TLDR Manta Network surges 53% in a week, but a pullback is imminent. Rebel Satoshi continues attracting investors after surging 120% thus far. As most top altcoins continue bleeding, Manta Network (MANTA) has performed incredibly well over the past week. As a result, investors are flocking to its market, hoping to make significant profits soon. […]
UwU Lend, the decentralized and innovative lending platform, is proud to announce the return of the Curve ecosystem, along with its new stablecoin crvUSD! Moreover, with this exciting step forward as one of the first lending platforms to add crvUSD. UwU Lend aims to support the stabilization and growth of the Curve ecosystem while offering […]
The Singapore High Court has rejected Three Arrows Capital’s (3AC) motion to dismiss a lawsuit filed by Arthur Cheong, founder of the web3 investment firm DeFiance Capital. The latest decision marks a pivotal moment in the ongoing legal battle between…
Ben Armstrong, known in the cryptocurrency world as Bitboy, has announced the cessation of his daily live stream. Armstrong’s decision comes amid a flurry of personal and legal challenges, including a significant financial strain due to the production costs of…
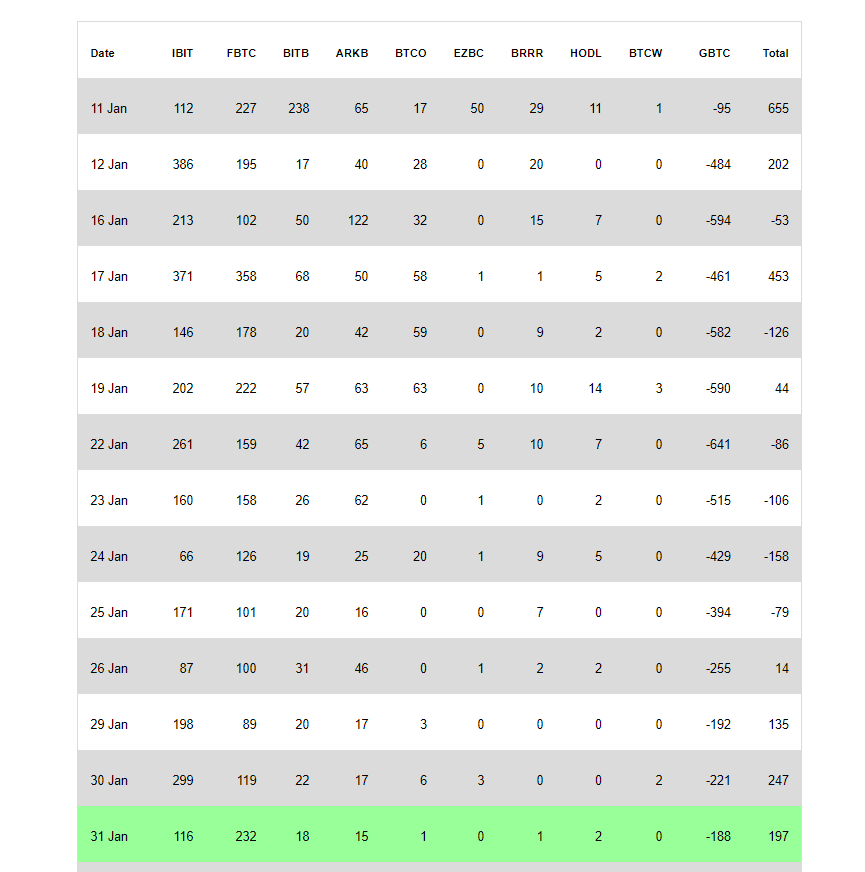
Quick Take Day 14 for the new Bitcoin ETFs marked another day of net inflows, with a considerable $197 million entering the market on Jan. 31, according to Whale Panda. This marks the fourth successive trading day of net inflows, underlining a trend in the market’s dynamic. Among the prominent contributors, BlackRock’s IBIT showed a […]
