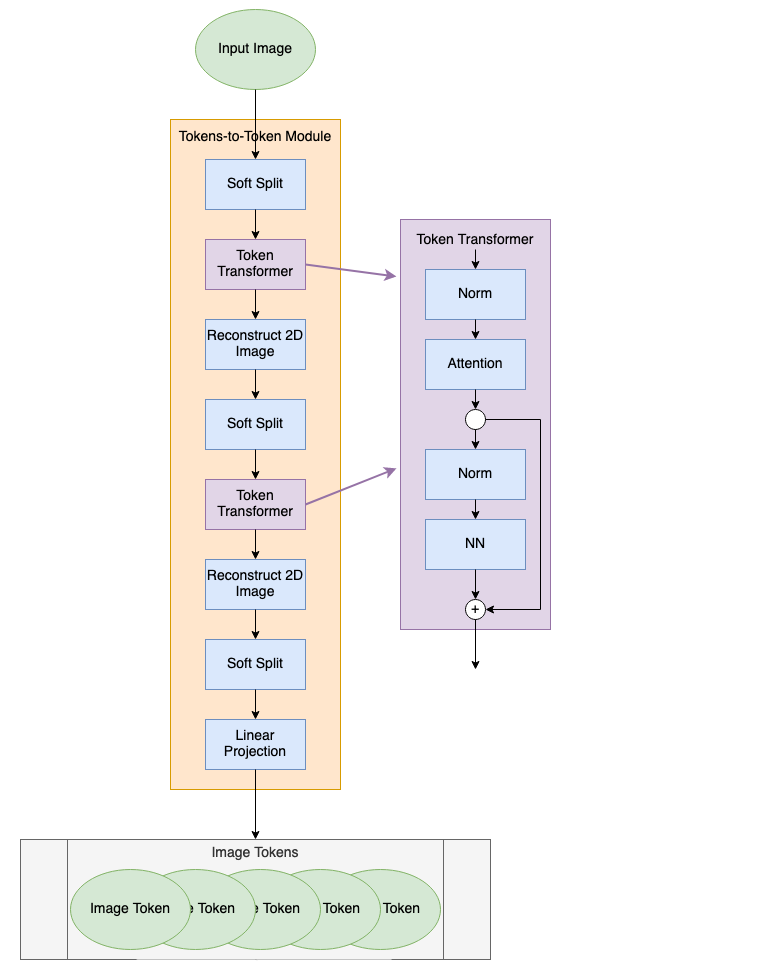
Tokens-to-Token (T2T) Module
The T2T module serves to process the input image into tokens that can be used in the ViT module. Instead of simply splitting the input image into patches that become tokens, the T2T module sequentially computes attention between tokens and aggregates them together to capture additional structure in the image and to reduce the overall token length. The T2T module diagram is shown below.
T2T Module Diagram (image by author)
Soft Split
As the first layer in the T2T-ViT model, the soft split layer is what separates an image into a series of tokens. The soft split layers are shown as blue blocks in the T2T diagram. Unlike the patch tokenization in the original ViT (read more about that here), the soft splits in the T2T-ViT create overlapping patches.
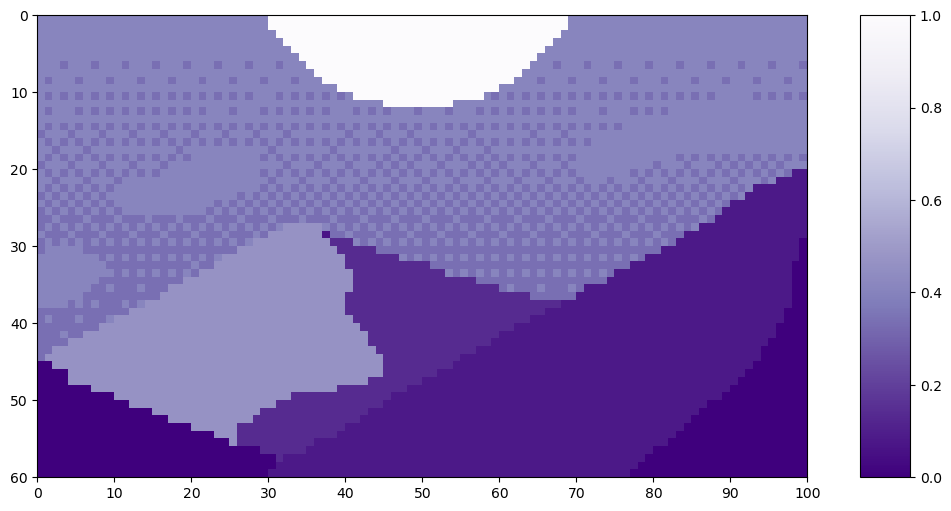
Let’s look at an example of the soft split on this pixel art Mountain at Dusk by Luis Zuno (@ansimuz)⁴. The original artwork has been cropped and converted to a single channel image. This means that each pixel has a value between zero and one. Single channel images are typically displayed in grayscale; however, we’ll be displaying it in a purple color scheme because its easier to see.
This image has size H=60 and W=100. We’ll use a patch size — or equivalently kernel — of k=20. T2T-ViT sets the stride — a measure of overlap — at s=ceil(k/2) and the padding at p=ceil(k/4). For our example, that means we’ll use s=10 and p=5. The padding is all zero values, which appear as the darkest purple.
Before we can look at the patches created in the soft split, we have to know how many patches there will be. The soft splits are implemented as torch.nn.Unfold⁵ layers. To calculate how many tokens the soft split will create, we use the following formula:
where h is the original image height, w is the original image width, k is the kernel size, s is the stride size, and p is the padding size⁵. This formula assumes the kernel is square, and that the stride and padding are symmetric. Additionally, it assumes that dilation is 1.
An aside about dilation: PyTorch describes dilation as “control[ling] the spacing between the kernel points”⁵, and refers readers to the diagram here. A dilation=1 value keeps the kernel as you would expect, all pixels touching. A user in this forum suggests to think about it as “every dilation-th element is used.” In this case, every 1st element is used, meaning every element is used.
The first term in the num_tokens equation describes how many tokens are along the height, while the second term describes how many tokens are along the width. We implement this in code below:
def count_tokens(w, h, k, s, p): """ Function to count how many tokens are produced from a given soft split
Args: w (int): starting width h (int): starting height k (int): kernel size s (int): stride size p (int): padding size
Returns: new_w (int): number of tokens along the width new_h (int): number of tokens along the height total (int): total number of tokens created """
Using the dimensions in the Mountain at Dusk⁴ example:
k = 20 s = 10 p = 5 padded_H = H + 2*p padded_W = W + 2*p print('With padding, the image will be H =', padded_H, 'and W =', padded_W, 'pixels.n')
patches_w, patches_h, total_patches = count_tokens(w=W, h=H, k=k, s=s, p=p) print('There will be', total_patches, 'patches as a result of the soft split;') print(patches_h, 'along the height and', patches_w, 'along the width.')
With padding, the image will be H = 70 and W = 110 pixels.
There will be 60 patches as a result of the soft split; 6 along the height and 10 along the width.
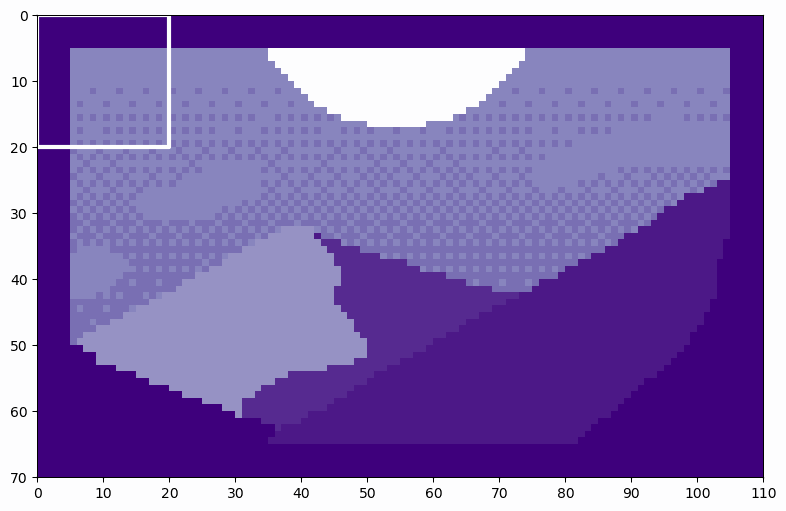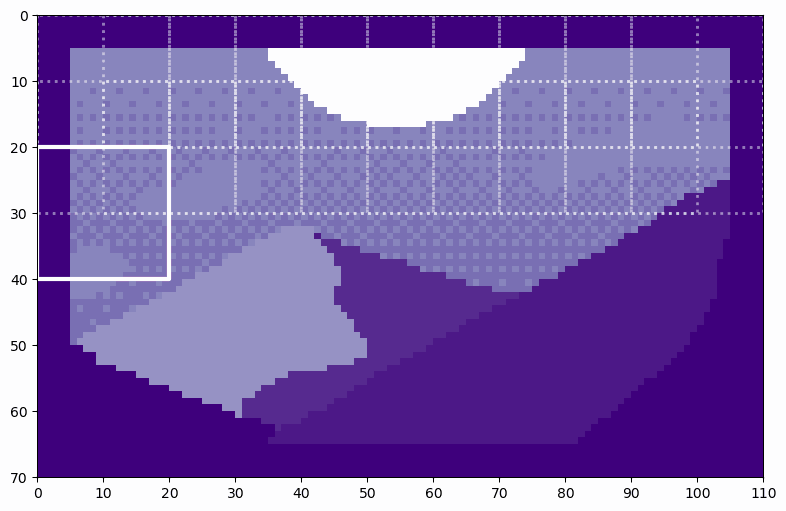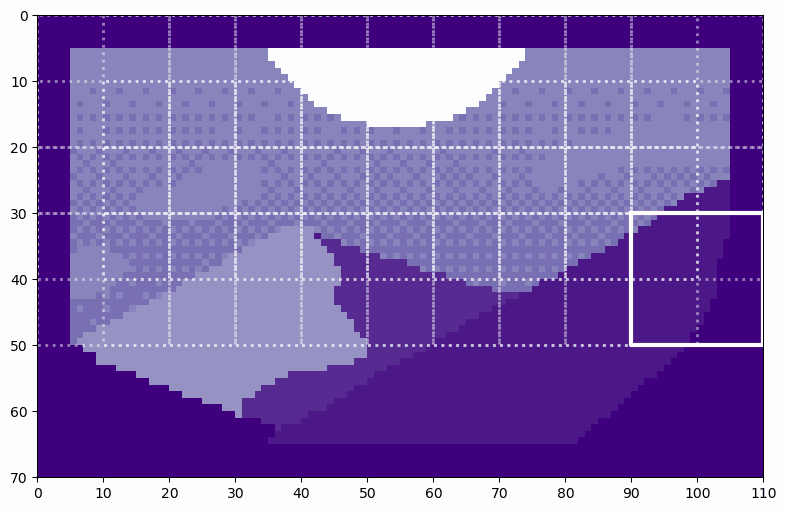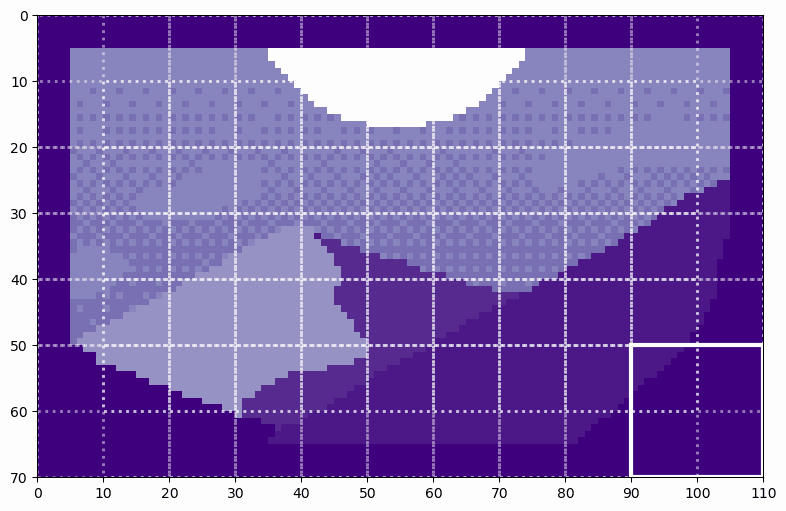
Now, we can see how the soft split creates patches from the Mountain at Dusk⁴.
