The Internal Revenue Service (IRS) is hiring employees from the crypto industry to improve its expertise in working with digital assets. According to a Feb. 28 Bloomberg report, the IRS has hired two former cryptocurrency executives. One of them, Sulolit…
In a now-deleted X post, scammers impersonated the Matthew Perry Foundation and urged people to donate via crypto. As reported by Rolling Stone, scammers targeted the X account of the late “Friends” star Matthew Perry, promoting crypto donations through a…
Sometimes a good story (and some slapstick comedy) goes a long way towards helping us understand complex problems.
OpenAI. (2024). ChatGPT [Large language model]. /g/g-2fkFE8rbu-dall-e
Note: originally published on pirate.baby, my little corner of the internet. Republishing here for reach.
preamble
The drive home from the movie theater was not going well. My then-girlfriend sat arms crossed in the passenger seat, the red glow from the traffic light matching her mood. “You can’t just let it be romantic. Why do you have to ruin everything!?!” We had just seen 50 First Dates, a classic Sandler/Barrymore romance about a woman whose brain injury prevents her from forming long-term memories. In the movie, Lucy (Barrymore) constructs her own “external memory” via her diary; a clever plot device, but one that required suspension of disbelief that I just could not abide. I had done shorthand math while the credits were rolling: If Lucy’s average diary entry took 20 minutes to write (that is less than most people, and most people aren’t trying to compensate for brain damage), each entry would take roughly half that time — so about 10 minutes — to read. Reading a week’s entries would take more than an hour. By the 6 month mark, the daily catch-up on her past would require more hours of reading than are in a day. Romantic? Yes. Realistic? No. And so we argued. I believe the conversation went something like this:
“Her: But what if every Sunday she wrote a cheat sheet for the past week, and then she only read those? That would take less time.“ ”Me: Even a weekly summary would become unreadable in less than a year.” “Her: OK, then what if she summarized those cheat sheets?? She could keep making the history smaller and smaller.” “Me: Yeah but eventually she’d lose too much detail and the summaries would be useless.” “Her: But she’d still have her daily journals for when she needs those details!” “Me: How would she ever search that? We’re back where we started.”
Twenty years later, the “Lucy problem” is a perfect lens to help us understand one of the most important challenges in designing a Large Language Model Agent Framework. The solution proposed by researchers at UC Berkeley is remarkably innovative and offers exciting potential — and it is a solution that bears significant resemblance to the “Lucy solution” I was arguing against during that car ride home. It looks like I owe someone a long-overdue apology.
Lucy the language model: a near-perfect analogy
Large Language Models are, in reality, just functions. You input at least one argument (text) and they output in kind. This output is the product of the model’s business logic, combined parameters, and internal arguments — one of those arguments being the training data used to develop the inference model. This training data serves as the model’s “memories”; without it the LLM would output very little value, similar to attempting a deep conversation with a newborn. The training data “memories” in a large language model are fixed at inference time, exactly like Lucy’s memories in the movie. She has developed experiences and gathered information up to a very specific point (in her case, the day of her accident); from that day forward, she interprets stimuli based on the exact state of her mind, and her memories, at that time. This is precisely how inference with a large language model operates — fixed to the moment the training was complete, and the resulting function was pickled.
Each time the LLM function is executed (here we will refer to this combined execution and response as a turn, borrowing from chat nomenclature) is exactly like one single day in the life of Lucy. With the model temperature turned down to 0 (deterministic) each turn with the same input will look exactly like Lucy’s early routine — repeating the same day over and over (and baking a lot of identical birthday cakes). An LLM cannot form new “memories” as a pure inference endpoint, any more than Lucy can.
To compensate for this with an LLM, the natural next step is to prepend those new “memories” as part of the text passed to the LLM function effectively augmenting the training data of the language model for the duration of the turn(1). However, language model context windows — the combined amount of text that can be input and output in a single turn — are limited in size. Again, this is exactly how Barrymore’s character experiences the world; her context window is one single day. Just as I argued so many years earlier that Lucy’s memories would eventually take longer to consume than there are hours in a day for her to retain them, new knowledge that must be included in a turn in order for the language model to produce a useful output quickly outgrows the available context window.
The limits of prompt engineering
The lion’s share of LLM Engineering coverage has been devoted to prompt engineering, or crafting the content we submit in a turn so that it produces the most desirable outcome. An entire ecosystem has rapidly developed around prompt design, from prompt engineering classes to prompt exchange marketplaces — all from the idea that from the “perfect prompt” you can coax the “perfect output.”
