The top Web3 trading wallet, Bitget Wallet, has recently connected with the EVM-compatible Layer 1 blockchain, Berachain Artio Testnet. Users of Bitget Wallet may now easily add the testnet to their wallets using the Bitget Wallet app and browser extension. This enables users to take advantage of easy-to-use on-chain asset management, transfers, and DApp engagement, […]
$4.2 million worth of XRP tokens stolen during a hack on Ripple executive’s personal accounts earlier this week have been identified and frozen, revealed Binance CEO Richard Teng.
A Quantitatively Accurate and Clinically Useful Generative Medical Imaging Model
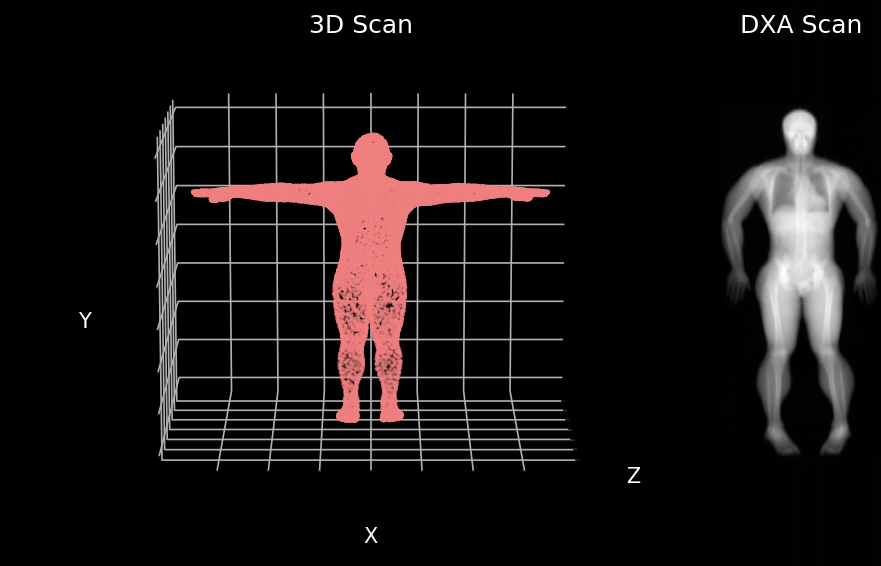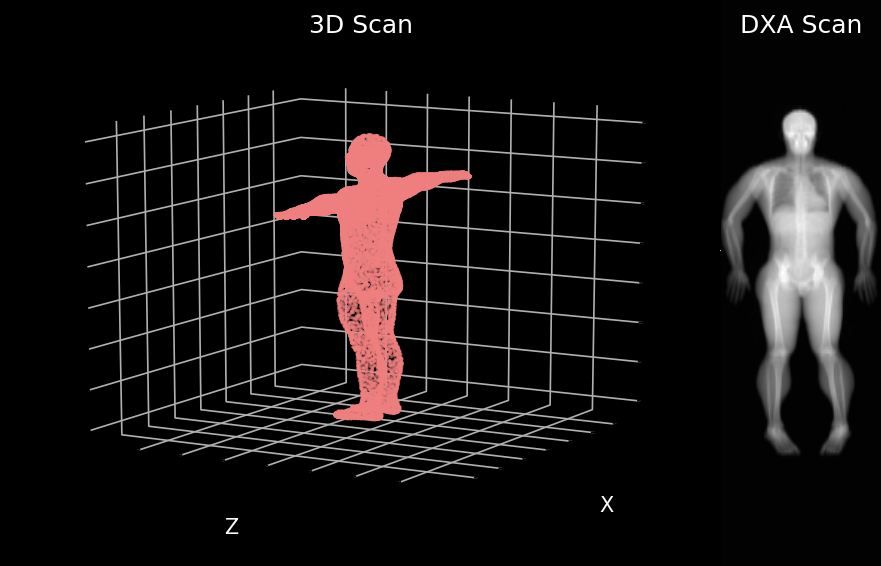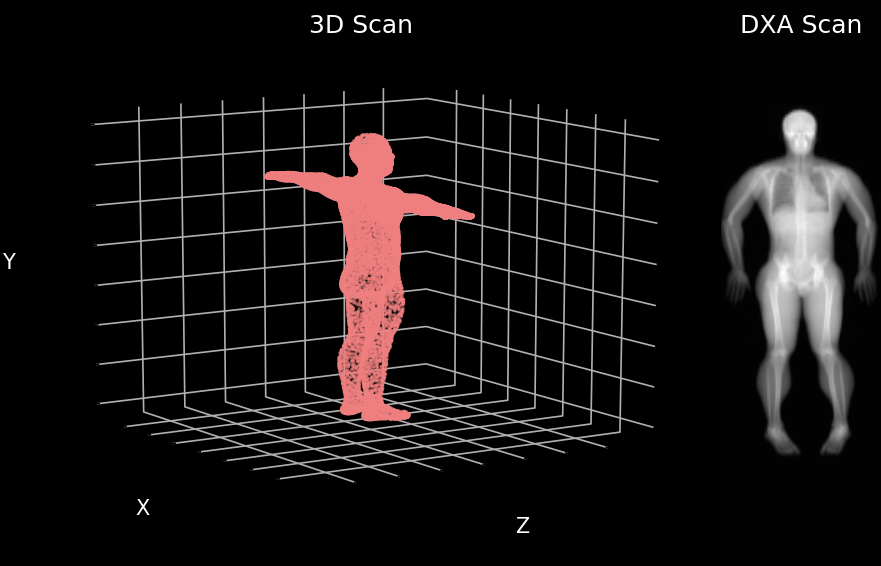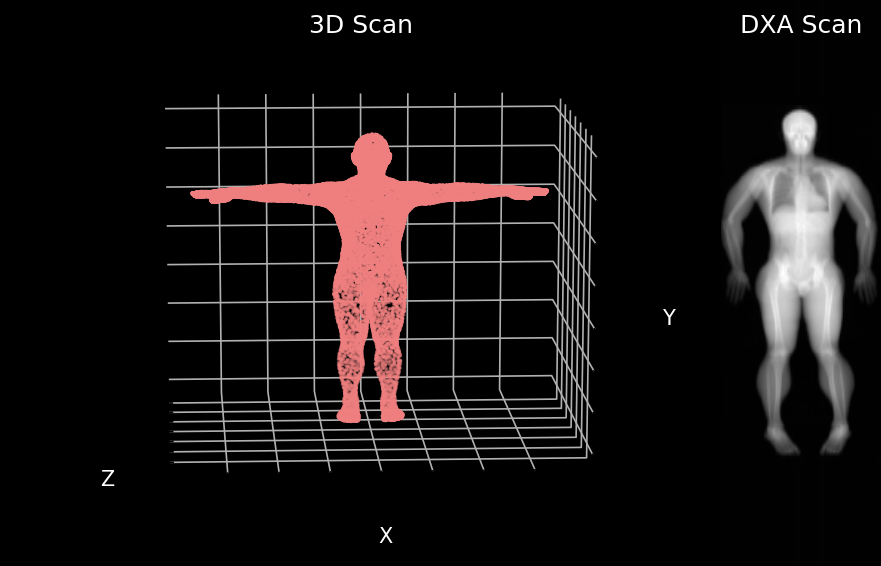
3D body surface scan point cloud and matching dual energy X-ray absorptiometry (DXA) scan (Image by Author)
Key Points
To our knowledge, this is the first quantitatively accurate model in which generated medical imaging can be analyzed with commercial clinical software.
Being able to predict interior distributions of fat, muscle, and bone from exterior shape, indicates the strong relationship between body composition and body shape
This model represents a significant step towards accessible health monitoring, producing images that would normally require specialized, expensive equipment, trained technicians, and involve exposure to potentially harmful ionizing radiation.
Generative artificial intelligence (AI) has become astonishingly popular especially after the release of both diffusion models like DALL-E and large language models (LLM) like ChatGPT. In general, AI models are classified as “generative” when the model produces something as an output. For DALL-E the product output is a high-quality image while for ChatGPT the product or output is highly structured meaningful text. These generative models are different than classification models that output a prediction for one side of a decision boundary such as cancer or no cancer and these are also different from regression models that output numerical predictions such as blood glucose level. Medical imaging and healthcare have benefited from AI in general and several compelling use cases and generative models are constantly being developed. A major barrier to clinical use of generative AI models is a lack of validation of model outputs beyond just image quality assessments. In our work, we evaluate our generative model on both a qualitative and quantitative assessment as a step towards more clinically relevant AI models.