We can see how the soft split results in overlapping patches. By counting the patches as they move across the image, we can see that there are 6 patches along the height and 10 patches along the width, exactly as predicted. By flattening these patches, we see the resulting tokens. Let’s flatten the first patch as an example.
print('Each patch will make a token of length', str(k**2)+'.') print('n')
You can see the large areas of padding in the top left and bottom right of the matrix, as well as in smaller segments throughout. Now, our tokens are ready to be passed along to the next step.
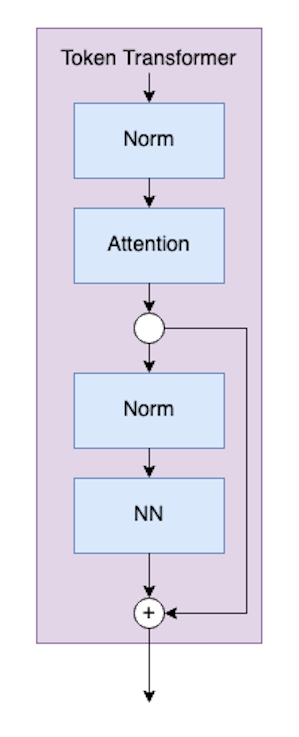
Token Transformer
The next component of the T2T module is the Token Transformer, which is represented by the purple blocks.
Token Transformer (image by author)
The code for the Token Transformer class looks like:
Args: dim (int): size of a single token chan (int): resulting size of a single token num_heads (int): number of attention heads in MSA hidden_chan_mul (float): multiplier to determine the number of hidden channels (features) in the NeuralNet module qkv_bias (bool): determines if the attention qkv layer learns an addative bias qk_scale (NoneFloat): value to scale the queries and keys by; if None, queries and keys are scaled by ``head_dim ** -0.5`` act_layer(nn.modules.activation): torch neural network layer class to use as activation in the NeuralNet module norm_layer(nn.modules.normalization): torch neural network layer class to use as normalization """
def forward(self, x): x = self.attn(self.norm1(x)) x = x + self.neuralnet(self.norm2(x)) return x
The chan, num_heads, qkv_bias, and qk_scale parameters define the Attention module components. A deep dive into attention for vistransformers is best left for another time.
The hidden_chan_mul and act_layer parameters define the Neural Network module components. The activation layer can be any torch.nn.modules.activation⁶ layer. The norm_layer can be chosen from any torch.nn.modules.normalization⁷ layer.
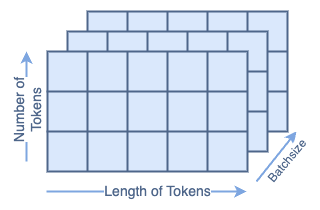
Let’s step through each blue block in the diagram. We’re using 7∗7=49 as our starting token size, since the fist soft split has a default kernel of 7×7.³ We’re using 64 channels because that’s also the default³. We’re using 100 tokens because it’s a nice number. We’re using a batch size of 13 because it’s prime and won’t be confused for any of the other parameters. We’re using 4 heads because it divides the channels; however, you won’t see the head dimension in the Token Transformer Module.
Input dimensions are batchsize: 13 number of tokens: 100 token size: 49
First, we pass the input through a norm layer, which does not change it’s shape. Next, it gets passed through the first Attention module, which changes the length of the tokens. Recall that a more in-depth explanation for Attention in VisTransformers can be found here.
x = TT.norm1(x) print('After norm, dimensions arentbatchsize:', x.shape[0], 'ntnumber of tokens:', x.shape[1], 'nttoken size:', x.shape[2]) x = TT.attn(x) print('After attention, dimensions arentbatchsize:', x.shape[0], 'ntnumber of tokens:', x.shape[1], 'nttoken size:', x.shape[2])
After norm, dimensions are batchsize: 13 number of tokens: 100 token size: 49 After attention, dimensions are batchsize: 13 number of tokens: 100 token size: 64
Now, we must save the state for a split connection layer. In the actual class definition, this is done more efficiently in one line. However, for this walk through, we do it separately.
Next, we can pass it through another norm layer and then the Neural Network module. The norm layer doesn’t change the shape of the input. The neural network is configured to also not change the shape.
The last step is the split connection, which also does not change the shape.
y = TT.norm2(x) print('After norm, dimensions arentbatchsize:', x.shape[0], 'ntnumber of tokens:', x.shape[1], 'nttoken size:', x.shape[2]) y = TT.neuralnet(y) print('After neural net, dimensions arentbatchsize:', x.shape[0], 'ntnumber of tokens:', x.shape[1], 'nttoken size:', x.shape[2]) y = y + x print('After split connection, dimensions arentbatchsize:', x.shape[0], 'ntnumber of tokens:', x.shape[1], 'nttoken size:', x.shape[2])
After norm, dimensions are batchsize: 13 number of tokens: 100 token size: 64 After neural net, dimensions are batchsize: 13 number of tokens: 100 token size: 64 After split connection, dimensions are batchsize: 13 number of tokens: 100 token size: 64
That’s all for the Token Transformer Module.
Neural Network Module
The neural network (NN) module is a sub-component of the token transformer module. The neural network module is very simple, consisting of a fully-connected layer, an activation layer, and another fully-connected layer. The activation layer can be any torch.nn.modules.activation⁶ layer, which is passed as input to the module. The NN module can be configured to change the shape of an input, or to maintain the same shape. We’re not going to step through this code, as NNs are common in machine learning, and not the focus of this article. However, the code for the NN module is presented below.
Args: in_chan (int): number of channels (features) at input hidden_chan (NoneFloat): number of channels (features) in the hidden layer; if None, number of channels in hidden layer is the same as the number of input channels out_chan (NoneFloat): number of channels (features) at output; if None, number of output channels is same as the number of input channels act_layer(nn.modules.activation): torch neural network layer class to use as activation """
super().__init__()
## Define Number of Channels hidden_chan = hidden_chan or in_chan out_chan = out_chan or in_chan
def forward(self, x): x = self.fc1(x) x = self.act(x) x = self.fc2(x) return x
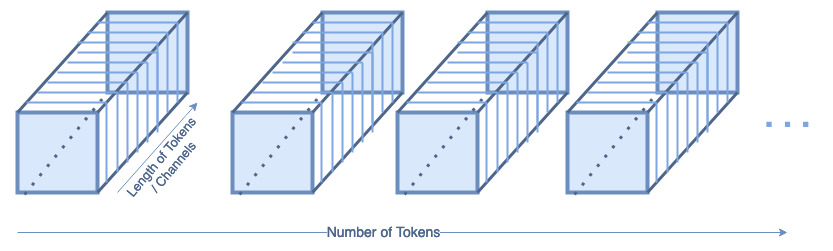
Image Reconstruction
The image reconstruction layers are also shown as blue blocks inside the T2T diagram. The shape of the input to the reconstruction layers looks like (batch, num_tokens, tokensize=channels). If we look at just one batch, that looks like this:
Single Batch of Tokens (image by author)
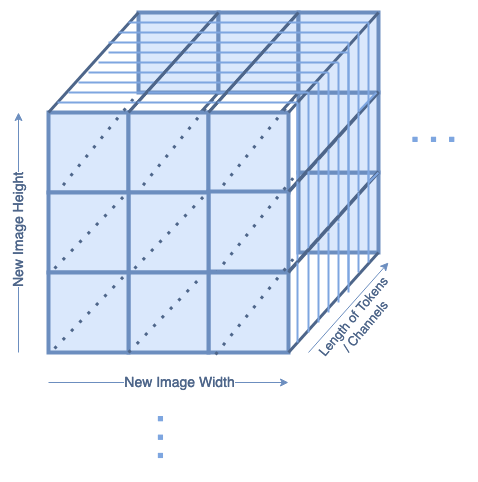
The reconstruction layers reshape the tokens into a 2D image again, which looks like this:
Reconstructed Image (image by author)
In each batch, there will be tokensize = channel number of reconstructed images. This is handled in the same way as if the image was in color, and had three color channels.
The code for reconstruction isn’t wrapped in it’s own function. However, an example is shown below:
Args: img_size (tuple[int, int, int]): size of input (channels, height, width) token_chan (int): number of token channels inside the TokenTransformers token_len (int): desired length of an output token """
## Soft Split 2 x = self.soft_split2(x).transpose(1, 2)
## Project Tokens to desired length x = self.project(x)
return x
Let’s walk through the forward pass. Since we already examined the components in more depth, this section will treat them as black boxes: we’ll just be looking at the input and outputs.
We’ll define an input to the network of shape 1x400x100 to represent a grayscale (one channel) rectangular image. We’re using 64 channels and 768 token length because those are the default values³. We’re using a batch size of 13 because it’s prime and won’t be confused for any of the other parameters.
# Define an Input H = 400 W = 100 channels = 64 batch = 13 x = torch.rand(batch, 1, H, W) print('Input dimensions arentbatchsize:', x.shape[0], 'ntnumber of input channels:', x.shape[1], 'ntimage size:', (x.shape[2], x.shape[3]))
Input dimensions are batchsize: 13 number of input channels: 1 image size: (400, 100)
The input image is first passed through a soft split layer with kernel = 7, stride = 4, and padding = 2. The length of the tokens will be the kernel size (7∗7=49) times the number of channels (= 1 for grayscale input). We can use the count_tokens function to calculate how many tokens there should be after the soft split.
# Count Tokens k = 7 s = 4 p = 2 _, _, T = count_tokens(w=W, h=H, k=k, s=s, p=p) print('There should be', T, 'tokens after the soft split.') print('They should be of length', k, '*', k, '* 1 =', k*k*1)
# Perform the Soft Split x = T2T.soft_split0(x) print('Dimensions after soft split arentbatchsize:', x.shape[0], 'nttoken length:', x.shape[1], 'ntnumber of tokens:', x.shape[2]) x = x.transpose(1, 2)
There should be 2500 tokens after the soft split. They should be of length 7 * 7 * 1 = 49 Dimensions after soft split are batchsize: 13 token length: 49 number of tokens: 2500
Next, we pass through the first Token Transformer. This does not impact the batch size or number of tokens, but it changes the length of the tokens to be channels = 64.
x = T2T.transformer1(x) print('Dimensions after transformer arentbatchsize:', x.shape[0], 'ntnumber of tokens:', x.shape[1], 'nttoken length:', x.shape[2])
Dimensions after transformer are batchsize: 13 number of tokens: 2500 token length: 64
Now, we reconstruct the tokens back into a 2D image. The count_tokens function again can tell us the shape of the new image. It will have 64 channels, the same as the length of the tokens coming out of the Token Transformer.
W, H, _ = count_tokens(w=W, h=H, k=7, s=4, p=2) print('The reconstructed image should have shape', (H, W))
x = x.transpose(1,2).reshape(B, T2T.token_chan, H, W) print('Dimensions of reconstructed image arentbatchsize:', x.shape[0], 'ntnumber of input channels:', x.shape[1], 'ntimage size:', (x.shape[2], x.shape[3]))
The reconstructed image should have shape (100, 25) Dimensions of reconstructed image are batchsize: 13 number of input channels: 64 image size: (100, 25)
Now that we have a 2D image again, we go back to the soft split! The next code block goes through the second soft split, the second Token Transformer, and the second image reconstruction.
