Reflecting on advances and challenges in deep learning and explainability in the ever-evolving era of LLMs and AI governance

Background
Imagine you are navigating a self-driving car, relying entirely on its onboard computer to make split-second decisions. It detects objects, identifies pedestrians, and even can anticipate behavior of other vehicles on the road. But here’s the catch: you know it works, of course, but you have no idea how. If something unexpected happens, there’s no clear way to understand the reasoning behind the outcome. This is where eXplainable AI (XAI) steps in. Deep learning models, often seen as “black boxes”, are increasingly used to leverage automated predictions and decision-making across domains. Explainability is all about opening up that box. We can think of it as a toolkit that helps us understand not only what these models do, but also why they make the decisions they do, ensuring these systems function as intended.
The field of XAI has made significant strides in recent years, offering insights into model internal workings. As AI becomes integral to critical sectors, addressing responsibility aspects becomes essential for maintaining reliability and trust in such systems [Göllner & a Tropmann-Frick, 2023, Baker&Xiang, 2023]. This is especially crucial for high-stakes applications like automotive, aerospace, and healthcare, where understanding model decisions ensures robustness, reliability, and safe real-time operations [Sutthithatip et al., 2022, Borys et al., 2023, Bello et al., 2024]. Whether explaining why a medical scan was flagged as concerning for a specific patient or identifying factors contributing to model misclassification in bird detection for wind power risk assessments, XAI methods allow a peek inside the model’s reasoning process.
We often hear about boxes and their kinds in relation to models and transparency levels, but what does it really mean to have an explainable AI system? How does this apply to deep learning for optimizing system performance and simplifying maintenance? And it’s not just about satisfying our curiosity. In this article, we will explore how explainability has evolved over the past decades to reshape the landscape of computer vision, and vice versa. We will review key historical milestones that brought us here (section 1), break down core assumptions, domain applications, and industry perspectives on XAI (section 2). We will also discuss human-centric approach to explainability, different stakeholders groups, practical challenges and needs, along with possible solutions towards building trust and ensuring safe AI deployment in line with regulatory frameworks (section 3.1). Additionally, you will learn about commonly used XAI methods for vision and examine metrics for evaluating how well these explanations work (section 3.2). The final part (section 4) will demonstrate how explainability methods and metrics can be effectively applied to leverage understanding and validate model decisions on fine-grained image classification.
1. Back to the roots: Historical milestones in (X)AI
Over the past century, the field of deep learning and computer vision has witnessed critical milestones that have not only shaped modern AI but have also contributed to the development and refinement of explainability methods and frameworks. Let’s take a look back to walk through the key developments and historical milestones in deep learning before and after explainability, showcasing their impact on the evolution of XAI for vision (coverage: 1920s — Present):
- 1924: Franz Breisig, a German mathematician, regards the explicit use of quadripoles in electronics as a “black box”, the notion used to refer to a system where only terminals are visible, with internal mechanisms hidden.
- 1943: Warren McCulloch and Walter Pitts publish in their seminal work “A Logical Calculus of the Ideas Immanent in Nervous Activity” the McCulloch-Pitts (MCP) neuron, the first mathematical model of an artificial neuron, forming the basis of neural networks.
- 1949: Donald O. Hebb, introduces a neuropsychological concept of Hebbian learning, explaining a basic mechanism for synaptic plasticity, suggesting that (brain) neural connections strengthen with use (cells that fire together, wire together), thus being able to be re-modelled via learning.
- 1950: Alan Turing publishes “Computing Machinery and Intelligence”, presenting his groundbreaking idea of what came to be known as the Turing test for determining whether a machine can “think”.
- 1958: Frank Rosenblatt, an American psychologist, proposes perceptron, a first artificial neural network in his “The perceptron: A probabilistic model for information storage and organisation in the brain”.