Quality vs Quantity
In medical imaging, image quality is crucial; it’s all about how well the image represents the internal structures of the body. The majority of the use cases for medical imaging is predicated on having images of high quality. For instance, X-ray scans use ionizing radiation to produce images of many internal structures of the body and quality is important for identifying bone from soft tissue or organs as well as identifying anomalies like tumors. High quality X-ray images result in easier to identify structures which can translate to more accurate diagnosis. Computer vision research has led to the development of metrics meant to objectively measure image quality. These metrics, which we use in our work, include peak signal to noise ratio (PSNR) and structural similarity index (SSIM), for example. Ultimately, a high-quality image can be defined as having sharp, well defined borders, with good contrast between different anatomical structures.
Images are highly structured data types and made up of a matrix of pixels of varying intensities. Unlike natural images as seen in the ImageNet dataset consisting of cars, planes, boats, and etc. which have three red, green, and blue color channels, medical images are mostly gray scale or a single channel. Simply put, sharp edges are achieved by having pixels near the borders of structures be uniform and good contrast is achieved when neighboring pixels depicting different structures have a noticeable difference in value from one another. It is important to note that the absolute value of the pixels are not the most important thing for high quality images and it is in fact more dependent on the relative pixel intensities to each other. This, however, is not the case for achieving images with high quantitative accuracy.
Demonstrating the difference between quality and quantity. Both images look the same and are of good quality but the one on the right gives the right biological measurements of bone, muscle, and fat. (Image by Author)
A subset of medical imaging modalities is quantitative meaning the pixel values represent a known quantity of some material or tissue. Dual energy X-ray Absorptiometry (DXA) is a well known and common quantitative imaging modality used for measuring body composition. DXA images are acquired using high and low energy X-rays. Then a set of equations sometimes refered to as DXA math is used to compute the contrast and ratios between the high and low energy X-ray images to yield quantities of fat, muscle, and bone. Hence the word quantitative. The absolute value of each pixel is important because it ultimately corresponds to a known quantity of some material. Any small changes in the pixel values, while it may still look of the same or similar quality, will result in noticeably different tissue quantities.
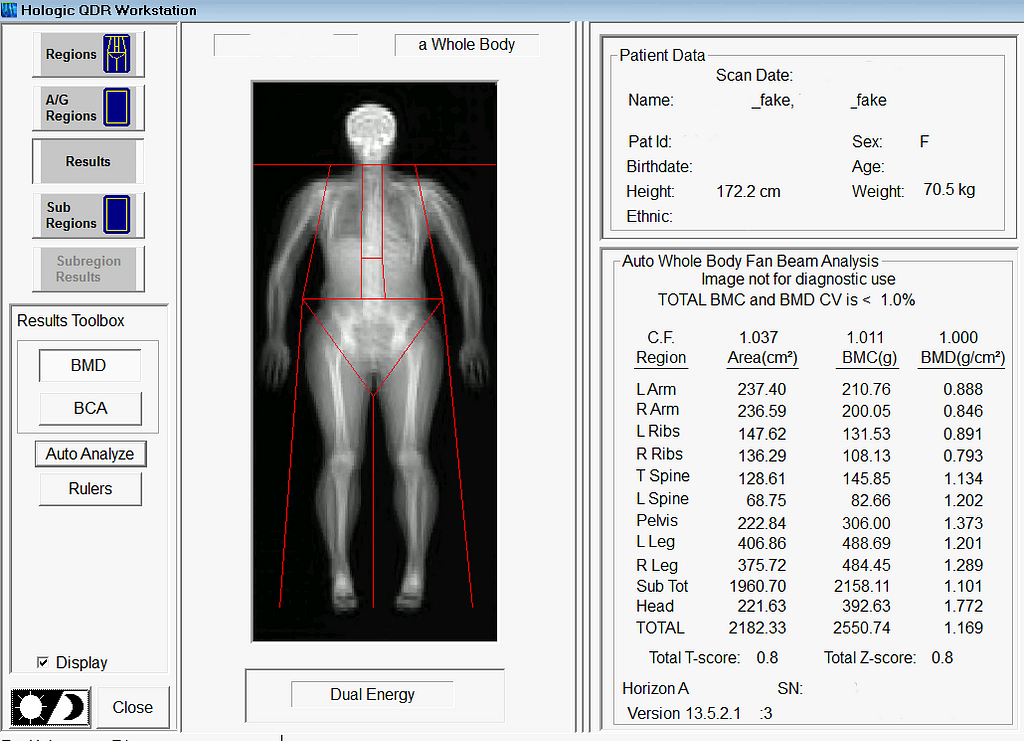
Example of commercial software that is used clinically to measure body composition. In this example, we are demonstrating the ability to load and analyze our Pseudo-DXA generated image. (Image by Author)
Generative AI in Medical Imaging
As previously mentioned, generative AI models for medical imaging are at the forefront of development. Known examples of generative medical models include models for artifact removal from CT images or the production of higher quality CT images from low dose modalities where image quality is known to be lesser in quality. However, prior to our study, generative models creating quantitatively accurate medical images were largely unexplored. Quantitative accuracy is arguably more difficult for generative models to achieve than producing an image of high quality. Anatomical structures not only have to be in the right place, but the pixels representing their location needs to be near perfect as well. When considering the difficulty of achieving quantitative accuracy one must also consider the bit depth of raw medical images. The raw formats of some medical imaging modalities, DXA included, encode information in 12 or 14 bit which is magnitudes more than standard 8-bit images. High bit depths equate to a bigger search space which could equate to it being more difficult to get the exact pixel value. We are able to achieve quantitative accuracy through self-supervised learning methods with a custom physics or DXA informed loss function described in this work here. Stay tuned for a deep dive into that work to come in the near future.