# Soft Split k = 3 s = 2 p = 1 _, _, T = count_tokens(w=W, h=H, k=k, s=s, p=p) print('There should be', T, 'tokens after the soft split.') print('They should be of length', k, '*', k, '*', T2T.token_chan, '=', k*k*T2T.token_chan) x = T2T.soft_split1(x) print('Dimensions after soft split arentbatchsize:', x.shape[0], 'nttoken length:', x.shape[1], 'ntnumber of tokens:', x.shape[2]) x = x.transpose(1, 2)
# Token Transformer x = T2T.transformer2(x) print('Dimensions after transformer arentbatchsize:', x.shape[0], 'ntnumber of tokens:', x.shape[1], 'nttoken length:', x.shape[2])
# Reconstruction W, H, _ = count_tokens(w=W, h=H, k=k, s=s, p=p) print('The reconstructed image should have shape', (H, W)) x = x.transpose(1,2).reshape(batch, T2T.token_chan, H, W) print('Dimensions of reconstructed image arentbatchsize:', x.shape[0], 'ntnumber of input channels:', x.shape[1], 'ntimage size:', (x.shape[2], x.shape[3]))
There should be 650 tokens after the soft split. They should be of length 3 * 3 * 64 = 576 Dimensions after soft split are batchsize: 13 token length: 576 number of tokens: 650 Dimensions after transformer are batchsize: 13 number of tokens: 650 token length: 64 The reconstructed image should have shape (50, 13) Dimensions of reconstructed image are batchsize: 13 number of input channels: 64 image size: (50, 13)
From this reconstructed image, we go through a final soft split. Recall that the output of the T2T module should be a list of tokens.
# Soft Split _, _, T = count_tokens(w=W, h=H, k=3, s=2, p=1) print('There should be', T, 'tokens after the soft split.') print('They should be of length 3*3*64=', 3*3*64) x = T2T.soft_split2(x) print('Dimensions after soft split arentbatchsize:', x.shape[0], 'nttoken length:', x.shape[1], 'ntnumber of tokens:', x.shape[2]) x = x.transpose(1, 2)
There should be 175 tokens after the soft split. They should be of length 3 * 3 * 64 = 576 Dimensions after soft split are batchsize: 13 token length: 576 number of tokens: 175
The last layer in the T2T module is a linear layer to project the tokens to the desired output size. We specified that as token_len=768.
x = T2T.project(x) print('Output dimensions arentbatchsize:', x.shape[0], 'ntnumber of tokens:', x.shape[1], 'nttoken length:', x.shape[2])
Output dimensions are batchsize: 13 number of tokens: 175 token length: 768
And that concludes the T2T Module!
ViT Backbone
From the T2T module, the tokens proceed through a ViT backbone. This is identical to the backbone of the ViT model described in [2]. The Vision Transformers article does an in-depth walk through of the ViT model and the ViT backbone. The code is reproduced below, but we won’t do a walk-through. Check that out here and then come back!
""" VisTransformer Backbone Args: preds (int): number of predictions to output token_len (int): length of a token num_heads(int): number of attention heads in MSA Encoding_hidden_chan_mul (float): multiplier to determine the number of hidden channels (features) in the NeuralNet component of the Encoding Module depth (int): number of encoding blocks in the model qkv_bias (bool): determines if the qkv layer learns an addative bias qk_scale (NoneFloat): value to scale the queries and keys by; if None, queries and keys are scaled by ``head_dim ** -0.5`` act_layer(nn.modules.activation): torch neural network layer class to use as activation norm_layer(nn.modules.normalization): torch neural network layer class to use as normalization """
## Make the class token sampled from a truncated normal distrobution timm.layers.trunc_normal_(self.cls_token, std=.02)
def forward(self, x): ## Assumes x is already tokenized
## Get Batch Size B = x.shape[0] ## Concatenate Class Token x = torch.cat((self.cls_token.expand(B, -1, -1), x), dim=1) ## Add Positional Embedding x = x + self.pos_embed ## Run Through Encoding Blocks for blk in self.blocks: x = blk(x) ## Take Norm x = self.norm(x) ## Make Prediction on Class Token x = self.head(x[:, 0]) return x
Complete Code
To create the complete T2T-ViT module, we use the T2T module and the ViT Backbone.
Args: img_size (tuple[int, int, int]): size of input (channels, height, width) softsplit_kernels (tuple[int int, int]): size of the square kernel for each of the soft split layers, sequentially preds (int): number of predictions to output token_len (int): desired length of an output token token_chan (int): number of token channels inside the TokenTransformers num_heads(int): number of attention heads in MSA (only works if =1) T2T_hidden_chan_mul (float): multiplier to determine the number of hidden channels (features) in the NeuralNet component of the Tokens-to-Token (T2T) Module Encoding_hidden_chan_mul (float): multiplier to determine the number of hidden channels (features) in the NeuralNet component of the Encoding Module depth (int): number of encoding blocks in the model qkv_bias (bool): determines if the qkv layer learns an addative bias qk_scale (NoneFloat): value to scale the queries and keys by; if None, queries and keys are scaled by ``head_dim ** -0.5`` act_layer(nn.modules.activation): torch neural network layer class to use as activation norm_layer(nn.modules.normalization): torch neural network layer class to use as normalization """
## Initialize the Weights self.apply(self._init_weights)
def _init_weights(self, m): """ Initialize the weights of the linear layers & the layernorms """ ## For Linear Layers if isinstance(m, nn.Linear): ## Weights are initialized from a truncated normal distrobution timmm.trunc_normal_(m.weight, std=.02) if isinstance(m, nn.Linear) and m.bias is not None: ## If bias is present, bias is initialized at zero nn.init.constant_(m.bias, 0) ## For Layernorm Layers elif isinstance(m, nn.LayerNorm): ## Weights are initialized at one nn.init.constant_(m.weight, 1.0) ## Bias is initialized at zero nn.init.constant_(m.bias, 0)
@torch.jit.ignore ##Tell pytorch to not compile as TorchScript def no_weight_decay(self): """ Used in Optimizer to ignore weight decay in the class token """ return {'cls_token'}
def forward(self, x): x = self.tokens_to_token(x) x = self.vit_backbone(x) return x
In the T2T-ViT Model, the img_size and softsplit_kernels parameters define the soft splits in the T2T module. The num_heads, token_chan, qkv_bias, and qk_scale parameters define the Attention modules within the Token Transformer modules, which are themselves within the T2T module. The T2T_hidden_chan_mul and act_layer define the NN module within the Token Transformer module. The token_len defines the linear layers in the T2T module. The norm_layer defines the norms.
Similarly, the num_heads, token_len, qkv_bias, and qk_scale parameters define the Attention modules within the Encoding Blocks, which are themselves within the ViT Backbone. The Encoding_hidden_chan_mul and act_layer define the NN module within the Encoding Blocks. The depth parameter defines how many Encoding Blocks are in the ViT Backbone. The norm_layer defines the norms. The preds parameter defines the prediction head in the ViT Backbone.
The act_layer can be any torch.nn.modules.activation⁶ layer, and the norm_layer can be any torch.nn.modules.normalization⁷ layer.
The _init_weights method sets custom initial weights for model training. This method could be deleted to initiate all learned weights and biases randomly. As implemented, the weights of linear layers are initialized as a truncated normal distribution; the biases of linear layers are initialized as zero; the weights of normalization layers are initialized as one; the biases of normalization layers are initialized as zero.
Conclusion
Now, you can go forth and train T2T-ViT models with a deep understanding of their mechanics! The code in this article an be found in the GitHub repository for this series. The code from the T2T-ViT paper³ can be found here. Happy transforming!
This article was approved for release by Los Alamos National Laboratory as LA-UR-23–33876. The associated code was approved for a BSD-3 open source license under O#4693.
The Math and the Code Behind Position Embeddings in Vision Transformers
Since their introduction in 2017 with Attention is All You Need¹, transformers have established themselves as the state of the art for natural language processing (NLP). In 2021, An Image is Worth 16×16 Words² successfully adapted transformers for computer vision tasks. Since then, numerous transformer-based architectures have been proposed for computer vision.
This article examines why position embeddings are a necessary component of vision transformers, and how different papers implement position embeddings. It includes open-source code for positional embeddings, as well as conceptual explanations. All of the code uses the PyTorch Python package.
This article is part of a collection examining the internal workings of Vision Transformers in depth. Each of these articles is also available as a Jupyter Notebook with executable code. The other articles in the series are:
Attention is All You Need¹ states that transformers, due to their lack of recurrence or convolution, are not capable of learning information about the order of a set of tokens. Without a position embedding, transformers are invariant to the order of the tokens. For images, that means that patches of an image can be scrambled without impacting the predicted output.
Let’s look at an example of patch order on this pixel art Mountain at Dusk by Luis Zuno (@ansimuz)³. The original artwork has been cropped and converted to a single channel image. This means that each pixel has a value between zero and one. Single channel images are typically displayed in grayscale; however, we’ll be displaying it in a purple color scheme because its easier to see.
We can split this image up into patches of size 20. (For a more in depth explanation of splitting images into patches, see the Vision Transformers article.)
P = 20 N = int((H*W)/(P**2)) print('There will be', N, 'patches, each', P, 'by', str(P)+'.') print('n')
scramble = np.zeros_like(mountains) for i in range(N): t = scramble_order[i] scramble[top_y[i]:bottom_y[i], left_x[i]:right_x[i]] = mountains[top_y[t]:bottom_y[t], left_x[t]:right_x[t]]
Obviously, this is a very different image from the original, and you wouldn’t want a vision transformer to treat these two images as the same.
Attention Invariance Up to Permutation
Let’s investigate the claim that vision transformers are invariant to the order of the tokens. The component of the transformer that would be invariant to token order is the attention module. While an in depth explanation of the attention module is not the focus of this article, a basis understanding is required. For a more detailed walk through of attention in vision transformers, see the Attention article.
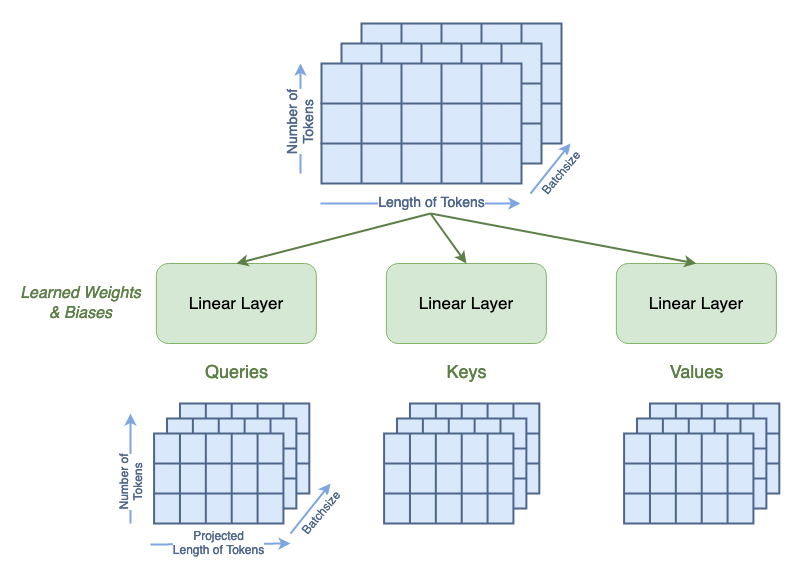
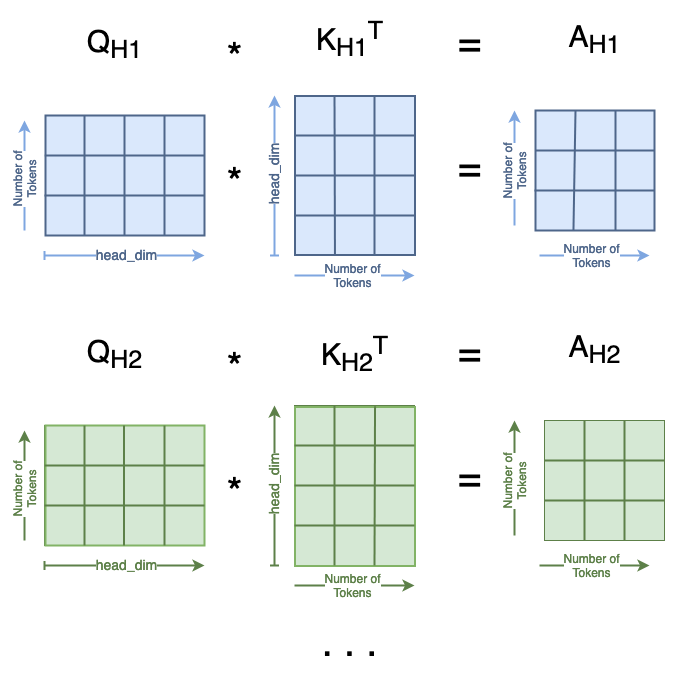
Attention is computed from three matrices — Queries, Keys, and Values — each generated from passing the tokens through a linear layer. Once the Q, K, and V matrices are generated, attention is computed using the following formula.
where Q, K, V, are the queries, keys, and values, respectively; and dₖ is a scaling value. To demonstrate the invariance of attention to token order, we’ll start with three randomly generated matrices to represent Q, K, and V. The shape of Q, K, and V is as follows:
Dimensions of Q, K, and V (image by author)
We’ll use 4 tokens of projected length 9 in this example. The matrices will contain integers to avoid floating point multiplication errors. Once generated, we’ll switch the position of token 0 and token 2 in all three matrices. Matrices with swapped tokens will be denoted with a subscript s.