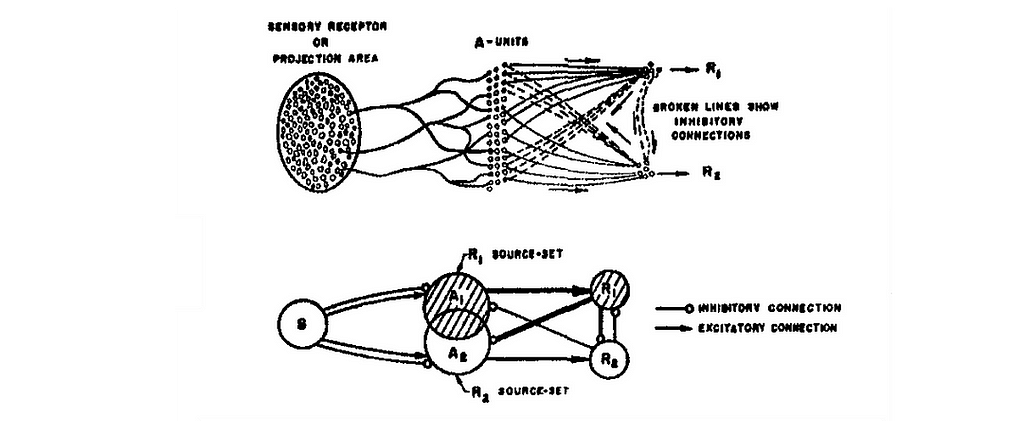
- 1962: Frank Rosenblatt introduces the back-propagation error correction, a fundamental concept for computer learning, that inspired further DL works.
- 1963: Mario Bunge, an Argentine-Canadian philosopher and physicist, publishes “A General Black Box Theory”, contributing to the development of black box theory and defining it as an abstraction that represents “a set of concrete systems into which stimuli S impinge and output of which reactions R emerge”.
- 1967: Shunichi Amari, a Japanese engineer and neuroscientist, pioneers the first multilayer perceptron trained with stochastic gradient descent for classifying non-linearly separable patterns.
- 1969: Kunihiko Fukushima, a Japanese computer scientist, introduces Rectified Linear Unit (ReLU), which has since become the most widely adopted activation function in deep learning.
- 1970: Seppo Linnainmaa, a Finnish mathematician and computer scientist, proposes the “reverse mode of automatic differentiation” in his master’s thesis, a modern variant of backpropagation.
- 1980: Kunihiko Fukushima introduces Neocognitron, an early deep learning architecture for convolutional neural networks (CNNs), which does not use backpropagation for training.
- 1989: Yann LeCun, a French-American computer scientist, presents LeNet, the first CNN architecture to successfully apply backpropagation for handwritten ZIP code recognition.
- 1995: Morch et al. introduce saliency maps, offering one of the first explainability approaches for unveiling internal workings of deep neural networks.
- 2000s: Further advances including development of CUDA, enabling parallel processing on GPUs for high-performance scientific computing, alongside ImageNet, a large-scale manually curated visual dataset, pushing forward fundamental and applied AI research.
- 2010s: Continued breakthroughs in computer vision, such as Krizhevsky, Sutskever, and Hinton’s deep convolutional network for ImageNet classification, drive widespread AI adoption across industries. The field of XAI flourishes with the emergence of CNN saliency maps, LIME, Grad-CAM, and SHAP, among others.
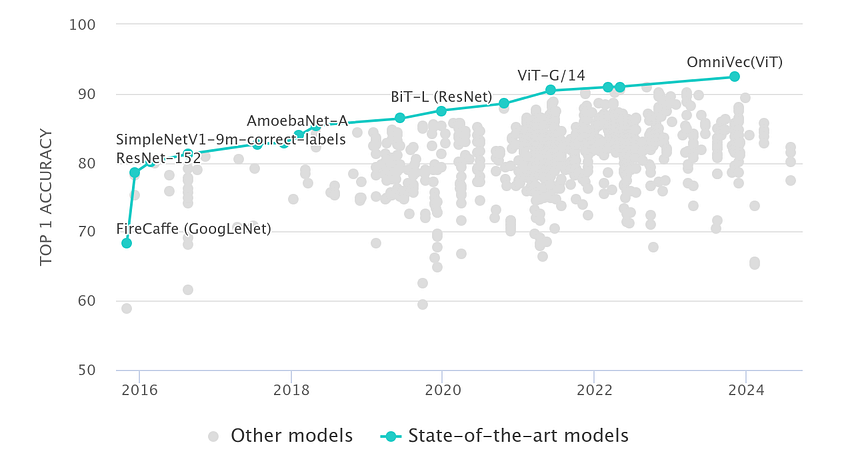
- 2020s: The AI boom gains momentum with the 2017 paper “Attention Is All You Need”, which introduces an encoder-decoder architecture, named Transformer, which catalyzes the development of more advanced transformer-based architectures. Building on early successes such as Allen AI’s ELMo, Google’s BERT, and OpenAI’s GPT, Transformer is applied across modalities and domains, including vision, accelerating progress in multimodal research. In 2021, OpenAI introduces CLIP, a model capable of learning visual concepts from natural language supervision, paving the way for generative AI innovations, including DALL-E (2021), Stable Diffusion 3 (2024), and Sora (2024), enhancing image and video generation capabilities.
