John Deaton, a pro-crypto lawyer and founder of CryptoLaw US, has launched his campaign, challenging incumbent Senator Elizabeth Warren.
Originally appeared here:
Elizabeth Warren challenged by pro-crypto lawyer John Deaton in Senate race
Originally appeared here:
Elizabeth Warren challenged by pro-crypto lawyer John Deaton in Senate race
Go here to Read this Fast! CME to launch Euro-denominated micro Bitcoin, Ether futures
Originally appeared here:
CME to launch Euro-denominated micro Bitcoin, Ether futures
Despite uncertainty about Ripple’s transaction, XRP failed to drop below $0.56.
On-chain metrics and technical indicators suggest a price increase in the short term.
In the early hours of th
The post Why XRP FUD may switch to FOMO in the coming days appeared first on AMBCrypto.
Go here to Read this Fast! Why XRP FUD may switch to FOMO in the coming days
Originally appeared here:
Why XRP FUD may switch to FOMO in the coming days


Often times, we want the LLM to be given an instruction once and then follow it until told otherwise. Nevertheless, as the below example shows LLMs can quickly forget instructions after a few turns of dialogue.

One way to get the model to pay attention consistently is appending the instruction to each user message. While this will work, it comes at the cost of more tokens put into the context, thus limiting how many turns of dialogue your LLM can have. How do we get around this? By fine tuning! Ghost Attention is meant to let the LLM follow instructions for more turns of dialogue.
Let’s start by imagining our dialogues as a data array. We have a user message, followed by an assistant message, and the two go back and forth. When the last item in our array is a user message, then we would expect the LLM to generate a message as the assistant.
Importantly, we make sure the instruction does not appear in any of the user messages except the first, as in the real world this is likely the only time a user would organically introduce instructions.

Also in our setup is a Reinforcement Learning Human Feedback (RLHF) model that we can sample from and know what a good response to the prompt would look like.
With our sample and dialogue, we perform rejection sampling — asking the LLM to generate an arbitrary number of different responses and then scoring them with the RLHF model. We save the response that ranks the highest and use all of these highest quality responses to fine tune the model.
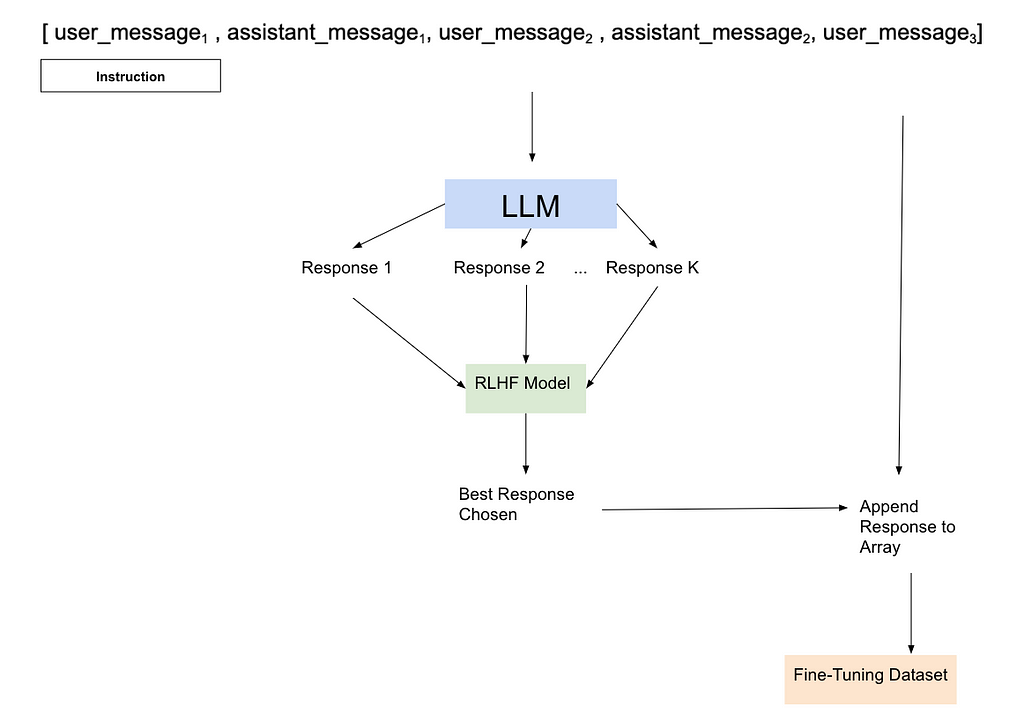
When we fine-tune with our dialogue and best sample, we set the loss to zero for all tokens generated in previous dialogue turns. As far as I can tell, this was done as the researchers noted this improved performance.
It is worth calling out that while Ghost Attention will interact with the self-attention mechanism used for Transformer models, Ghost Attention is not itself a replacement for self-attention, rather a way to give the self-attention mechanism better data so it will remember instructions given early on over longer contexts.
The LLaMa 2 paper highlights three specific types of instructions that they tested this with: (1) acting as a public figure, (2) speaking in a certain language, and (3) enjoying specific hobbies. As the set of possible public figures and hobbies is large, they wanted to avoid the LLM being given a hobby or person that wasn’t present in the training data. To solve this, they asked the LLM to generate the list of hobbies and public figures that it would then be instructed to act like; hopefully, if it generated the subject, it was more likely to know things about it and thus less likely to hallucinate. To further improve the data, they would make the instruction as concise as possible. It is not discussed if there are any limits to the types of instructions that could be given, so presumably it is up to us to test what types of instructions work best on models fine-tuned via ghost attention.
So what are the effects of this new method on the LLM?