The first matrix multiplication in the attention formula is Q·Kᵀ=A, where the resulting matrix A is a square with size equal to the number of tokens. When we compute Aₛ with Qₛ and Kₛ, the resulting Aₛ has both rows [0, 2] and columns [0,2] swapped from A.
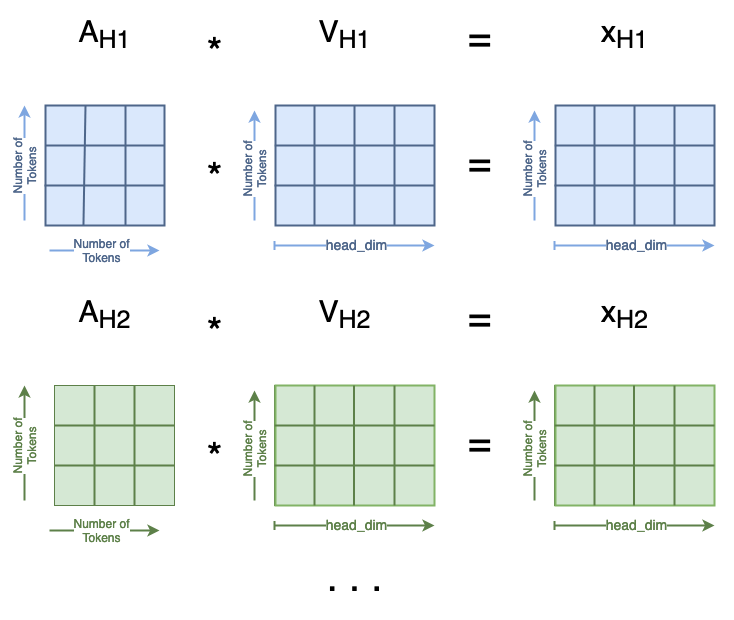
The next matrix multiplication is A·V=A, where the resulting matrix A has the same shape as the initial Q, K, and V matrices. When we compute Aₛ with Aₛ and Vₛ, the resulting Aₛ has rows [0,2] swapped from A.
A = A @ V swapA = swapA @ swapV modA = copy.deepcopy(A) modA[[0,2]] = modA[[2,0]] #swap rows
This demonstrates that changing the order of the tokens in the input to an attention layer results in an output attention matrix with the same token rows changed. This remains intuitive, as attention is a computation of the relationship between the tokens. Without position information, changing the token order does not change how the tokens are related. It isn’t obvious to me why this permutation of the output isn’t enough information to convey position to the transformers. However, everything I’ve read says that it isn’t enough, so we accept that and move forward.
Position Embeddings in Literature
In addition to the theoretically justification for positional embeddings, models that utilize position embeddings perform with higher accuracy than models without. However, there isn’t clear evidence supporting one type of position embedding over another.
In Attention is All You Need¹, they use a fixed sinusoidal positional embedding. They note that they experimented with a learned positional embedding, but observed “nearly identical results.” Note that this model was designed for NLP applications, specifically translation. The authors proceeded with the fixed embedding because it allowed for varying phrase lengths. This would likely not be a concern in computer vision applications.
In An Image is Worth 16×16 Words², they apply positional embeddings to images. They run ablation studies on four different position embeddings in both fixed and learnable settings. This study encompasses no position embedding, a 1D position embedding, a 2D position embedding, and a relative position embedding. They find that models with a position embedding significantly outperform models without a position embedding. However, there is little difference between their different types of positional embeddings or between the fixed and learnable embeddings. This is congruent with the results in [1] that a position embedding is beneficial, though the exact embedding chosen is of little consequence.
In Tokens-to-Token ViT: Training Vision Transformers from Scratch on ImageNet⁴, they use a sinusoidal position embedding that they describe as being the same as in [2]. Their released code mirrors the equations for the sinusoidal position embedding in [1]. Furthermore, their released code fixes the position embedding rather than letting it be a learned parameter with a sinusoidal initialization.
An Example Position Embedding
Defining the Position Embedding
Now, we can look at the specifics of a sinusoidal position embedding. The code is based on the publicly available GitHub code for Tokens-to-Token ViT⁴. Functionally, the position embedding is a matrix with the same shape as the tokens. This looks like:
Shape of Positional Embedding Matrix (image by author)
The formulae for the sinusoidal position embedding from [1] look like
where PE is the position embedding matrix, i is along the number of tokens, j is along the length of the tokens, and d is the token length.
In code, that looks like
def get_sinusoid_encoding(num_tokens, token_len): """ Make Sinusoid Encoding Table
Args: num_tokens (int): number of tokens token_len (int): length of a token
Returns: (torch.FloatTensor) sinusoidal position encoding table """
def get_position_angle_vec(i): return [i / np.power(10000, 2 * (j // 2) / token_len) for j in range(token_len)]
sinusoid_table = np.array([get_position_angle_vec(i) for i in range(num_tokens)]) sinusoid_table[:, 0::2] = np.sin(sinusoid_table[:, 0::2]) sinusoid_table[:, 1::2] = np.cos(sinusoid_table[:, 1::2])
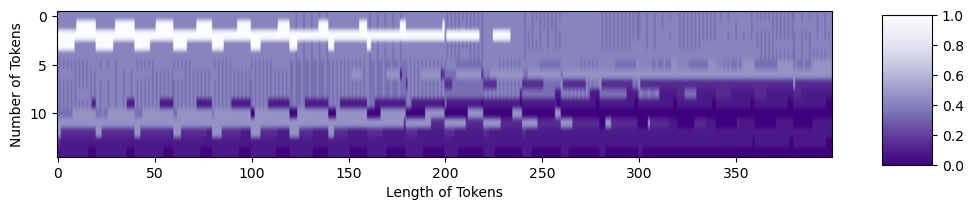
Let’s generate an example position embedding matrix. We’ll use 176 tokens. Each token has length 768, which is the default in the T2T-ViT⁴ code. Once the matrix is generated, we can plot it.
PE = get_sinusoid_encoding(num_tokens=176, token_len=768)
fig = plt.figure(figsize=(10, 8)) plt.imshow(PE[0, :, :], cmap='PuOr_r') plt.xlabel('Along Length of Token') plt.ylabel('Individual Tokens'); cbar_ax = fig.add_axes([0.95, .36, 0.05, 0.25]) plt.clim([-1, 1]) plt.colorbar(label='Value of Position Encoding', cax=cbar_ax); #plt.savefig(os.path.join(figure_path, 'fullPE.png'), bbox_inches='tight')
Code Output (image by author)
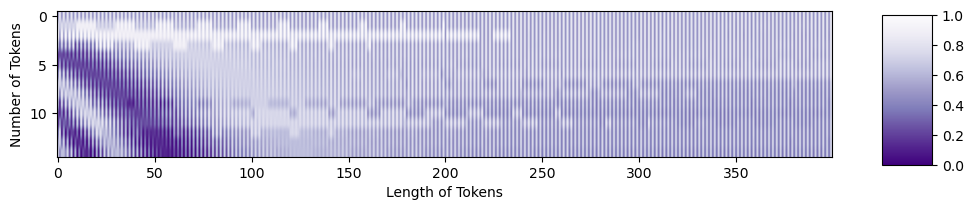
Let’s zoom in to the beginning of the tokens.
fig = plt.figure() plt.imshow(PE[0, :, 0:301], cmap='PuOr_r') plt.xlabel('Along Length of Token') plt.ylabel('Individual Tokens'); cbar_ax = fig.add_axes([0.95, .2, 0.05, 0.6]) plt.clim([-1, 1]) plt.colorbar(label='Value of Position Encoding', cax=cbar_ax); #plt.savefig(os.path.join(figure_path, 'zoomedinPE.png'), bbox_inches='tight')
Code Output (image by author)
It certainly has a sinusoidal structure!
Applying Position Embedding to Tokens
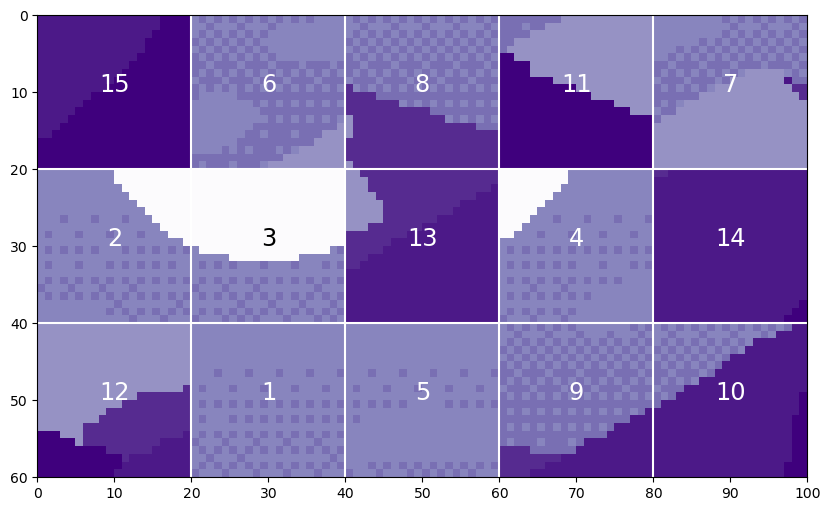
Now, we can add our position embedding to our tokens! We’re going to use Mountain at Dusk³ with the same patch tokenization as above. That will give us 15 tokens of length 20²=400. For more detail about patch tokenization, see the Vision Transformers article. Recall that the patches look like:
Now, we can make a position embedding in the correct shape:
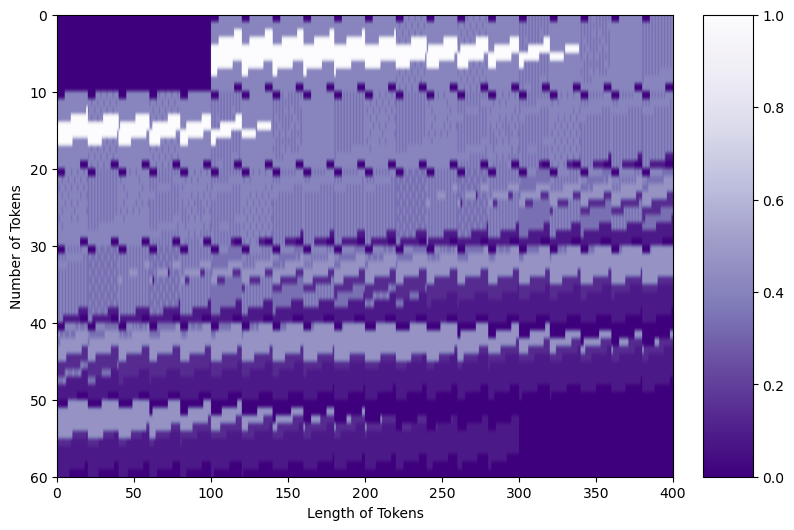
PE = get_sinusoid_encoding(num_tokens=15, token_len=400).numpy()[0,:,:] fig = plt.figure(figsize=(10,6)) plt.imshow(PE, aspect=5, cmap='PuOr_r') plt.xlabel('Length of Tokens') plt.ylabel('Number of Tokens') cbar_ax = fig.add_axes([0.95, .36, 0.05, 0.25]) plt.clim([0, 1]) plt.colorbar(cax=cbar_ax)
Code Output (image by author)
We’re ready now to add the position embedding to the tokens. Purple areas in the position embedding will make the tokens darker, while orange areas will make them lighter.