Henry, Sandler’s character in 50 First Dates, may have been one of the earliest prompt engineers. Early in the film Henry falls in love with Lucy and agrees not to tell her about her injury, instead wooing her anew each day. His daily “prompts” to re-win her heart begin abysmally, with most ending in rejection. Over time his technique evolves until Lucy consistently falls for him every day. We see this same example in countless language model demos, where a meticulously crafted prompt is used to visualize analytics for a dataset or generate a spot-on cover letter.
The examples are impressive, but how useful is this prompting really? In the movie, Henry finally addresses the extreme limitations in a life of infinite first dates and tells Lucy about her condition. With a language model, a “perfect prompt” executed in isolation is just as limited in value. Complex tasks require many complex steps, each building on a modified state — and this cannot be accomplished in a single turn. While prompt engineering is certainly an important piece of the puzzle, it isn’t remotely a holistic solution to our problem.
RAG, a newspaper, and a videotape
For both Lucy and the language model, things get interesting once we start externalizing memories. Retrieval Augmented Generation (RAG) is probably a close second to prompt engineering in the sheer volume of attention paid in LLM-related content. RAG can be more simply stated as “store text somewhere, then on each turn search that text and add bits to the prompt.” The most common RAG implementations today are blind semantic searches, where every user input is searched against the RAG store by semantic similarity, and then the top few search results are combined with the user input as the prompt. They look something like this:
# prompt with just user input Question: What is the last thing Todd said before he quit yesterday?
vs
# prompt with vector similarity search results for "What is the last thing Todd said before he quit yesterday?" via embeddings, prepended to prompt Context: "Margo: Todd is quitting today!" "Todd: I am quitting today. I've had enough." "Clark: I can't believe Todd finally quit, Margo is going to freak."
Question: What is the last thing Todd said before he quit yesterday?
The context injected by RAG might be very helpful, or it might be virtually irrelevant. What’s more, the question may not require context at all, and the RAG may just be noise.
Again 50 First Dates does not disappoint with real-world analogs. In the film, Lucy’s condition is kept hidden from her with the help of falsified context clues; her father swaps out her newspaper with a reprinted one, passes off a recorded football game as live TV, and paints over a wall every evening so she can re-paint it the next day, none the wiser. This context adds to the prompt and allows Lucy to live a full day (albeit the same one over and over). It does a significantly better job of reaching the desired outcome (Lucy enjoys her day and is able to function within it) than relying completely on the day’s organic events. Later, Henry introduces the first attempt to be honest with Lucy in the form of a VHS recording. To the plot of the film this is a pivotal moment, as it is Lucy’s first step towards regaining agency. With the language model, it is functionally the same as the newspaper and the paint; each turn is potentially better and more informed when it includes RAG content, but it is still very much an isolated turn without true external state management.
Regardless of which Lucy consumes — the fake newspaper or Henry’s real VHS tape — improvement in Lucy’s life is limited to the outcome of that day. Lucy still has no agency to live a full life, just as our language model can take no meaningful steps toward completing a complex task.
Just like prompt engineering, RAG is a piece of the puzzle, but it is not the answer in and of itself.
A mind with a diary
Let’s review that theory from the car. What if Lucy kept a diary, and then managed this “external memory” by summarizing, consolidating, and making herself cheat sheets? Unlike her father’s newspapers or Henry’s VHS tapes, this memory would be completely under her control. She decides what information is critically important, what memories can be forgotten, and what knowledge should live on in “cold storage” to be dredged up only when required. The film touches on this idea (though it took my romance-ruining logic to really see it played out in detail). With an external memory like this, Lucy is now unbound from her context window. She can pursue her interests for as long as they take, participate actively in the mundane but important events of life, have a family, and live. She can make a menu for the week on Monday, go shopping for groceries on Wednesday, and cook them on Friday — all the elements of agency returned to her by a few notebooks and to-do lists.
This is remarkably similar to the premise behind the MemGPT project(2). The context window, chat history, and RAG knowledge store are treated as tiered “memories”; each memory can be written and purged by the LLM using tool calls. Instead of approaching each turn as an isolated prompt + RAG + input = response, the “core” memory (the context window content) is processed continually as a daemon, with a new turn on each “heartbeart.” Just as each day Lucy is presented with her notes and to-do list from the previous day, with each turn the language model is presented with the core memory assembled by the previous turn. During that turn, the language model can edit this core memory, move information out of core and into archival memory, or search/recall from archival memory and add that back to core, and these changes will apply to the core memory presented in the next turn.
From the MemGPT research paper. This is brilliant work, highly recommend you check it out first-hand.