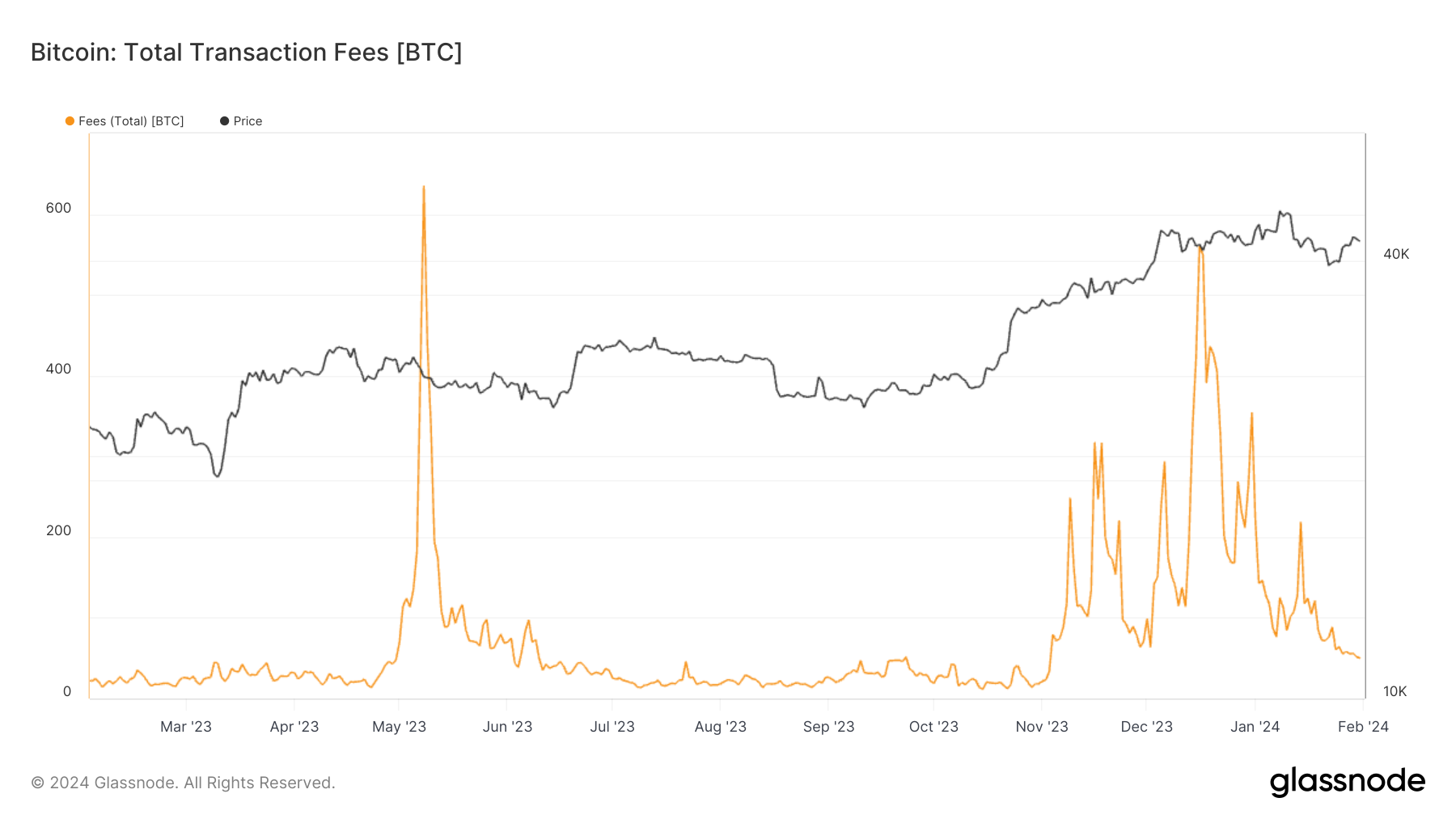
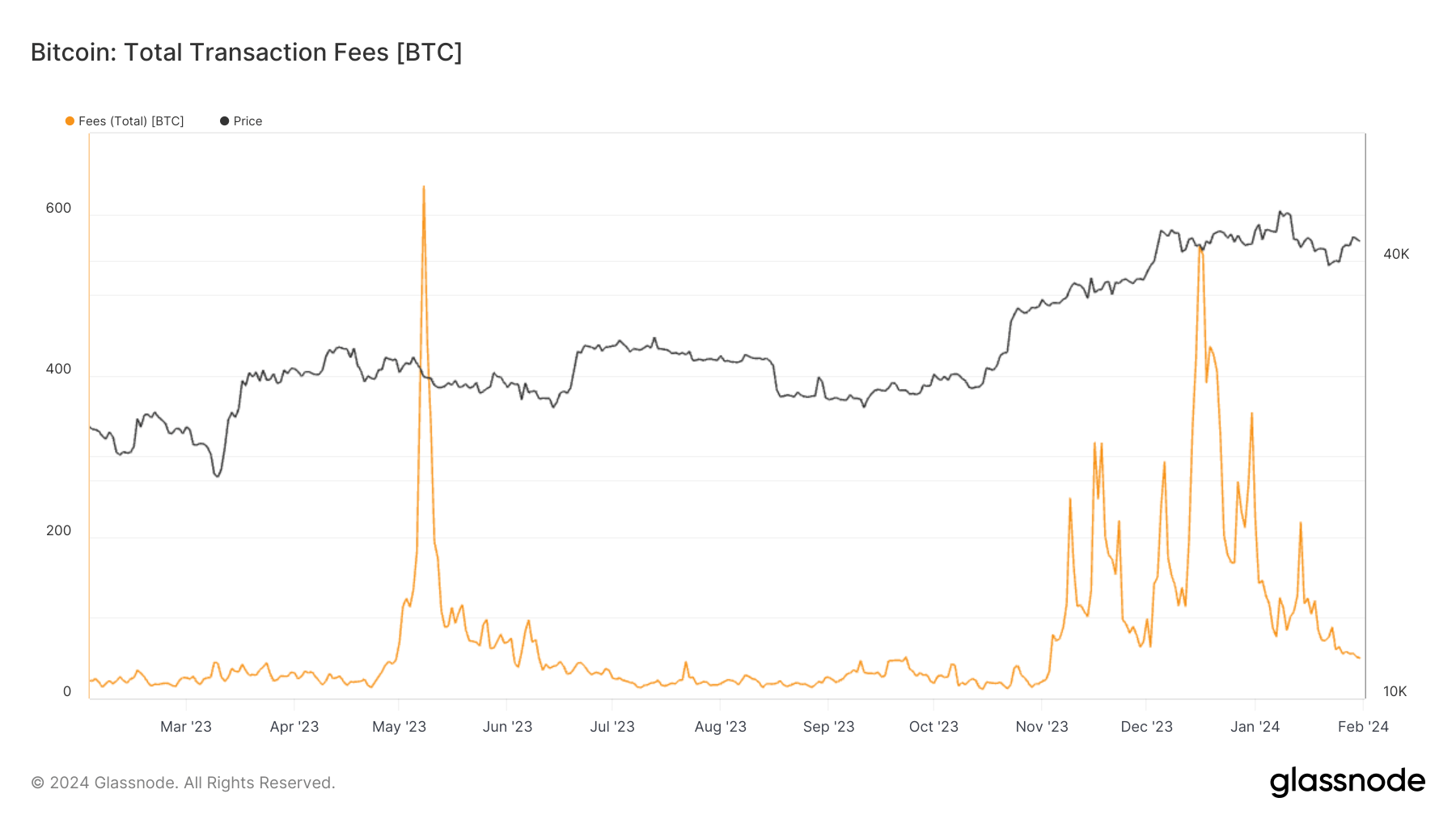
Quick Take A compelling trend emerged in the Bitcoin landscape in 2023, marked by two distinct spikes in mining fees – one in May and the other in November. Both were directly correlated to a surge in Bitcoin inscriptions, with the May frenzy subsiding after a month, while the November surge endured for approximately two […]
This is a sequel to a recent post on the topic of building custom, cloud-based solutions for machine learning (ML) model development using low-level instance provisioning services. Our focus in this post will be on Amazon EC2.
Cloud service providers (CSPs) typically offer fully managed solutions for training ML models in the cloud. Amazon SageMaker, for example, Amazon’s managed service offering for ML development, simplifies the process of training significantly. Not only does SageMaker automate the end-to-end training execution — from auto-provisioning the requested instance types, to setting up the training environment, to running your training workload, to saving the training artifacts and shutting everything down — but it also offers a number of auxiliary services that support ML development, such as automatic model tuning, platform optimized distributed training libraries, and more. However, as is often the case with high-level solutions, the increased ease-of-use of SageMaker training is coupled with a certain level of loss of control over the underlying flow.
In our previous post we noted some of the limitations sometimes imposed by managed training services such as SageMaker, including reduced user privileges, inaccessibility of some instance types, reduced control over multi-node device placement, and more. Some scenarios require a higher level of autonomy over the environment specification and training flow. In this post, we illustrate one approach to addressing these cases by creating a custom training solution built on top of Amazon EC2.
Many thanks to Max Rabin for his contributions to this post.
Poor Man’s Managed Training on Amazon EC2
In our previous post we listed a minimal set of features that we would require from an automated training solution and proceeded to demonstrate, in a step-by-step manner, one way of implementing these in Google Cloud Platform (GCP). And although the same sequence of steps would apply to any other cloud platform, the details can be quite different due to the unique nuances of each one. Our intention in this post will be to propose an implementation based on Amazon EC2 using the create_instances command of the AWS Python SDK (version 1.34.23). As in our previous post, we will begin with a simple EC2 instance creation command and gradually supplement it with additional components that will incorporate our desired management features. The create_instances command supports many controls. For the purposes of our demonstration, we will focus only on the ones that are relevant to our solution. We will assume the existence of a default VPC and an IAM instance profile with appropriate permissions (including access to Amazon EC2, S3, and CloudWatch services).