You can see the structure from the original tokens, as well as the structure in the position embedding! Both pieces of information are present to be passed forward into the transformer.
Conclusion
Now, you should have some intuition of how position embeddings help vision transformers learn. The code in this article an be found in the GitHub repository for this series. The code from the T2T-ViT paper⁴ can be found here. Happy transforming!
This article was approved for release by Los Alamos National Laboratory as LA-UR-23–33876. The associated code was approved for a BSD-3 open source license under O#4693.
Further Reading
To learn more about position embeddings in NLP contexts, see
The Math and the Code Behind Attention Layers in Computer Vision
Since their introduction in 2017 with Attention is All You Need¹, transformers have established themselves as the state of the art for natural language processing (NLP). In 2021, An Image is Worth 16×16 Words² successfully adapted transformers for computer vision tasks. Since then, numerous transformer-based architectures have been proposed for computer vision.
This article takes an in-depth look to how an attention layer works in the context of computer vision. We’ll cover both single-headed and multi-headed attention. It includes open-source code for the attention layers, as well as conceptual explanations of underlying mathematics. The code uses the PyTorch Python package.
This article is part of a collection examining the internal workings of Vision Transformers in depth. Each of these articles is also available as a Jupyter Notebook with executable code. The other articles in the series are:
For NLP applications, attention is often described as the relationship between words (tokens) in a sentence. In a computer vision application, attention looks at the relationships between patches (tokens) in an image.
There are multiple ways to break an image down into a series of tokens. The original ViT² segments an image into patches that are then flattened into tokens; for a more in-depth explanation of this patch tokenization see the Vision Transformers article. The Tokens-to-Token ViT³ develops a more complicated method of creating tokens from an image; more about that methodology can be found in the Tokens-To-Token ViT article.
This article will proceed though an attention layer assuming tokens as input. At the beginning of a transformer, the tokens will be representative of patches in the input image. However, deeper attention layers will compute attention on tokens that have been modified by preceding layers, removing the directness of the representation.
This article examines dot-product (equivalently multiplicative) attention as defined in Attention is All You Need¹. This is the same attention mechanism used in derivative works such as An Image is Worth 16×16 Words² and Tokens-to-Token ViT³. The code is based on the publicly available GitHub code for Tokens-to-Token ViT³ with some modifications. Changes to the source code include, but are not limited to, consolidating the two attention modules into one and implementing multi-headed attention.
Args: dim (int): input size of a single token chan (int): resulting size of a single token (channels) num_heads(int): number of attention heads in MSA qkv_bias (bool): determines if the qkv layer learns an addative bias qk_scale (NoneFloat): value to scale the queries and keys by; if None, queries and keys are scaled by ``head_dim ** -0.5`` """
super().__init__()
## Define Constants self.num_heads = num_heads self.chan = chan self.head_dim = self.chan // self.num_heads self.scale = qk_scale or self.head_dim ** -0.5 assert self.chan % self.num_heads == 0, '"Chan" must be evenly divisible by "num_heads".'
## Define Layers self.qkv = nn.Linear(dim, chan * 3, bias=qkv_bias) #### Each token gets projected from starting length (dim) to channel length (chan) 3 times (for each Q, K, V) self.proj = nn.Linear(chan, chan)
def forward(self, x): B, N, C = x.shape ## Dimensions: (batch, num_tokens, token_len)
## Calcuate QKVs qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, self.head_dim).permute(2, 0, 3, 1, 4) #### Dimensions: (3, batch, heads, num_tokens, chan/num_heads = head_dim) q, k, v = qkv[0], qkv[1], qkv[2]
## Attention Layer x = (attn @ v).transpose(1, 2).reshape(B, N, self.chan) #### Dimensions: (batch, heads, num_tokens, chan)
## Projection Layers x = self.proj(x)
## Skip Connection Layer v = v.transpose(1, 2).reshape(B, N, self.chan) x = v + x #### Because the original x has different size with current x, use v to do skip connection
return x
Single-Headed Attention
Starting with only one attention head, let’s step through each line of the forward pass, and look at some matrix diagrams as we go. We’re using 7∗7=49 as our starting token size, since that’s the starting token size in the T2T-ViT models.³ We’re using 64 channels because that’s also the T2T-ViT default³. We’re using 100 tokens because it’s a nice number. We’re using a batch size of 13 because it’s prime and won’t be confused for any of the other parameters.
# Define an Input token_len = 7*7 channels = 64 num_tokens = 100 batch = 13 x = torch.rand(batch, num_tokens, token_len) B, N, C = x.shape print('Input dimensions arentbatchsize:', x.shape[0], 'ntnumber of tokens:', x.shape[1], 'nttoken size:', x.shape[2])
# Define the Module A = Attention(dim=token_len, chan=channels, num_heads=1, qkv_bias=False, qk_scale=None) A.eval();
Input dimensions are batchsize: 13 number of tokens: 100 token size: 49
From Attention is All You Need¹, attention is defined in terms of Queries, Keys, and Values matrices. Th first step is to calculate these through a learnable linear layer. The boolean qkv_bias term indicates if these linear layers have a bias term or not. This step also changes the length of the tokens from the input 49 to the chan parameter, which we set as 64.
Generation of Queries, Keys, and Values for Single Headed Attention (image by author)
qkv = A.qkv(x).reshape(B, N, 3, A.num_heads, A.head_dim).permute(2, 0, 3, 1, 4) q, k, v = qkv[0], qkv[1], qkv[2] print('Dimensions for Queries arentbatchsize:', q.shape[0], 'ntattention heads:', q.shape[1], 'ntnumber of tokens:', q.shape[2], 'ntnew length of tokens:', q.shape[3]) print('See that the dimensions for queries, keys, and values are all the same:') print('tShape of Q:', q.shape, 'ntShape of K:', k.shape, 'ntShape of V:', v.shape)
Dimensions for Queries are batchsize: 13 attention heads: 1 number of tokens: 100 new length of tokens: 64 See that the dimensions for queries, keys, and values are all the same: Shape of Q: torch.Size([13, 1, 100, 64]) Shape of K: torch.Size([13, 1, 100, 64]) Shape of V: torch.Size([13, 1, 100, 64])
Now, we can start to compute attention, which is defined in as:
where Q, K, V, are the queries, keys, and values, respectively; and dₖ is the dimension of the keys, which is equal to the length of the key tokens and equal to the chan length.
We’re going to go through this equation as it is implemented in the code. We’ll call the intermediate matrices Attn.
The first step is to compute:
In the code, we set
By default,
However, the user can specify an alternative scale value as a hyperparameter.
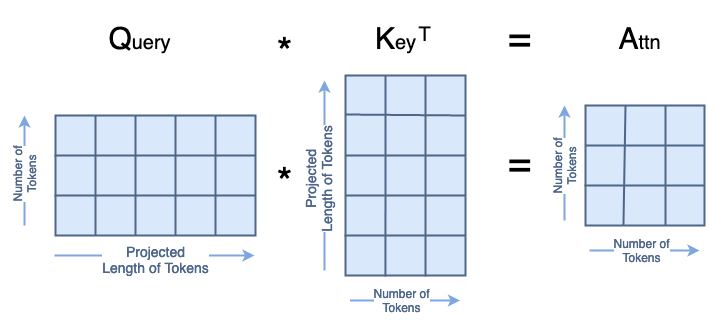
The matrix multiplication Q·Kᵀ in the numerator looks like this:
Q·Kᵀ Matrix Multiplication (image by author)
All of that together in code looks like:
attn = (q * A.scale) @ k.transpose(-2, -1) print('Dimensions for Attn arentbatchsize:', attn.shape[0], 'ntattention heads:', attn.shape[1], 'ntnumber of tokens:', attn.shape[2], 'ntnumber of tokens:', attn.shape[3])
Dimensions for Attn are batchsize: 13 attention heads: 1 number of tokens: 100 number of tokens: 100
Next, we calculate the softmax of A, which doesn’t change it’s shape.
attn = attn.softmax(dim=-1) print('Dimensions for Attn arentbatchsize:', attn.shape[0], 'ntattention heads:', attn.shape[1], 'ntnumber of tokens:', attn.shape[2], 'ntnumber of tokens:', attn.shape[3])
Dimensions for Attn are batchsize: 13 attention heads: 1 number of tokens: 100 number of tokens: 100
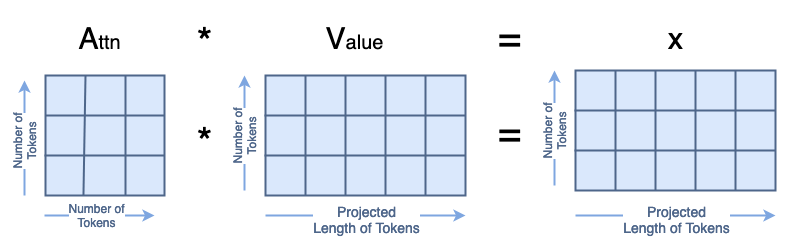
Finally, we compute A·V=x, which looks like:
A·V Matrix Multiplication (image by author)
x = attn @ v print('Dimensions for x arentbatchsize:', x.shape[0], 'ntattention heads:', x.shape[1], 'ntnumber of tokens:', x.shape[2], 'ntlength of tokens:', x.shape[3])
Dimensions for x are batchsize: 13 attention heads: 1 number of tokens: 100 length of tokens: 64
The output x is reshaped to remove the attention head dimension.
x = x.transpose(1, 2).reshape(B, N, A.chan) print('Dimensions for x arentbatchsize:', x.shape[0], 'ntnumber of tokens:', x.shape[1], 'ntlength of tokens:', x.shape[2])
Dimensions for x are batchsize: 13 number of tokens: 100 length of tokens: 64
We then feed x through a learnable linear layer that does not change it’s shape.
x = A.proj(x) print('Dimensions for x arentbatchsize:', x.shape[0], 'ntnumber of tokens:', x.shape[1], 'ntlength of tokens:', x.shape[2])
Dimensions for x are batchsize: 13 number of tokens: 100 length of tokens: 64
Lastly, we implement a skip connection. Since the current shape of x is different from the input shape of x, we use V for the skip connection. We do flatten V in the attention head dimension.
orig_shape = (batch, num_tokens, token_len) curr_shape = (x.shape[0], x.shape[1], x.shape[2]) v = v.transpose(1, 2).reshape(B, N, A.chan) v_shape = (v.shape[0], v.shape[1], v.shape[2]) print('Original shape of input x:', orig_shape) print('Current shape of x:', curr_shape) print('Shape of V:', v_shape) x = v + x print('After skip connection, dimensions for x arentbatchsize:', x.shape[0], 'ntnumber of tokens:', x.shape[1], 'ntlength of tokens:', x.shape[2])
Original shape of input x: (13, 100, 49) Current shape of x: (13, 100, 64) Shape of V: (13, 100, 64) After skip connection, dimensions for x are batchsize: 13 number of tokens: 100 length of tokens: 64
That completes the attention layer!
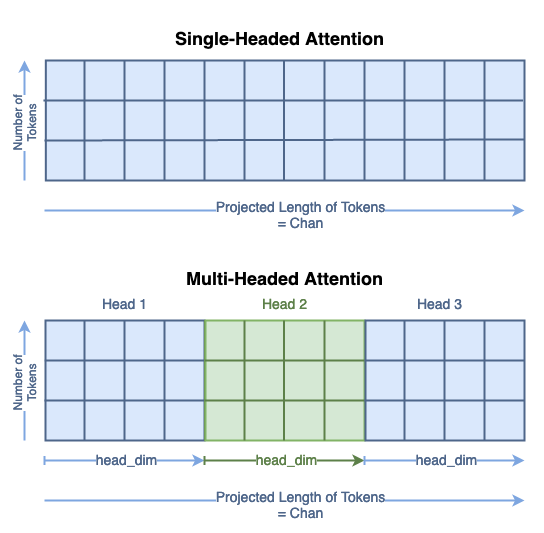
Multi-Headed Attention
Now that we’ve looked at single headed attention, we can expand to multi-headed attention. In the context of computer vision, this is often called Multi-headed Self Attention (MSA). This section isn’t going to go through all the steps in as much detail; instead, we’ll focus on the places where the matrix shapes differ.