Here’s a walk-through of how an agent could work (with a bit of pseudo-code) to answer a user’s question about a company. The agent has a core memory describing itself and the user, a history section containing the last five messages, and a list of tools the agent can call. This core memory is passed as the prompt in a turn every 10 seconds, or sooner if externally triggered.
On the first pass, the agent calls the archive_lines() tool to move the 2nd paragraph of the user information to cold storage. Why? because the system prompt informs the agent of the current and max memory sizes and instructs the agent to self-adjust when needed.
On the next pass, the tool call request and result are the newest entries in the core memory history (the 2 oldest from the last turn have been moved to recall memory and are not visible). In this turn the agent calls pause_heartbeats() to wait for external stimuli, as it detects nothing else to update in its own core memory.
The next turn is triggered by a user message, which is the newest history entry in this turn’s core memory. The user message says “How many people are in the Seattle office?” and the agent’s first action is to call the get_employee_list() tool, along with the internal monologue message “I must get the list of employees and count only the ones in the Seattle office. I must then send the message back to the user.”
On the next turn, the agent tool call, internal monologue, and tool call result are in the core memory history, but the original user message has been pushed out. On this turn the agent’s internal monologue is “65 employees are in the Seattle office. I must retrieve the original question so I can answer it correctly” and the tool call is retrieve_message(user, -1) to get the last message from the user.
On the next turn, the agent calls send_message(“there are 65 employees in the Seattle office”), and responds to the user.
And the beat goes on.
This “language model operating system” is a starkly contrasting view of how inference services could function to complete complex, multifaceted tasks. It also changes the paradigm of “evolution” as an agent, allowing the application to adjust and self-correct. Prompts and RAG become correctable elements within a generative “cycle”; if a RAG search is ineffective or a prompt misses the mark, it can be re-tried or compensated for on the next turn. Most distinctly important from single-turn agent design, the results of this self-managed memory are cumulative. This is an absolute necessity for true agency.
I am very excited about what a framework built on this concept could mean; adding stimuli to a well-appointed agent (or cluster of agents) becomes an execution layer that evolves beyond text generation and an ROI that grows exponentially with the complexity of its charge. A language model operating in this fashion is still a language model — a function, not a sentient being — but it crosses a threshold of appearance that is the stuff of Sci-Fi. More importantly, it adds a critical element to the generative equation that I just don’t see autonomous agency succeeding without: repetition. Humans don’t immediately think of every required thought and blurt out the perfect response in one breath; we take steps, ask questions that uncover new questions, pause to consider internally, and arrive at an answer. By bestowing that same capacity on an application, this language model operating system could be a new paradigm in computing.
For those of us building user-facing agents, this is a concept worth focus and cycles. Single-turn prompt libraries and slice-and-dice embedding building to RAG away bad responses was the best idea we had in the dark AI days of 6 months ago, but I don’t think they will get us where we want to go. In 50 First Dates Lucy married Henry, became a mom, and sailed to Alaska, all because she was restored the agency to own her mind and manage her memories. Language model agents need the same in an “operating system” if we want to unlock them.
Join me next time, when we explore the parallels between Happy Gilmore and K8S (hint: there are none).
Footnotes:
Adding context to a prompt and fine-tuning or retraining a model are not really the same thing, but I was willing to take a few liberties with technical accuracy for the sake of clearly demonstrating the subject concepts.
2. Note that throughout this writing I am referring to the concepts introduced by the research behind MemGPT, not the implementation itself. The nomenclature, pseudo-code, and description of events here are not intended to reflect the software project.
MemGPT Citation:
packer 2023 memgpt, MemGPT: Towards LLMs as Operating Systems, authors: Packer, Charles and Wooders, Sarah and Lin, Kevin and Fang, Vivian and Patil, Shishir G. and Stoica, Ion and Gonzalez, Joseph E., arXiv preprint arXiv:2310.08560
Discover design approaches for building a scalable information retrieval system
Introduction
Question-answering applications have intensely emerged in recent years. They can be found everywhere: in modern search engines, chatbots or applications that simply retrieve relevant information from large volumes of thematic data.
As the name indicates, the objective of QA applications is to retrieve the most suitable answer to a given question in a text passage. Some of the first methods consisted of naive search by keywords or regular expressions. Obviously, such approaches are not optimal: a question or text can contain typos. Moreover, regular expressions cannot detect synonyms which can be highly relevant to a given word in a query. As a result, these approaches were replaced by the new robust ones, especially in the era of Transformers and vector databases.
This article covers three main design approaches for building modern and scalable QA applications.