Note that there are multiple ways of using Amazon EC2 to fulfill the minimal set of features that we defined. We have chosen to demonstrate one possible implementation. Please do not interpret our choice of AWS, EC2, or any details of the specific implementation we have chosen as an endorsement. The best ML training solution for you will greatly depend on the specific needs and details of your project.
1. Create an EC2 Instance
We begin with a minimal example of a single EC2 instance request. We have chosen a GPU accelerated g5.xlarge instance type and a recent Deep Learning AMI (with an Ubuntu 20.4 operating system).
import boto3
region = 'us-east-1' job_id = 'my-experiment' # replace with unique id num_instances = 1 image_id = 'ami-0240b7264c1c9e6a9' # replace with image of choice instance_type = 'g5.xlarge' # replace with instance of choice
The first enhancement we would like to apply is for our training workload to automatically start as soon as our instance is up and running, without any need for manual intervention. Towards this goal, we will utilize the UserData argument of the create_instances API that enables you to specify what to run at launch. In the code block below, we propose a sequence of commands that sets up the training environment (i.e., updates the PATH environment variable to point to the prebuilt PyTorch environment included in our image), downloads our training code from Amazon S3, installs the project dependencies, runs the training script, and syncs the output artifacts to persistent S3 storage. The demonstration assumes that the training code has already been created and uploaded to the cloud and that it contains two files: a requirements file (requirements.txt) and a stand-alone training script (train.py). In practice, the precise contents of the startup sequence will depend on the project. We include a pointer to our predefined IAM instance profile which is required for accessing S3.
import boto3
region = 'us-east-1' job_id = 'my-experiment' # replace with unique id num_instances = 1 image_id = 'ami-0240b7264c1c9e6a9' # replace with image of choice instance_type = 'g5.xlarge' # replace with instance of choice instance_profile_arn = 'instance-profile-arn' # replace with profile arn
Note that the script above syncs the training artifacts only at the end of training. A more fault-tolerant solution would sync intermediate model checkpoints throughout the training job.
3. Self-destruct on Completion
When you train using a managed service, your instances are automatically shut down as soon as your script completes to ensure that you only pay for what you need. In the code block below, we append a self-destruction command to the end of our UserData script. We do this using the AWS CLI terminate-instances command. The command requires that we know the instance-id and the hosting region of our instance which we extract from the instance metadata. Our updated script assumes that our IAM instance profile has appropriate instance-termination authorization.
We highly recommend introducing additional mechanisms for verifying appropriate instance deletion to avoid the possibility of having unused (“orphan”) instances in the system racking up unnecessary costs. In a recent post we showed how serverless functions can be used to address this kind of problem.
4. Apply Custom Tags to EC2 Instances
Amazon EC2 enables you to apply custom metadata to your instance using EC2 instance tags. This enables you to pass information to the instance regarding the training workload and/or the training environment. Here, we use the TagSpecifications setting to pass in an instance name and a unique training job id. We use the unique id to define a dedicated S3 path for our job artifacts. Note that we need to explicitly enable the instance to access the metadata tags via the MetadataOptions setting.
import boto3
region = 'us-east-1' job_id = 'my-experiment' # replace with unique id num_instances = 1 image_id = 'ami-0240b7264c1c9e6a9' # replace with image of choice instance_type = 'g5.xlarge' # replace with instance of choice instance_profile_arn = 'instance-profile-arn' # replace with profile arn
Using metadata tags to pass information to our instances will be particularly useful in the next sections.
5. Write Application Logs to Persistent Storage
Naturally, we require the ability to analyze our application’s output logs both during and after training. This requires that they be periodically synced to persistent logging. In this post we implement this using Amazon CloudWatch. Below we define a minimum JSON configuration file for enabling CloudWatch log collection which we add to our source code tar-ball as cw_config.json. Please see the official documentation for details on CloudWatch setup and configuration.
In practice, we would like the log_stream_name to uniquely identify the training job. Towards that end, we use the sed command to replace the generic “job-id” string with the job id metadata tag from the previous section. Our enhanced script also includes the CloudWatch start up command and modifications for piping the standard output to the designated output.log defined in the CloudWatch config file.
Nowadays, it is quite common for training jobs to run on multiple nodes in parallel. Modifying our instance request code to support multiple nodes is a simple matter of modifying the num_instances setting. The challenge is how to configure the environment in a manner that supports distributed training, i.e., a manner that enables — and optimizes — the transfer of data between the instances.