- 2024: The EU AI Act comes into effect, establishing legal requirements for AI systems in Europe, including mandates for transparency, reliability, and fairness. For example, Recital 27 defines transparency for AI systems as: “developed and used in a way that allows appropriate traceability and explainability […] contributing to the design of coherent, trustworthy and human-centric AI”.
As we can see, early works primarily focused on foundational approaches and algorithms. with later advancements targeting specific domains, including computer vision. In the late 20th century, key concepts began to emerge, setting the stage for future breakthroughs like backpropagation-trained CNNs in the 1980s. Over time, the field of explainable AI has rapidly evolved, enhancing our understanding of reasoning behind prediction and enabling better-informed decisions through increased research and industry applications. As (X)AI gained traction, the focus shifted to balancing system efficiency with interpretability, aiding model understanding at scale and integrating XAI solutions throughout the ML lifecycle [Bhatt et al., 2019, Decker et al., 2023]. Essentially, it is only in the past two decades that these technologies have become practical enough to result in widespread adoption. More lately, legislative measures and regulatory frameworks, such as the EU AI Act (Aug 2024) and China TC260’s AI Safety Governance Framework (Sep 2024), have emerged, marking the start of more stringent regulations for AI development and deployment, including the right enforcing “to obtain from the deployer clear and meaningful explanations of the role of the AI system in the decision-making procedure and the main elements of the decision taken” (Article 86, 2026). This is where XAI can prove itself at its best. Still, despite years of rigorous research and growing emphasis on explainability, the topic seems to have faded from the spotlight. Is that really the case? Now, let’s consider it all from a bird’s eye view.
2. AI delight then and now: XAI & RAI perspectives
Today is an exciting time to be in the world of technology. In the 1990s, Gartner introduced something called the Hype cycle to describe how emerging technologies evolve over time — from the initial spark of interest to societal application. According to this methodology, technologies typically begin with innovation breakthroughs (referred to as the “Technology trigger”), followed by a steep rise in excitement, culminating at the “Peak of inflated expectations”. However, when the technology doesn’t deliver as expected, it plunges into the “Trough of disillusionment,” where enthusiasm wanes, and people become frustrated. The process can be described as a steep upward curve that eventually descends into a low point, before leveling off into a more gradual ascent, representing a sustainable plateau, the so-called “Plateau of productivity”. The latter implies that, over time, a technology can become genuinely productive, regardless of the diminished hype surrounding it.