What We Did
We developed a model that can predict your insides from your outsides. In other words, our model innovatively predicts internal body composition from external body scans, specifically transforming three-dimensional (3D) body surface scans into fully analyzable DXA scans. Utilizing increasingly common 3D body scanning technologies, which employ optical cameras or lasers, our model bypasses the need for ionizing radiation. 3D scanning enables accurate capture of one’s exterior body shape and the technology has several health relevant use cases. Our model outputs a fully analyzable DXA scan which means that existing commercial software can be used to derive body composition or measures of adipose tissue (fat), lean tissue (muscle), and bone. To ensure accurate body composition measurements, our model was designed to achieve both qualitative and quantitative precision, a capability we have successfully demonstrated.
Inspiration and Motivation
The genesis of this project was motivated by the hypothesis that your body shape or exterior phenotype is determined by the underlying distribution of fat, muscle, and bone. We had previously conducted several studies demonstrating the associations of body shape to measured quantities of muscle, fat, and bone as well as to health outcomes such as metabolic syndrome. Using principal components analysis (PCA), through shape and appearance modeling, and linear regression, a student in our lab showed the ability to predict body composition images from 3D body scans. While this was impressive and further strengthened the notion of the relationship between shape and composition, these predicted images excluded the forelimbs (elbow to hand and knee to feet) and the images were not in a format (raw DXA format) which enabled analysis with clinical software. Our work fully extends and overcomes previous limitations. The Pseudo-DXA model, as we call it, is able to generate the full whole body DXA image from 3D body scan inputs which can be analyzed from using clinical and commercial software.
Very early proof-of-concept 3D to DXA image translation which sparked this whole project. (Image by Author)
Our Training Data
The cornerstone of the Pseudo-DXA model’s development was a unique dataset comprising paired 3D body and DXA scans, obtained simultaneously. Such paired datasets are uncommon, due to the logistical and financial challenges in scanning large patient groups with both modalities. We worked with a modest but significant sample size: several hundred paired scans. To overcome the data scarcity issue, we utilized an additional, extensive DXA dataset with over 20,000 scans for model pretraining.
Building the Model
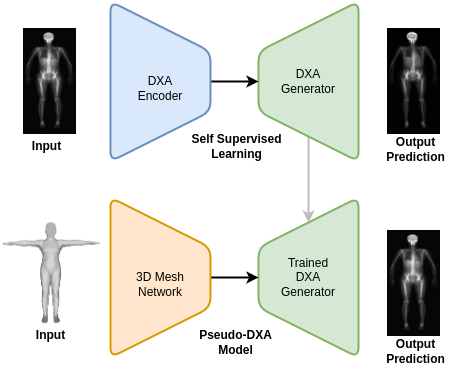
The Pseudo-DXA model was built in two steps. The first self-supervised learning (SSL) or pretraining step involved training a variational auto encoder (VAE) to encode and decode or regenerate raw DXA scan. A large DXA data set, which is independent of the data set used in the final model and evaluation of our model, was used to SSL pretrain our model and it was divided to contain an separate hold out test set. Once the VAE model was able to accurately regenerate the original raw DXA image as validated with the holdout test set, we moved to the second phase of training.
In brief, VAE models consist of two main subnetwork components which include the encoder and the decoder, also known as a generator. The encoder is tasked with taking the high dimensional raw DXA image data and learning a meaningful compressed representation which is encoded into what is known as a latent space. The decoder or generator takes the latent space representation and learns to regenerate the original image from the compressed representation. We used the trained generator from our SSL DXA training as the base of our final Pseudo-DXA model.