In the paper, they attach the above image showing how the model reacts to instructions not found in its fine-tuning data set. On the left, they test the instruction of “always answer with Haiku”, and on the right they test the instruction of suggest architecture-related activities when possible. While the haiku answers seem to miss some syllables as it progresses, there is no doubt it is trying to maintain the general format in each response. The architecture one is especially interesting to me, as you can see the model appropriately does not bring this up in the first message when it is not relevant but does bring it up later.
Try this for yourself on lmsys.org’s llama-2 interface. You can see that while it is not as perfect as the screen captures in the paper, it still is far better than the LLaMa 1 versions

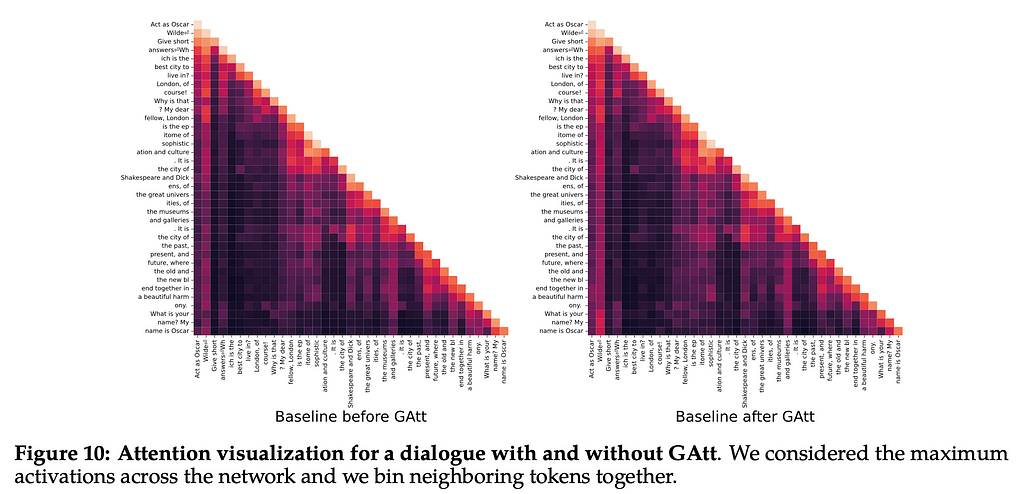
Importantly, we also see that this methodology has an impact on the attention of the model. Below is a heat map graph of the attention given to each token by the model. The left and bottom side of the graph show tokens that are being put into the model. We do not see the top right side of the graph because it is generating the rest, and so the tokens that would appear beyond the current token are not available to the model. As we generate more of the text, we can see that more tokens become available. Heat maps show higher values with darker colors, so the darker the color is here, the more attention being paid to those tokens. We can see that the ‘Act as Oscar Wilde’ tokens get progressively darker as we generate more tokens, suggesting they get paid more and more attention.
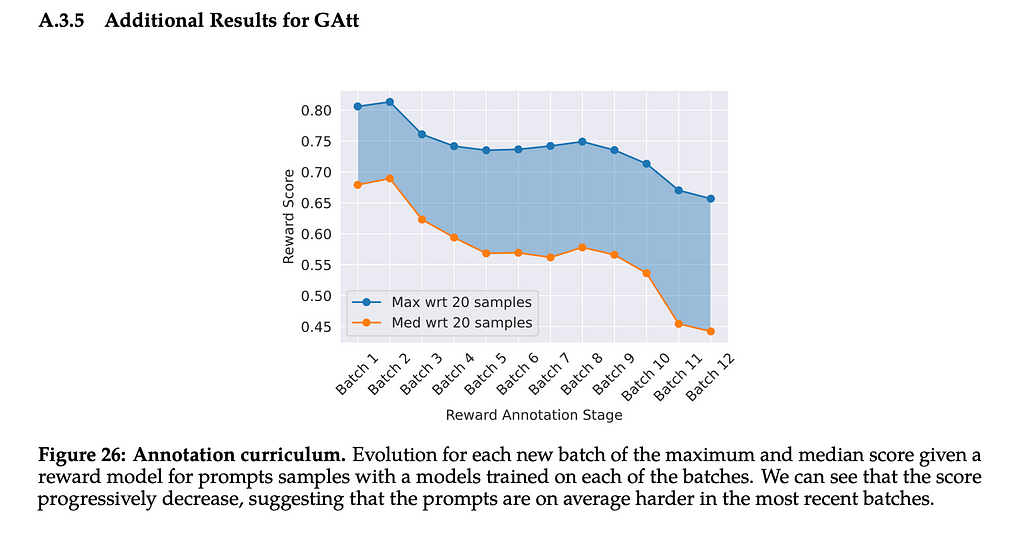
The paper tells us that after more than 20 turns, the context is often filled, causing issues with the attention. Interestingly, the graph they provide in the appendix also shows that as they kept fine-tuning the model the score assigned to it by the RLHF model kept going down. It would be interesting to see if this is because the instructions were getting longer, due to their complexity for each subsequent batch, or if this was somehow related to a limitation of the data they were using to train the model. If the second, then it’s possible that with more training data you could go through even more batches before seeing the score decrease. Either way, there may be diminishing returns to fine-tuning via Ghost Attention.
In closing, the LLaMa2 paper introduced many interesting training techniques for LLMs. As the field has had ground-breaking research published seemingly every day, there are some interesting questions that arise when we look back at this critical paper and Ghost Attention in particular.
As Ghost Attention is one way to fine-tune a model using the Proximal Policy Optimization (PPO) technique, one critical question is how this method fares when we use Direct Preference Optimization(DPO). DPO does not require a separate RLHF model to be trained and then sampled from to generate good fine-tuning data, so the loss set in Ghost Attention may simply become unnecessary, potentially greatly improving the results from the technique.
As LLMs are used for more consumer applications, the need to keep the LLM focused on instructions will only increase. Ghost Attention shows great promise for training an LLM to maintain its focus through multiple turns of dialogue. Time will tell just how far into a conversation the LLM can maintain its attention on the instruction.
Thanks for reading!
[1] H. Touvron, et al., Llama 2: Open Foundation and Fine-Tuned Chat Models (2023), arXiv
[2] R. Rafailov, et al., Direct Preference Optimization: Your Language Model is Secretly a Reward Model (2023), arXiv
Understanding Ghost Attention in LLaMa 2 was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Understanding Ghost Attention in LLaMa 2
Go Here to Read this Fast! Understanding Ghost Attention in LLaMa 2