Same as for a single attention head, we’re using 7∗7=49 as our starting token size and 64 channels because that’s the T2T-ViT default³. We’re using 100 tokens because it’s a nice number. We’re using a batch size of 13 because it’s prime and won’t be confused for any of the other parameters.
The number of attention heads must evenly divide the number of channels, so for this example we’ll use 4 attention heads.
# Define an Input token_len = 7*7 channels = 64 num_tokens = 100 batch = 13 num_heads = 4 x = torch.rand(batch, num_tokens, token_len) B, N, C = x.shape print('Input dimensions arentbatchsize:', x.shape[0], 'ntnumber of tokens:', x.shape[1], 'nttoken size:', x.shape[2])
Input dimensions are batchsize: 13 number of tokens: 100 token size: 49
The process to computer the Queries, Keys, and Values remains the same as in single-headed attention. However, you can see that the new length of the tokens is chan/num_heads. The total size of the Q, K, and V matrices have not changed; their contents are just distributed across the head dimension. You can think abut this as segmenting the single headed matrix for the multiple heads:
Multi-Headed Attention Segmentation (image by author)
We’ll denote the submatrices as Qₕᵢ for Query head i.
qkv = MSA.qkv(x).reshape(B, N, 3, MSA.num_heads, MSA.head_dim).permute(2, 0, 3, 1, 4) q, k, v = qkv[0], qkv[1], qkv[2] print('Head Dimension = chan / num_heads =', MSA.chan, '/', MSA.num_heads, '=', MSA.head_dim) print('Dimensions for Queries arentbatchsize:', q.shape[0], 'ntattention heads:', q.shape[1], 'ntnumber of tokens:', q.shape[2], 'ntnew length of tokens:', q.shape[3]) print('See that the dimensions for queries, keys, and values are all the same:') print('tShape of Q:', q.shape, 'ntShape of K:', k.shape, 'ntShape of V:', v.shape)
Head Dimension = chan / num_heads = 64 / 4 = 16 Dimensions for Queries are batchsize: 13 attention heads: 4 number of tokens: 100 new length of tokens: 16 See that the dimensions for queries, keys, and values are all the same: Shape of Q: torch.Size([13, 4, 100, 16]) Shape of K: torch.Size([13, 4, 100, 16]) Shape of V: torch.Size([13, 4, 100, 16])
The next step is to compute
for every head i. In this context, the length of the keys is
As in single headed attention, we use the default
though the user can specify an alternative scale value as a hyperparameter.
We end this step with num_heads = 4 different Attn matrices, which looks like:
Q·Kᵀ Matrix Multiplication for MSA (image by author)
attn = (q * MSA.scale) @ k.transpose(-2, -1) print('Dimensions for Attn arentbatchsize:', attn.shape[0], 'ntattention heads:', attn.shape[1], 'ntnumber of tokens:', attn.shape[2], 'ntnumber of tokens:', attn.shape[3])
Dimensions for Attn are batchsize: 13 attention heads: 4 number of tokens: 100 number of tokens: 100
Next we calculate the softmax of A, which doesn’t change it’s shape.
Then, we can compute
This is similarly distributed across the multiple attention heads:
A·V Matrix Multiplication for MSA (image by author)
attn = attn.softmax(dim=-1)
x = attn @ v print('Dimensions for x arentbatchsize:', x.shape[0], 'ntattention heads:', x.shape[1], 'ntnumber of tokens:', x.shape[2], 'ntlength of tokens:', x.shape[3])
Dimensions for x are batchsize: 13 attention heads: 4 number of tokens: 100 length of tokens: 16
Now we concatenate all of the xₕᵢ’s together through some reshaping. This is the inverse operation from the first step:
Multi-Headed Attention Segmentation (image by author)
x = x.transpose(1, 2).reshape(B, N, MSA.chan) print('Dimensions for x arentbatchsize:', x.shape[0], 'ntnumber of tokens:', x.shape[1], 'ntlength of tokens:', x.shape[2])
Dimensions for x are batchsize: 13 number of tokens: 100 length of tokens: 64
Now that we’ve concatenated all of the heads back together, the rest of the Attention module remains unchanged. For the skip connection, we still use V, but we have to reshape it to remove the head dimension.
x = MSA.proj(x) print('Dimensions for x arentbatchsize:', x.shape[0], 'ntnumber of tokens:', x.shape[1], 'ntlength of tokens:', x.shape[2])
orig_shape = (batch, num_tokens, token_len) curr_shape = (x.shape[0], x.shape[1], x.shape[2]) v = v.transpose(1, 2).reshape(B, N, A.chan) v_shape = (v.shape[0], v.shape[1], v.shape[2]) print('Original shape of input x:', orig_shape) print('Current shape of x:', curr_shape) print('Shape of V:', v_shape) x = v + x print('After skip connection, dimensions for x arentbatchsize:', x.shape[0], 'ntnumber of tokens:', x.shape[1], 'ntlength of tokens:', x.shape[2])
Dimensions for x are batchsize: 13 number of tokens: 100 length of tokens: 64 Original shape of input x: (13, 100, 49) Current shape of x: (13, 100, 64) Shape of V: (13, 100, 64) After skip connection, dimensions for x are batchsize: 13 number of tokens: 100 length of tokens: 64
And that concludes multi-headed attention!
Conclusion
We’ve now walked through every step of an attention layer as implemented for vision transformers. The learnable weights in an attention layer are found in the first projection from tokens to queries, keys, and values and in the final projection. The majority of the attention layer is deterministic matrix multiplication. However, the linear layers can contain large numbers of weights when long tokens are used. The number of weights in the QKV projection layer are equal to input_token_len∗chan∗3, and the number of weights in the final projection layer are equal to chan².
To use the attention layers, you can create custom attention layers (as done here!), or use attention layers included in machine learning packages. If you want to use attention layers as defined here, they can be found in the GitHub repository for this article series. PyTorch also has torch.nn.MultiheadedAttention()⁴ layers, which compute attention as defined above. Happy attending!
This article was approved for release by Los Alamos National Laboratory as LA-UR-23–33876. The associated code was approved for a BSD-3 open source license under O#4693.
Further Reading
To learn more about attention layers in NLP contexts, see
A Full Walk-Through of Vision Transformers in PyTorch
Since their introduction in 2017 with Attention is All You Need¹, transformers have established themselves as the state of the art for natural language processing (NLP). In 2021, An Image is Worth 16×16 Words² successfully adapted transformers for computer vision tasks. Since then, numerous transformer-based architectures have been proposed for computer vision.
This article walks through the Vision Transformer (ViT) as laid out in An Image is Worth 16×16 Words². It includes open-source code for the ViT, as well as conceptual explanations of the components. All of the code uses the PyTorch Python package.
This article is part of a collection examining the internal workings of Vision Transformers in depth. Each of these articles is also available as a Jupyter Notebook with executable code. The other articles in the series are:
As introduced in Attention is All You Need¹, transformers are a type of machine learning model utilizing attention as the primary learning mechanism. Transformers quickly became the state of the art for sequence-to-sequence tasks such as language translation.
An Image is Worth 16×16 Words² successfully modified the transformer put forth in [1] to solve image classification tasks, creating the Vision Transformer (ViT). The ViT is based on the same attention mechanism as the transformer in [1]. However, while transformers for NLP tasks consist of an encoder attention branch and a decoder attention branch, the ViT only uses an encoder. The output of the encoder is then passed to a neural network “head” that makes a prediction.
The drawback of ViT as implemented in [2] is that it’s optimal performance requires pretraining on large datasets. The best models pretrained on the proprietary JFT-300M dataset. Models pretrained on the smaller, open source ImageNet-21k perform on par with the state-of-the-art convolutional ResNet models.
Tokens-to-Token ViT: Training Vision Transformers from Scratch on ImageNet³ attempts to remove this pretraining requirement by introducing a novel pre-processing methodology to transform an input image into a series of tokens. More about this method can be found here. For this article, we’ll focus on the ViT as implemented in [2].
Model Walk-Through
This article follows the model structure outlined in An Image is Worth 16×16 Words². However, code from this paper is not publicly available. Code from the more recent Tokens-to-Token ViT³ is available on GitHub. The Tokens-to-Token ViT (T2T-ViT) model prepends a Tokens-to-Token (T2T) module to a vanilla ViT backbone. The code in this article is based on the ViT components in the Tokens-to-Token ViT³GitHub code. Modifications made for this article include, but are not limited to, modifying to allow for non-square input images and removing dropout layers.
A diagram of the ViT model is shown below.
ViT Model Diagram (image by author)
Image Tokenization
The first step of the ViT is to create tokens from the input image. Transformers operate on a sequence of tokens; in NLP, this is commonly a sentence of words. For computer vision, it is less clear how to segment the input into tokens.
TheViT converts an image to tokens such that each token represents a local area — or patch — of the image. They describe reshaping an image of height H, width W, and channels C into N tokens with patch size P:
Each token is of length P²∗C.
Let’s look at an example of patch tokenization on this pixel art Mountain at Dusk by Luis Zuno (@ansimuz)⁴. The original artwork has been cropped and converted to a single channel image. This means that each pixel has a value between zero and one. Single channel images are typically displayed in grayscale; however, we’ll be displaying it in a purple color scheme because its easier to see.
Note that the patch tokenization is not included in the code associated with [3]. All code in this section is original to the author.
After extracting tokens from an image, it is common to use a linear projection to change the length of the tokens. This is implemented as a learnable linear layer. The new length of the tokens is referred to as the latent dimension², channel dimension³, or the token length. After the projection, the tokens are no longer visually identifiable as a patch from the original image.
Now that we understand the concept, we can look at how patch tokenization is implemented in code.
""" Patch Tokenization Module Args: img_size (tuple[int, int, int]): size of input (channels, height, width) patch_size (int): the side length of a square patch token_len (int): desired length of an output token """ super().__init__()
## Defining Parameters self.img_size = img_size C, H, W = self.img_size self.patch_size = patch_size self.token_len = token_len assert H % self.patch_size == 0, 'Height of image must be evenly divisible by patch size.' assert W % self.patch_size == 0, 'Width of image must be evenly divisible by patch size.' self.num_tokens = (H / self.patch_size) * (W / self.patch_size)
def forward(self, x): x = self.split(x).transpose(1,0) x = self.project(x) return x
Note the two assert statements that ensure the image dimensions are evenly divisible by the patch size. The actual splitting into patches is implemented as a torch.nn.Unfold⁵ layer.
We’ll run an example of this code using our cropped, single channel version of Mountain at Dusk⁴. We should see the values for number of tokens and initial token size as we did above. We’ll use token_len=768 as the projected length, which is the size for the base variant of ViT².
The first line in the code block below is changing the datatype of Mountain at Dusk⁴ from a NumPy array to a Torch tensor. We also have to unsqueeze⁶ the tensor to create a channel dimension and a batch size dimension. As above, we have one channel. Since there is only one image, batchsize=1.
x = torch.from_numpy(mountains).unsqueeze(0).unsqueeze(0).to(torch.float32) token_len = 768 print('Input dimensions arentbatchsize:', x.shape[0], 'ntnumber of input channels:', x.shape[1], 'ntimage size:', (x.shape[2], x.shape[3]))
Input dimensions are batchsize: 1 number of input channels: 1 image size: (60, 100)
Now, we’ll split the image into tokens.
x = patch_tokens.split(x).transpose(2,1) print('After patch tokenization, dimensions arentbatchsize:', x.shape[0], 'ntnumber of tokens:', x.shape[1], 'nttoken length:', x.shape[2])
After patch tokenization, dimensions are batchsize: 1 number of tokens: 15 token length: 400
As we saw in the example, there are N=15 tokens each of length 400. Lastly, we project the tokens to be the token_len.
x = patch_tokens.project(x) print('After projection, dimensions arentbatchsize:', x.shape[0], 'ntnumber of tokens:', x.shape[1], 'nttoken length:', x.shape[2])
After projection, dimensions are batchsize: 1 number of tokens: 15 token length: 768
Now that we have tokens, we’re ready to proceed through the ViT.