Model architecture diagram with the first self-supervised learning phase at the top and the Pseudo-DXA training phase at the bottom. (Image by Author)
The structure of the 3D body scan data consisted of a series of vertices or points and faces which indicate which points are connected to one another. We used a model architecture resembling the Pointnet++ model which has demonstrated the ability to handle point cloud data well. The Pointnet++ model was then attached to the generator we had previously trained. We then fed the mode the 3D data and it was tasked with learning generate the corresponding DXA scan.
Pseudo-DXA Results
In alignment with machine learning best practices, we divided our data such that we had an unseen holdout test for which we reported all our results on.
Image quality
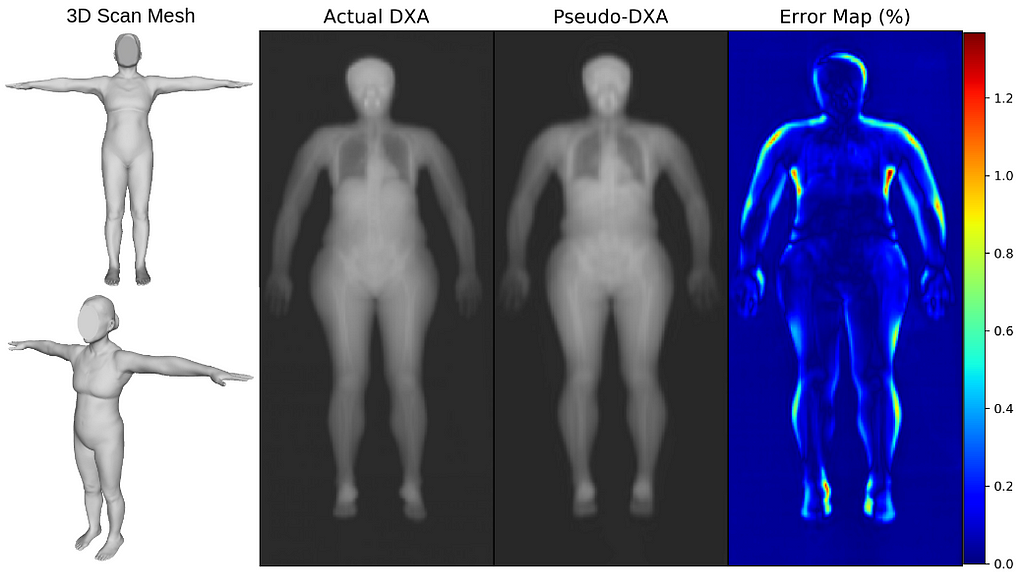
We first evaluated our Pseudo-DXA images using image quality metrics which include normalized mean absolute error (NMAE), peak signal to noise ratio (PSNR), and structural similarity index (SSIM). Our model generated images had mean NMAE, PSNR, and SSIM of 0.15, 38.15, and 0.97, respectively, which is considered to be good with respect to quality. Shown below is an example of a 3D scan, the actual DXA low energy scan, Pseudo-DXA low energy scan and the percent error map of the two DXA scans. As mentioned DXA images have two image channels for high and low energies yet, these examples are just showing the low energy image. Long story short, the Pseudo-DXA model can generate high quality images on par with other medical imaging models with respect to the image quality metrics used.