Types of QA system architectures
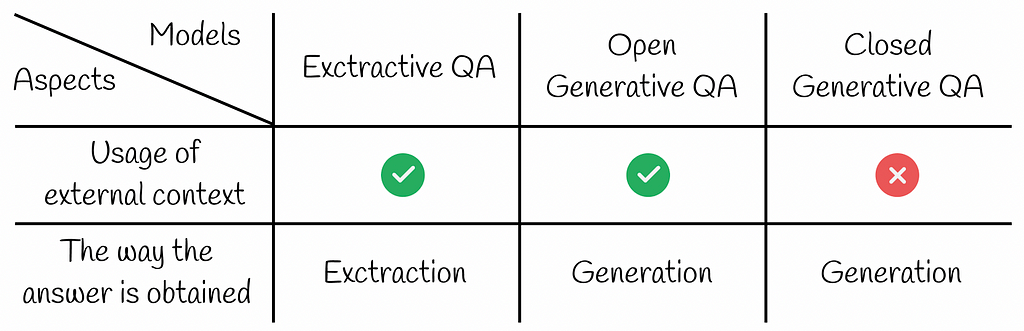
Exctractive QA
Extractive QA systems consist of three components:
Retriever
Database
Reader
Extractive QA architecture
Firstly, the question is fed into the retriever. The goal of the retriever is to return an embedding corresponding to the question. There can be multiple implementations of retriever starting from simple vectorization methods like TF-IDF, BM-25 and ending up with more complex models. Most of the time, Transformer-like models (BERT) are integrated into the retriever. Unlike naive approaches that rely only on word frequency, language models can build dense embeddings that are capable of capturing the semantic meaning of text.
After obtaining a query vector from a question, it is then used to find the most similar vectors among an external collection of documents. Each of the documents has a certain chance of containing the answer to the question. As a rule, the collection of documents is processed during the training phase by being passed to the retriever which outputs corresponding embeddings to the documents. These embeddings are then usually stored in a database which can provide an effective search.
In QA systems, vector databases usually play the role of a component for efficient storage and search among embeddings based on their similarity. The most popular vector databases are Faiss, Pinecone and Chroma.
If you would like to better understand how vector databases work under the hood, then I recommend you check my article series on similarity search where I deeply cover the most popular algorithms:
By retrieving the k most similar database vectors to the query vector, their original text representations are used to find the answer by another component called the reader. The reader takes an initial question and for each of the k retrieved documents it extracts the answer in the text passage and returns a probability of this answer being correct. The answer with the highest probability is then finally returned from the exclusive QA system.
Fine-tuned large language models specialising in QA downstream tasks are usually used in the role of the reader.
Open Generative QA
Open Generative QA follows exactly the same framework as Extractive QA except for the fact that they use the generator instead of the reader. Unlike the reader, the generator does not extract the answer from a text passage. Instead, the answer is generated from the information provided in the question and text passages. As in the case of Extractive QA, the answer with the highest probability is chosen as the final answer.
As the name indicates, Open Generative QA systems normally use generative models like GPT for answer generation.
Open Generative QA architecture
By having a very similar structure, there might come a question of when it is better to use an Extractive or Open Generative architecture. It turns out that when a reader model has direct access to a text passage containing relative information, it is usually smart enough to retrieve a precise and concise answer. On the other hand, most of the time, generative models tend to produce longer and more generic information for a given context. That might be beneficial in cases when a question is asked in an open form but not for situations when a short or exact answer is expected.
Retrieval-Augmented Generation
Recently, the popularity of the term “Retrieval-Augmented Generation” or “RAG” has skyrocketed in machine learning. In simple words, it is a framework for creating LLM applications whose architecture is based on Open Generative QA systems.
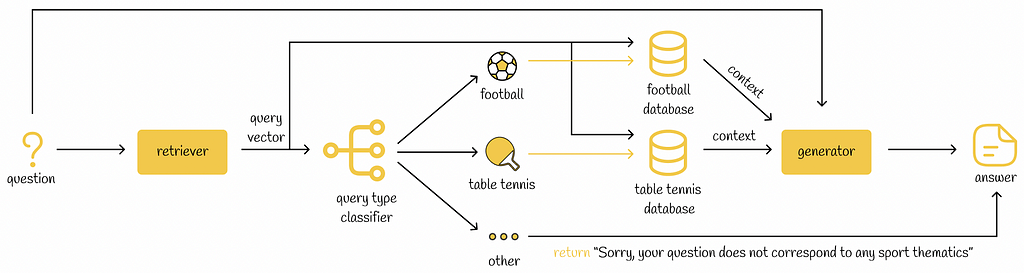
In some cases, if an LLM application works with several knowledge domains, the RAG retriever can add a supplementary step in which it will try to identify the most relevant knowledge domain to a given query. Depending on an identified domain, the retriever can then perform different actions. For example, it is possible to use several vector databases each corresponding to a particular domain. When a query belongs to a certain domain, the vector database of that domain is then used to retrieve the most relevant information for the query.