Token Processing
We’ll designate the next two steps of the ViT, before the encoding blocks, as “token processing.” The token processing component of the ViT diagram is shown below.
Token Processing Components of ViT Diagram (image by author)
The first step is to prepend a blank token, called the Prediction Token, to the the image tokens. This token will be used at the output of the encoding blocks to make a prediction. It starts off blank — equivalently zero — so that it can gain information from the other image tokens.
We’ll be starting with 175 tokens. Each token has length 768, which is the size for the base variant of ViT². We’re using a batch size of 13 because it’s prime and won’t be confused for any of the other parameters.
# Define an Input num_tokens = 175 token_len = 768 batch = 13 x = torch.rand(batch, num_tokens, token_len) print('Input dimensions arentbatchsize:', x.shape[0], 'ntnumber of tokens:', x.shape[1], 'nttoken length:', x.shape[2])
x = torch.cat((pred_token, x), dim=1) print('Dimensions with Prediction Token arentbatchsize:', x.shape[0], 'ntnumber of tokens:', x.shape[1], 'nttoken length:', x.shape[2])
Input dimensions are batchsize: 13 number of tokens: 175 token length: 768 Prediction Token dimensions are batchsize: 13 number of tokens: 1 token length: 768 Dimensions with Prediction Token are batchsize: 13 number of tokens: 176 token length: 768
Now, we add a position embedding for our tokens. The position embedding allows the transformer to understand the order of the image tokens. Note that this is an addition, not a concatenation. The specifics of position embeddings are a tangent best left for another time.
def get_sinusoid_encoding(num_tokens, token_len): """ Make Sinusoid Encoding Table
Args: num_tokens (int): number of tokens token_len (int): length of a token
Returns: (torch.FloatTensor) sinusoidal position encoding table """
def get_position_angle_vec(i): return [i / np.power(10000, 2 * (j // 2) / token_len) for j in range(token_len)]
sinusoid_table = np.array([get_position_angle_vec(i) for i in range(num_tokens)]) sinusoid_table[:, 0::2] = np.sin(sinusoid_table[:, 0::2]) sinusoid_table[:, 1::2] = np.cos(sinusoid_table[:, 1::2])
PE = get_sinusoid_encoding(num_tokens+1, token_len) print('Position embedding dimensions arentnumber of tokens:', PE.shape[1], 'nttoken length:', PE.shape[2])
x = x + PE print('Dimensions with Position Embedding arentbatchsize:', x.shape[0], 'ntnumber of tokens:', x.shape[1], 'nttoken length:', x.shape[2])
Position embedding dimensions are number of tokens: 176 token length: 768 Dimensions with Position Embedding are batchsize: 13 number of tokens: 176 token length: 768
Now, our tokens are ready to proceed to the encoding blocks.
Encoding Block
The encoding block is where the model actually learns from the image tokens. The number of encoding blocks is a hyperparameter set by the user. A diagram of the encoding block is below.
Args: dim (int): size of a single token num_heads(int): number of attention heads in MSA hidden_chan_mul (float): multiplier to determine the number of hidden channels (features) in the NeuralNet component qkv_bias (bool): determines if the qkv layer learns an addative bias qk_scale (NoneFloat): value to scale the queries and keys by; if None, queries and keys are scaled by ``head_dim ** -0.5`` act_layer(nn.modules.activation): torch neural network layer class to use as activation norm_layer(nn.modules.normalization): torch neural network layer class to use as normalization """
def forward(self, x): x = x + self.attn(self.norm1(x)) x = x + self.neuralnet(self.norm2(x)) return x
The num_heads, qkv_bias, and qk_scale parameters define the Attention module components. A deep dive into attention for vision transformers is left for another time.
The hidden_chan_mul and act_layer parameters define the Neural Network module components. The activation layer can be any torch.nn.modules.activation⁷ layer. We’ll look more at the Neural Network module later.
The norm_layer can be chosen from any torch.nn.modules.normalization⁸ layer.
We’ll now step through each blue block in the diagram and its accompanying code. We’ll use 176 tokens of length 768. We’ll use a batch size of 13 because it’s prime and won’t be confused for any of the other parameters. We’ll use 4 attention heads because it evenly divides token length; however, you won’t see the attention head dimension in the encoding block.
# Define the Module E = Encoding(dim=token_len, num_heads=heads, hidden_chan_mul=1.5, qkv_bias=False, qk_scale=None, act_layer=nn.GELU, norm_layer=nn.LayerNorm) E.eval();
Input dimensions are batchsize: 13 number of tokens: 176 token length: 768
Now, we’ll pass through a norm layer and an Attention module. The Attention module in the encoding block is parameterized so that it don’t change the token length. After the Attention module, we implement our first split connection.
y = E.norm1(x) print('After norm, dimensions arentbatchsize:', y.shape[0], 'ntnumber of tokens:', y.shape[1], 'nttoken size:', y.shape[2]) y = E.attn(y) print('After attention, dimensions arentbatchsize:', y.shape[0], 'ntnumber of tokens:', y.shape[1], 'nttoken size:', y.shape[2]) y = y + x print('After split connection, dimensions arentbatchsize:', y.shape[0], 'ntnumber of tokens:', y.shape[1], 'nttoken size:', y.shape[2])
After norm, dimensions are batchsize: 13 number of tokens: 176 token size: 768 After attention, dimensions are batchsize: 13 number of tokens: 176 token size: 768 After split connection, dimensions are batchsize: 13 number of tokens: 176 token size: 768
Now, we pass through another norm layer, and then the Neural Network module. We finish with the second split connection.
z = E.norm2(y) print('After norm, dimensions arentbatchsize:', z.shape[0], 'ntnumber of tokens:', z.shape[1], 'nttoken size:', z.shape[2]) z = E.neuralnet(z) print('After neural net, dimensions arentbatchsize:', z.shape[0], 'ntnumber of tokens:', z.shape[1], 'nttoken size:', z.shape[2]) z = z + y print('After split connection, dimensions arentbatchsize:', z.shape[0], 'ntnumber of tokens:', z.shape[1], 'nttoken size:', z.shape[2])
After norm, dimensions are batchsize: 13 number of tokens: 176 token size: 768 After neural net, dimensions are batchsize: 13 number of tokens: 176 token size: 768 After split connection, dimensions are batchsize: 13 number of tokens: 176 token size: 768
That’s all for a single encoding block! Since the final dimensions are the same as the initial dimensions, the model can easily pass tokens through multiple encoding blocks, as set by the depth hyperparameter.
Neural Network Module
The Neural Network (NN) module is a sub-component of the encoding block. The NN module is very simple, consisting of a fully-connected layer, an activation layer, and another fully-connected layer. The activation layer can be any torch.nn.modules.activation⁷ layer, which is passed as input to the module. The NN module can be configured to change the shape of an input, or to maintain the same shape. We’re not going to step through this code, as neural networks are common in machine learning, and not the focus of this article. However, the code for the NN module is presented below.
Args: in_chan (int): number of channels (features) at input hidden_chan (NoneFloat): number of channels (features) in the hidden layer; if None, number of channels in hidden layer is the same as the number of input channels out_chan (NoneFloat): number of channels (features) at output; if None, number of output channels is same as the number of input channels act_layer(nn.modules.activation): torch neural network layer class to use as activation """
super().__init__()
## Define Number of Channels hidden_chan = hidden_chan or in_chan out_chan = out_chan or in_chan
def forward(self, x): x = self.fc1(x) x = self.act(x) x = self.fc2(x) return x
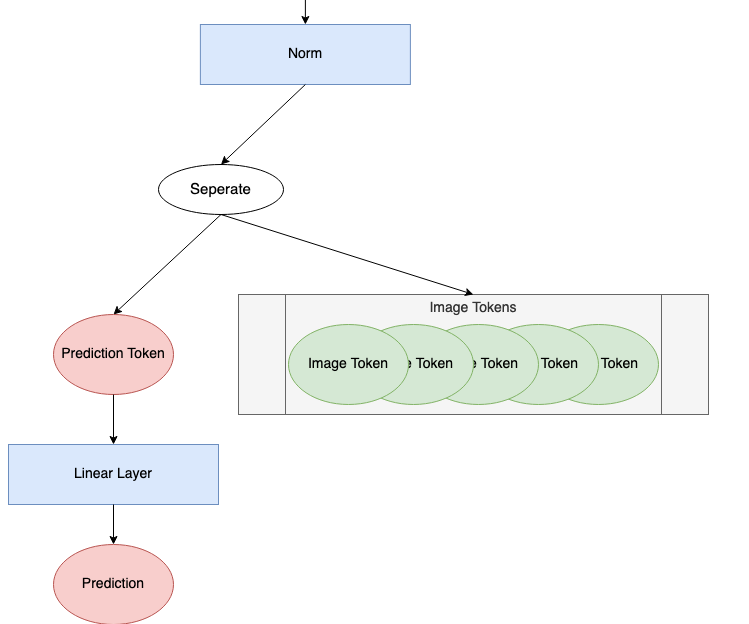
Prediction Processing
After passing through the encoding blocks, the last thing the model must do is make a prediction. The “prediction processing” component of the ViT diagram is shown below.
Prediction Processing Components of ViT Diagram (image by author)
We’re going to look at each step of this process. We’ll continue with 176 tokens of length 768. We’ll use a batch size of 1 to illustrate how a single prediction is made. A batch size greater than 1 would be computing this prediction in parallel.
# Define an Input num_tokens = 176 token_len = 768 batch = 1 x = torch.rand(batch, num_tokens, token_len) print('Input dimensions arentbatchsize:', x.shape[0], 'ntnumber of tokens:', x.shape[1], 'nttoken length:', x.shape[2])
Input dimensions are batchsize: 1 number of tokens: 176 token length: 768
First, all the tokens are passed through a norm layer.
norm = nn.LayerNorm(token_len) x = norm(x) print('After norm, dimensions arentbatchsize:', x.shape[0], 'ntnumber of tokens:', x.shape[1], 'nttoken size:', x.shape[2])
After norm, dimensions are batchsize: 1 number of tokens: 1001 token size: 768
Next, we split off the prediction token from the rest of the tokens. Throughout the encoding block(s), the prediction token has become nonzero and gained information about our input image. We’ll use only this prediction token to make a final prediction.
pred_token = x[:, 0] print('Length of prediction token:', pred_token.shape[-1])
Length of prediction token: 768
Finally, the prediction token is passed through the head to make a prediction. The head, usually some variety of neural network, is varied based on the model. In An Image is Worth 16×16 Words², they use an MLP (multilayer perceptron) with one hidden layer during pretraining and a single linear layer during fine tuning. In Tokens-to-Token ViT³, they use a single linear layer as a head. This example proceeds with a single linear layer.
Note that the output shape of the head is set based on the parameters of the learning problem. For classification, it is typically a vector of length number of classes in a one-hot encoding. For regression, it would be any integer number of predicted parameters. This example will use an output shape of 1 to represent a single estimated regression value.
head = nn.Linear(token_len, 1) pred = head(pred_token) print('Length of prediction:', (pred.shape[0], pred.shape[1])) print('Prediction:', float(pred))
Length of prediction: (1, 1) Prediction: -0.5474240779876709
And that’s all! The model has made a prediction!
Complete Code
To create the complete ViT module, we use the Patch Tokenization module defined above and the ViT Backbone module. The ViT Backbone is defined below, and contains the Token Processing, Encoding Blocks, and Prediction Processingcomponents.