3D scan from the test set, their actual DXA scan, the Pseudo-DXA scan, and error map comparing the actual to the Pseudo-DXA. (Image by Author)
Quantitative Accuracy
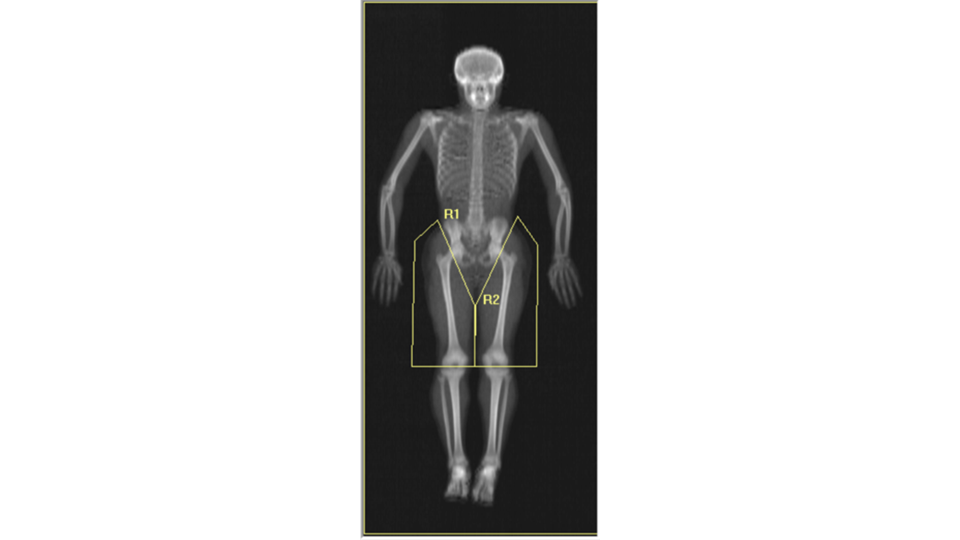
When we analyzed our Pseudo-DXA images for composition and compare the quantities to the actual quantities we achieved coefficients of determination (R²) of 0.72, 0.90, 0.74, and 0.99 for fat, lean, bone, and total mass, respectively. An R²of 1 is desired and our values were reasonably close considering the difficulty of the task. A comment we encountered when presenting our preliminary findings at conferences was “wouldn’t it be easier to simply train a model to predict each measured composition value from the 3D scan so the model would for example, output a quantity of fat and bone and etc., rather than a whole image”. The short answer to the question is yes, however, that model would not be as powerful and useful as the Pseudo-DXA model that we are presenting here. Predicting a whole image demonstrates the strong relationship between shape and composition. Additionally, having a whole image allows for secondary analysis without having to retrain a model. We demonstrate the power of this by performing ad-hoc body composition analysis on two user defined leg subregions. If we had trained a model to just output scalar composition values and not an image, we would only be able to analysis these ad-hoc user defined regions by retraining a whole new model for these measures.
Example of secondary analysis with user defined subregions of the leg labeled R1 and R2. (Image by Author)
Long story short, the Pseudo-DXA model produced high quality images that were quantitatively accurate, from which software could measure real amounts of fat, muscle, and bone.
So What Does This All Mean?
The Pseudo-DXA model marks a pivotal step towards a new standard of striving for quantitative accuracy when necessary. The bar for good generative medical imaging models was high image quality yet, as we discussed, good quality may simply not be enough given the task. If the clinical task or outcome requires something to be measured from the image beyond morphology or anthropometry, then quantitative accuracy should be assessed.
Our Pseudo-DXA model is also a step in the direction of making health assessment more accessible. 3D scanning is now in phones and does not expose individuals to harmful ionizing radiation. In theory, one could get a 3D scan of themselves, run in through our models, and receive a DXA image from which they can obtain quantities of body composition. We acknowledge that our model generates statistically likely images and it is not able to predict pathologies such as tumors, fractures, or implants, which are statistically unlikely in the context of a healthy population from which this model was built. Our model also demonstrated great test-retest precision which means it has the ability to monitor change over time. So, individuals can scan themselves every day without the risk of radiation and the model is robust enough to show changes in composition, if any.
We invite you to engage with this groundbreaking technology and/or provided an example of a quantitatively accurate generative medical imaging model. Share your thoughts, ask questions, or discuss potential applications in the comments. Your insights are valuable to us as we continue to innovate in the field of medical imaging and AI. Join the conversation and be part of this exciting journey!