To minimize the network latency between the instances and maximize throughput, we add a pointer to a predefined cluster placement group in the Placement field of our ec2 instance request. The following command line demonstrates the creation of a cluster placement group.
For our instances to communicate with one another, they need to be aware of each other’s presence. In this post we will demonstrate a minimal environment configuration required for running data parallel training in PyTorch. For PyTorch DistributedDataParallel (DDP), each instance needs to know the IP of the master node, the master port, the total number of instances, and its serial rank amongst all of the nodes. The script below demonstrates the configuration of a data parallel training job using the environment variables MASTER_ADDR, MASTER_PORT, NUM_NODES, and NODE_RANK.
import os, ast, socket import torch import torch.distributed as dist import torch.multiprocessing as mp
if __name__ == '__main__': mp.spawn(mp_fn, args=(), nprocs=torch.cuda.device_count())
The node rank can be retrieved from the ami-launch-index. The number of nodes and the master port are known at the time of create_instances invocation and can be passed in as EC2 instance tags. However, the IP address of the master node is only determined once the master instance is created and can only be communicated to the instances following the create_instances call. In the code block below, we chose to pass the master address to each of the instances using a dedicated call to the AWS Python SDKcreate_tags API. We use the same call to update the name tag of each instance according to its launch-index value.
The full solution for multi-node training appears below:
import boto3
region = 'us-east-1' job_id = 'my-multinode-experiment' # replace with unique id num_instances = 4 image_id = 'ami-0240b7264c1c9e6a9' # replace with image of choice instance_type = 'g5.xlarge' # replace with instance of choice instance_profile_arn = 'instance-profile-arn' # replace with profile arn placement_group = 'cluster-placement-group' # replace with placement group
# download and unpack code aws s3 cp s3://my-s3-path/$JOB_ID/my-code.tar . tar -xvf my-code.tar
# configure cloudwatch sed -i "s/job-id/${JOB_ID}_${NODE_RANK}/g" cw_config.json /opt/aws/amazon-cloudwatch-agent/bin/amazon-cloudwatch-agent-ctl -a fetch-config -m ec2 -c file:cw_config.json -s
# install dependencies python3 -m pip install -r requirements.txt 2>&1 | tee -a output.log
# retrieve master address # should be available but just in case tag application is delayed... while true; do export MASTER_ADDR=$(curl $CURL_FLAGS $INST_MD/tags/instance/MASTER_ADDR) if [[ $MASTER_ADDR == "<?xml"* ]]; then echo 'tags missing, sleep for 5 seconds' 2>&1 | tee -a output.log sleep 5 else break fi done
# run training workload python3 train.py 2>&1 | tee -a output.log
# find master_addr for inst in instances: if inst.ami_launch_index == 0: master_addr = inst.network_interfaces_attribute[0]['PrivateIpAddress'] break
# update ec2 tags for inst in instances: res = ec2.create_tags( Resources=[inst.id], Tags=[ {'Key': 'NAME', 'Value': f'test-vm-{inst.ami_launch_index}'}, {'Key': 'MASTER_ADDR', 'Value': f'{master_addr}'}] )
7. Support Spot Instance Usage
A popular way of reducing training costs is to use discounted Amazon EC2 Spot Instances. Utilizing Spot instances effectively requires that you implement a way of detecting interruptions (e.g., by listening for termination notices) and taking the appropriate action (e.g., resuming incomplete workloads). Below, we show how to modify our script to use Spot instances using the InstanceMarketOptions API setting.
import boto3
region = 'us-east-1' job_id = 'my-spot-experiment' # replace with unique id num_instances = 1 image_id = 'ami-0240b7264c1c9e6a9' # replace with image of choice instance_type = 'g5.xlarge' # replace with instance of choice instance_profile_arn = 'instance-profile-arn' # replace with profile arn placement_group = 'cluster-placement-group' # replace with placement group
Please see our previous posts (e.g., here and here) for some ideas for how to implement a solution for Spot instance life-cycle management.
Summary
Managed cloud services for AI development can simplify model training and lower the entry bar for potential incumbents. However, there are some situations where greater control over the training process is required. In this post we have illustrated one approach to building a customized managed training environment on top of Amazon EC2. Of course, the precise details of the solution will greatly depend on the specific needs of the projects at hand.
As always, please feel free to respond to this post with comments, questions, or corrections.
Sick of mistaking legit calls for spam? This new AT&T wireless service might help
Originally appeared here:
Sick of mistaking legit calls for spam? This new AT&T wireless service might help
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept”, you consent to the use of ALL the cookies.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checkbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.