""" VisTransformer Backbone Args: preds (int): number of predictions to output token_len (int): length of a token num_heads(int): number of attention heads in MSA Encoding_hidden_chan_mul (float): multiplier to determine the number of hidden channels (features) in the NeuralNet component of the Encoding Module depth (int): number of encoding blocks in the model qkv_bias (bool): determines if the qkv layer learns an addative bias qk_scale (NoneFloat): value to scale the queries and keys by; if None, queries and keys are scaled by ``head_dim ** -0.5`` act_layer(nn.modules.activation): torch neural network layer class to use as activation norm_layer(nn.modules.normalization): torch neural network layer class to use as normalization """
## Make the class token sampled from a truncated normal distrobution timm.layers.trunc_normal_(self.cls_token, std=.02)
def forward(self, x): ## Assumes x is already tokenized
## Get Batch Size B = x.shape[0] ## Concatenate Class Token x = torch.cat((self.cls_token.expand(B, -1, -1), x), dim=1) ## Add Positional Embedding x = x + self.pos_embed ## Run Through Encoding Blocks for blk in self.blocks: x = blk(x) ## Take Norm x = self.norm(x) ## Make Prediction on Class Token x = self.head(x[:, 0]) return x
From the ViT Backbone module, we can define the full ViT model.
Args: img_size (tuple[int, int, int]): size of input (channels, height, width) patch_size (int): the side length of a square patch token_len (int): desired length of an output token preds (int): number of predictions to output num_heads(int): number of attention heads in MSA Encoding_hidden_chan_mul (float): multiplier to determine the number of hidden channels (features) in the NeuralNet component of the Encoding Module depth (int): number of encoding blocks in the model qkv_bias (bool): determines if the qkv layer learns an addative bias qk_scale (NoneFloat): value to scale the queries and keys by; if None, queries and keys are scaled by ``head_dim ** -0.5`` act_layer(nn.modules.activation): torch neural network layer class to use as activation norm_layer(nn.modules.normalization): torch neural network layer class to use as normalization """ super().__init__()
## Defining ViT Backbone self.backbone = ViT_Backbone(preds, self.token_len, self.num_heads, self.Encoding_hidden_chan_mul, self.depth, qkv_bias, qk_scale, act_layer, norm_layer) ## Initialize the Weights self.apply(self._init_weights)
def _init_weights(self, m): """ Initialize the weights of the linear layers & the layernorms """ ## For Linear Layers if isinstance(m, nn.Linear): ## Weights are initialized from a truncated normal distrobution timm.layers.trunc_normal_(m.weight, std=.02) if isinstance(m, nn.Linear) and m.bias is not None: ## If bias is present, bias is initialized at zero nn.init.constant_(m.bias, 0) ## For Layernorm Layers elif isinstance(m, nn.LayerNorm): ## Weights are initialized at one nn.init.constant_(m.weight, 1.0) ## Bias is initialized at zero nn.init.constant_(m.bias, 0)
@torch.jit.ignore ##Tell pytorch to not compile as TorchScript def no_weight_decay(self): """ Used in Optimizer to ignore weight decay in the class token """ return {'cls_token'}
def forward(self, x): x = self.patch_tokens(x) x = self.backbone(x) return x
In the ViT Model, the img_size, patch_size, and token_len define the Patch Tokenization module.
The num_heads, Encoding_hidden_channel_mul, qkv_bias, qk_scale, and act_layer parameters define the Encoding Bock modules. The act_layer can be any torch.nn.modules.activation⁷ layer. The depth parameter determines how many encoding blocks are in the model.
The norm_layer parameter sets the norm for both within and outside of the Encoding Block modules. It can be chosen from any torch.nn.modules.normalization⁸ layer.
The _init_weights method comes from the T2T-ViT³ code. This method could be deleted to initiate all learned weights and biases randomly. As implemented, the weights of linear layers are initialized as a truncated normal distribution; the biases of linear layers are initialized as zero; the weights of normalization layers are initialized as one; the biases of normalization layers are initialized as zero.
Conclusion
Now, you can go forth and train ViT models with a deep understanding of their mechanics! Below is a list of places to download code for ViT models. Some of them allow for more modifications of the model than others. Happy transforming!
This article was approved for release by Los Alamos National Laboratory as LA-UR-23–33876. The associated code was approved for a BSD-3 open source license under O#4693.
Further Reading
To learn more about transformers in NLP contexts, see
Data Science, Machine Learning, and AI are undeniably buzzwords of today. My LinkedIn is flooded with data gurus sharing learning roadmaps for those eager to break into this data space.
Yet, from my personal experience, I’ve found that the journey towards Data Science isn’t as linear as merely following a fixed roadmap, especially for individuals transitioning from various professional backgrounds. Data Science requires a blend of diverse skills like programming, statistics, math, analytics, soft skills, and domain knowledge. This means that everyone picks up learning from different points depending on their prior experience/skill sets.
As someone who worked in research and analytics for years and pursued a master’s degree in analytics, I have acquired a fair amount of statistical knowledge and its applications. Even then, data science is such a broad and dynamic industry that my knowledge is still all over the place. I struggled to find resources that could effectively fill my knowledge gap between statistics and ML as well. This posed significant challenges to my learning experience.
In this article, I aim to share the technical oversights I encounter as I navigate from research & analytics to data science. Hopefully, my sharing can save you time and help you avoid these pitfalls.
Statistical Modelling Vs Machine Learning
So, you might be wondering why I am starting with a reflection on my journey instead of getting to the point. Well, the reason is simple — I have noticed that many individuals claim to be building ML models when, in reality, they are only crafting statistical models. I confess I was one of them! It’s not like one is better than the other, but I believe it is crucial to recognise the nuances between statistical modelling and ML before I talk about technicalities.
The purpose of statistical models is for making inferences, while the primary goal of Machine Learning is for predictions. Simply put, the ML model leverages statistics and math to generate predictions applicable to real-world scenarios. This is where data splitting and data leakage come into the picture, particularly in the context of supervised Machine Learning.
My initial belief was that understanding statistical analysis was sufficient for prediction tasks. However, I quickly realised that without knowledge of data preparation techniques such as proper data splitting and awareness of potential pitfalls like data leakage, even the most sophisticated statistical models fall short in predictive performance.
So, let’s get started!
Mistake 1: Improper Data Splitting
What is meant by data splitting?
Data splitting, in essence, is dividing your dataset into parts for optimal predictive performance of the model.
Consider a simple OLS regression concept that is familiar to many of us. We all have heard about it in one of the business/stats/finance, economics, or engineering lectures. It is a fundamental ML technique.
Let’s say we have a housing price dataset along with the factors that might affect housing prices.
In traditional statistical analysis, we employ the entire dataset to develop a regression model, as our goal is just to understand what factors influence housing prices. In other words, regression models can explain what degree of changes in prices are associated with the predictors.
However, in ML, the statistical part remains the same, but data splitting becomes crucial. Let me explain why — imagine we train the model on the entire set; how would we know the predictive performance of the model on unseen data?
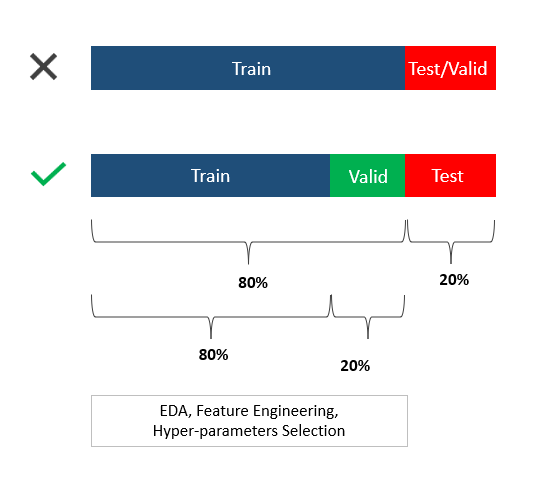
For this very reason, we typically split the dataset into two sets: training and test sets. The idea is to train the model on one set and evaluate its performance on the other set. Essentially, the test set should serve as real-world data, meaning the model should not have access to the test data in any way throughout the training phase.
Here comes the pitfall that I wasn’t aware of before. Splitting data into two sets is not inherently wrong, but there is a risk of creating an unreliable model. Imagine you train the model on the training set, validate its accuracy on the test set, and then repeat the process to fine-tune the model. This creates a bias in model selection and defeats the whole purpose of “unseen data” because test data was seen multiple times during model development. It undermines the model’s ability to genuinely predict the unseen data, leading to overfitting issues.
How to prevent it:
Ideally, the dataset should be divided into two blocks (three distinct splits):
( Training set + Validation set) → 1st block
Test set → 2nd block
The model can be trained and validated on the 1st block. The 2nd block (the test set) should not be involved in any of the model training processes. Think of the test set as a danger zone!
How you want to split the data is dependent on the size of the dataset. The industry standard is 60% — 80 % for the training set (1st block) and 20% — 40% for the test set. The validation set is normally curved out of the 1st block so the actual training set would be 70% — 90% out of the 1st block , and the rest is for the validation set.
The best way to grasp this concept is through a visual:
Leave-One-Out (LOOV) method (Image by the author)
There is more than one data-splitting technique other than LOOV (in the picture):
K-fold Cross-validation, which divides the data into a number of ‘K’ folds and iterates the training processes accordingly
Rolling Window Cross-validation (for time-series data)
Blocked Cross-validation (for time-series data)
Stratified Sampling Splitting for imbalanced classes
Note: Time series data needs extra caution when splitting data due to its temporal order. Randomly splitting the dataset can mess up its time order. (I learnt it the hard way)
The most important thing is regardless of the techniques you use, the “test set” should be kept separate and untouched until the model selection.
Mistake 2: Data Leakage
“In Machine learning, Data Leakage refers to a mistake that is made by the creator of a machine learning model in which they accidentally share the information between the test and training data sets.” — Analytics Vidhya
This is connected to my first point about test data being contaminated by training data. It’s one example of data leakage. However, having a validation set alone can’t avoid data leakage.
In order to prevent data leakage, we need to be careful with the data handling process — from Exploratory Data Analysis (EDA) to Feature Engineering. Any procedure that allows the training data to interact with the test data could potentially lead to leakage.
There are two main types of leakage:
Train-test-contamination
A common mistake I made involved applying a standardisation/pre-processing procedure to the entire set before data splitting. For example, using mean imputation to handle missing values/ outliers on the whole dataset. This makes the training data incorporate information from the test data. As a result, the model’s accuracy is inflated compared to its real-life performance.
2. Target leakage
If the features (predictors) have some dependency on the variable that we want to predict (target), or if the features data will not be available at the time of prediction, this can result in target leakage.
Let’s look at the data I worked on as an example. Here, I was trying to predict sales performance based on advertising campaigns. I tried to include the conversion rates. I overlooked the fact that conversion rates are only known post-campaign. In other words, I won’t have this information at the time of forecasting. Plus, because conversion rates are tied to sales data, this introduces a classic case of target leakage. Including conversion rates would lead the model to learn from data that would not be normally accessible, resulting in overly optimistic predictions.
Sample (made-up) Dataset (Image by the author)
How to prevent data leakage:
In summary, keep these points in mind to address data leakage issues:
Proper Data Preprocessing
Cross-validation with care
Careful Feature Selection
Closing Thoughts
That’s about it! Thanks for sticking with me till the end! I hope this article clarifies the common misconceptions around data splitting and sheds light on the best practices in building efficient ML models.
This is not just for documenting my learning journey but also for mutual learning. So, if you spot a gap in my technical know-how or have any insights to share, feel free to drop me a message!
It was once possible to sign up for Netflix directly in the iPhone app, but anyone still holding on to that plan has lost access and must sign up directly on the Netflix website.
Netflix
Netflix ended the ability to subscribe from within its iOS app in 2018. The move was made to avoid Apple’s in-app subscription commission of 30%, which reduces to 15% after a subscriber pays for a year.
According to a report from The Verge, Netflix has finally ended support for grandfathered accounts that still used the in-app subscription payment option. New users haven’t been able to use the method since its removal in 2018, but anyone who didn’t change their subscription or end it since was still paying from their Apple payment method.
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept”, you consent to the use of ALL the cookies.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checkbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.