Few know the risks of working in the ocean better than Sam Mayall. A sailor since he was a boy, Mayall has witnessed several treacherous accidents offshore — some of which were fatal. That’s what drew the young deckhand to found Zelim in 2017. The startup’s technology aims to make remote-controlled search and rescue the norm — keeping people out of danger while, ultimately, saving lives. Zelim, based out of Edinburgh, recently inked a deal with offshore wind giant Ocean Winds to trial its AI-powered person-overboard detection technology at a floating wind farm off the coast of Portugal. Using footage…
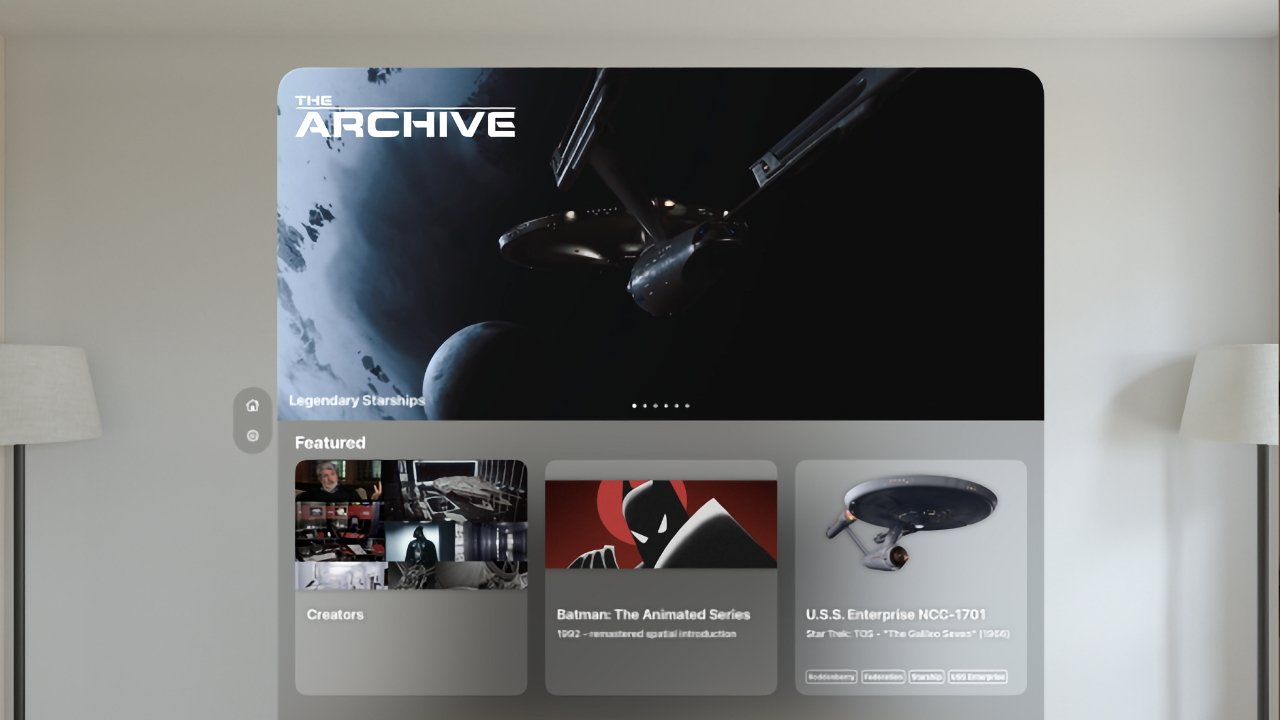
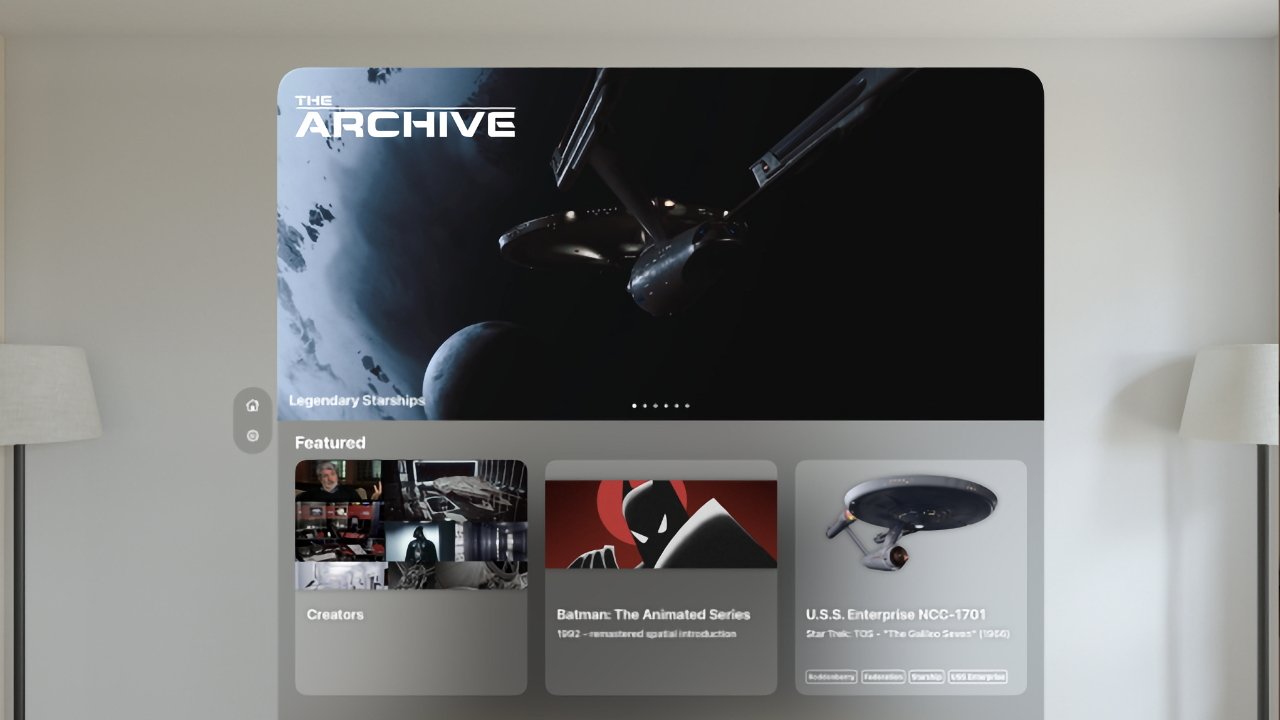
A new “Star Trek” Spatial Experience has been made exclusively for the new Apple Vision Pro, featuring two hours of high image quality footage from all eras of the show and its films.