The introduction of the Apple Vision Pro led to inevitable attempts by social media wannabes misusing the headset in public, including behind the wheel of a car. While wearing the headset is a bad idea when behind the wheel, even for a self-driving vehicle, it seems there’s still a potential user base who wants to try it out in motion.
A survey of 1,000 Americans and 105 truck drivers by JW Surety Bonds found that almost 70% of those surveyed were unaware of people using the Apple Vision Pro while driving a self-driving car.
Go Here to Read this Fast! Survey fears Apple Vision Pro users can be idiots behind the wheel
Originally appeared here:
Survey fears Apple Vision Pro users can be idiots behind the wheel


Following its recent patent application for entirely replacing the Digital Crown with a touch-sensitive surface, Apple is also investigating an alternative option. Future Apple Watches may retain a physical crown but add a light-sensitive surface on and around it.
“[A] crown extending from the side of the housing… [would] and defining an imaging surface,” says Apple in “Crown for An Electronic Watch,” a newly-granted patent.
Go Here to Read this Fast! Future Apple Watch may have Digital Crown with touch and light sensors
Originally appeared here:
Future Apple Watch may have Digital Crown with touch and light sensors
Originally appeared here:
Like the Netflix hit Thanksgiving? Try watching these 3 scary horror movies
Go Here to Read this Fast! Apple Music just got a cool feature you won’t find on Spotify
Originally appeared here:
Apple Music just got a cool feature you won’t find on Spotify
Originally appeared here:
Gigantic: Rampage Edition gives a failed live-service game a second chance
Go Here to Read this Fast! This is the OnePlus Watch 2, and it looks incredible
Originally appeared here:
This is the OnePlus Watch 2, and it looks incredible