This technique makes the search process faster since we search through only a particular subset of documents (instead of all documents). Moreover, it can make the search more reliable as the ultimate retrieved context is constructed from more relevant documents.
Example of RAG pipeline. The retriever constructs an embedding from a given question. Then this embedding is used to classify the question into one of the sport categories. For each sport type, the respective vector database is used to retrieve the most similar context. The question and the retrieved context are fed into the generator to produce the answer. If the question was not related to sport, then the RAG application would inform the user about it.
Closed Generative QA
Closed Generative QA systems do not have access to any external information and generate answers by only using the information from the question.
Closed Generative QA architecture
The obvious advantage of closed QA systems is reduced pipeline time as we do not have to search through a large collection of external documents. But it comes with the cost of training and accuracy: the generator should be robust enough and have a large training knowledge to be capable of generating appropriate answers.
Closed Generative QA pipeline has another disadvantage: generators do not know any information that appeared later in the data it had been trained on. To eliminate this issue, a generator can be trained again on a more recent dataset. However, generators usually have millions or billions of parameters, thus training them is an extremely resource-heavy task. In comparison, dealing with the same problem with Extractive QA and Open Generative QA systems is much simpler: it is just enough to add new context data to the vector database.
Most of the time closed generative approach is used in applications with generic questions. For very specific domains, the performance of closed generative models tends to degrade.
Conclusion
In this article, we have discovered three main approaches for building QA systems. There is no absolute winner among them: all of them have their own pros and cons. For that reason, it is firstly necessary to analyse the input problem and then choose the correct QA architecture type, so it can produce a better performance.
It is worth noting that Open Generative QA architecture is currently on the trending hype in machine learning, especially with innovative RAG techniques that have appeared recently. If you are an NLP engineer, then you should definitely keep your eye on RAG systems as they are evolving at a very high rate nowadays.
Amazon is being sued by the writer of the original 1989 Patrick Swayze version of the film Road House over alleged copyright infringement in the movie’s remake, The Los Angeles Times has reported. Screenwriter R. Lance Hill accuses Amazon and MGM Studios of using AI to clone actors’ voices in the new production in order to finish it before the copyright expired.
Hill said he filed a petition with the US Copyright Office in November 2021 to reclaim the rights to his original screenplay, which forms the basis of the new film. At that point, the rights were owned by Amazon Studios, as part of its acquisition of MGM, but were set to expire in November 2023. Hill alleges that once that happened, the rights would revert back to him.
According to the lawsuit, Amazon Studios rushed ahead with the project anyway in order to finish it before the copyright deadline. Since it was stymied by the actor’s strike, Hill alleges Amazon used AI to “replicate the voices” of the actors who worked in the 2024 remake. Such use violated the terms of the deal struck between the union and major studios including Amazon.
The claim is complicated by the fact that Hill signed a “work-made-for-hire” deal with the original producer, United Artists. That effectively means that the studio hiring the writer would be both the owner and copyright holder of the work. Hill, however, dismissed that as “boilerplate” typically used in contracts.
The lawsuit seeks to block the release of the film, set to bow at SXSW on March 8th before (controversially) heading direct to streaming on Prime Video on March 21.
Amazon denies the claims, with a spokesperson telling The Verge that “the studio expressly instructed the filmmakers to NOT use AI in this movie.” It added that if AI was utilized, it was only done in early versions of the films. Later on, filmmakers were told to remove any “AI or non-SAG AFTRA actors” for the final version. It added that other allegations are “categorically false” and that it believes its copyright on the original Road House has yet to expire.
This article originally appeared on Engadget at https://www.engadget.com/amazon-accused-of-using-ai-to-replicate-the-voices-of-actors-in-road-house-remake-054408057.html?src=rss
‘Fastest SSD on the planet’: Crucial’s T705 tops benchmarks as reviewers rave about its performance — but it is far too expensive and a RAID-0 setup may beat it
Originally appeared here:
‘Fastest SSD on the planet’: Crucial’s T705 tops benchmarks as reviewers rave about its performance — but it is far too expensive and a RAID-0 setup may beat it
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept”, you consent to the use of ALL the cookies.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checkbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.