Star Trek Experience for Apple Vision Pro (Source: Deadline)
As briefly mentioned by Apple in its roundup of native Apple Vision Pro apps, the Roddenberry Archive is bringing a “Star Trek” experience to the device. In conjunction with OTOY Paramount Game Studios, the Gene Roddenberry Estate’s new project spans every “Star Trek” show from the last 60 years.
According to Deadline, users can sit at Quark’s bar from “Star Trek: Deep Space Nine,” or peruse the shelf in Captain Kirk’s quarters from the original show.
Exclusive deals on Apple’s latest M3 MacBook Pro and iMac offer up to $350 in savings on top of a bonus coupon on AppleCare.
This is not a case where only certain configurations from the M3 MacBook Pro and iMac lines are discounted. There’s no need to compromise on the model you desire, as exclusive coupon code APINSIDER at Adorama is valid on every single set of specs carried by the Apple Authorized Reseller.
In this special offer, which is exclusive to AppleInsider readers, Adorama is offering a triple-digit discount on every new MacBook Pro and M3 iMac 24-inch.
It’s Apple Vision Pro release day, and the downtown Nashville Apple Store has opened to a quiet and small squad of people waiting to pick up their expensive glimpse into the future.
Apple Vision Pro – Nashville
Pandemonium likely comes to mind if someone asks you to imagine an Apple store on a product release day. However, for Apple Vision Pro, a strict appointment system and limited pre-orders led to a quiet morning in Nashville.
Initial pre-order pickups and in-store availability for Apple’s long-awaited Vision Pro headset began Friday morning. A hopeful few gathered outside the flagship Apple Downtown Nashville store for a chance to try on Apple Vision Pro or buy in-store stock.
In a new interview just minutes after the release of Apple Vision Pro, Apple CEO Tim Cook calls the new headset “magical,” and says it’s $3,499 is the right price for it.
Apple Vision Pro in an Apple Store
As the Apple Vision Pro finally arrives in stores, Apple CEO Tim Cook spoke with ABC’s Good Morning America live from New York’s Fifth Avenue Apple Store about the launch.
“I think’s going to be used in so many different ways because it’s a spatial computer,” said Cook. “You know, the iPhone introduced us to the mobile computer, the Mac introduced us to personal computers.”
Smaller record labels say Apple Music has not added money to the royalty payout pool to fund its 10% incentive for spatial audio, and instead it is reducing how much it pays all but the biggest firms.
Apple Music has a pot of money and it’s spending more with larger record labels
Apple Music recently told artists and record labels that it would pay them 10% greater royalties for music made in spatial audio. Counter-intuitively, the increase is not tied to how much spatial audio is listened to, but rather to what proportion of a label’s output is in this format.
So a label that can remaster everything it owns in spatial audio will see a considerably greater increase in revenues compared to one that can only remaster half its catalog.
Apple has revealed that starting on February 5, 2024, it will be possible to make a reservation to try an Apple Vision Pro in-store.
Apple Vision Pro
It’s easily the one Apple device that it is essential to try before you buy, not least because of how it must be customized for each user. Apple Watch comes with size options, material choices, and a lot of bands, but even it doesn’t need prescription lenses.
As well as the necessity of having the right lenses fitted, the Apple Vision Pro is also at this moment getting more attention than it may ever get again. Consequently, there is demand for in-store demonstrations.
Skip the Apple Vision Pro demo queues, soon you’ll be able to book a slot
Originally appeared here:
Skip the Apple Vision Pro demo queues, soon you’ll be able to book a slot
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept”, you consent to the use of ALL the cookies.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checkbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.