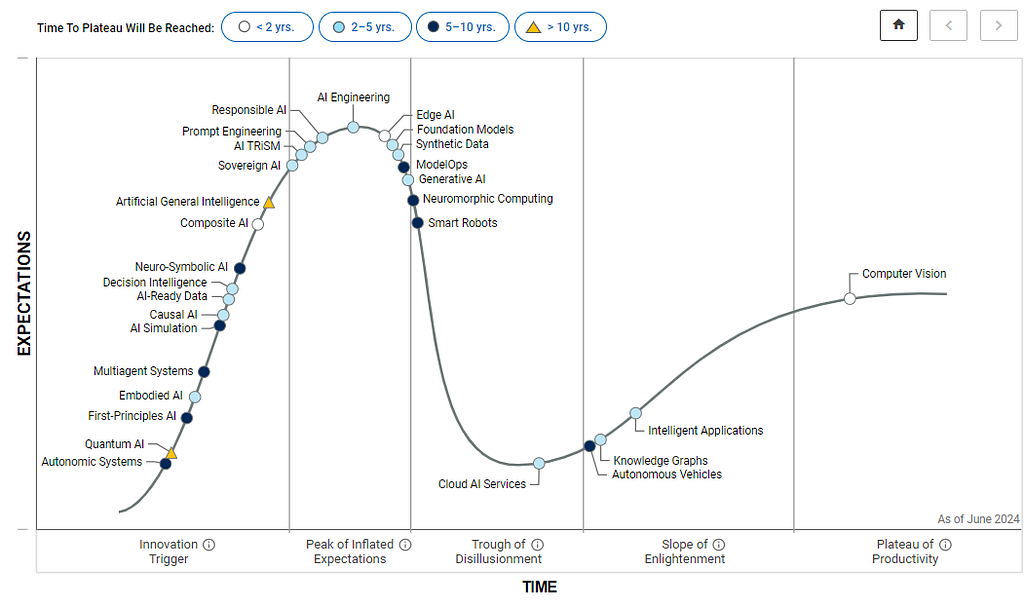
Look at previous technologies that were supposed to solve everything — intelligent agents, cloud computing, blockchain, brain-computer interfaces, big data, and even deep learning. They all came up to have fantastic places in the tech world, but, of course, none of them became a silver bullet. Similar goes with the explainability topic now. And we can see over and over that history repeats itself. As highlighted by the Gartner Hype Cycle for AI 2024 (Fig. 3), Responsible AI (RAI) is gaining prominence (top left), expected to reach maturity within the next five years. Explainability provides a foundation for responsible AI practices by ensuring transparency, accountability, safety, and fairness.
Figure below overviews XAI research trends and applications, derived from scientific literatures published between 2018 and 2022 to cover various concepts within the XAI field, including “explainable artificial intelligence”, “interpretable artificial intelligence”, and “responsible artificial intelligence” [Clement et al., 2023]. Figure 4a outlines key XAI research areas based on the meta-review results. The largest focus (44%) is on designing explainability methods, followed by 15% on XAI applications across specific use cases. Domain-dependent studies (e.g., finance) account for 12%, with smaller areas — requirements analysis, data types, and human-computer interaction — each making up around 5–6%.
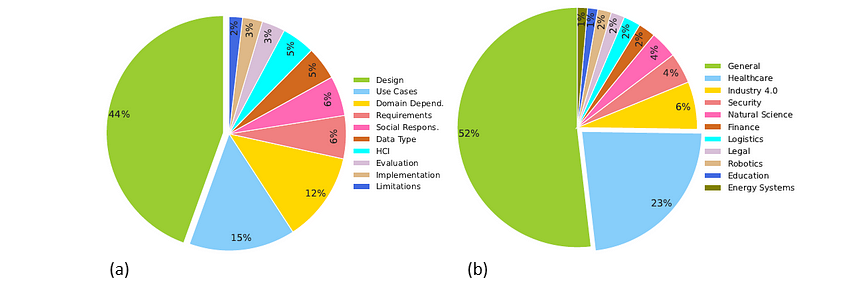
Next to it are common application fields (Fig. 4b), with headcare leading (23%), driven by the need for trust-building and decision-making support. Industry 4.0 (6%) and security (4%) follow, where explainability is applied to industrial optimization and fraud detection. Other fields include natural sciences, legal studies, robotics, autonomous driving, education, and social sciences [Clement et al., 2023, Chen et al., 2023, Loh et al., 2022]. As XAI progresses toward a sustainable state, research and development become increasingly focused on addressing fairness, transparency, and accountability [Arrieta et al., 2020, Responsible AI Institute Standards, Stanford AI Index Report]. These dimensions are crucial for ensuring equitable outcome, clarifying decision-making processes, and establishing responsibility for those decisions, thereby fostering user confidence, and aligning with regulatory frameworks and industry standards. Reflecting the trajectory of past technological advances, the rise of XAI highlights both the challenges and opportunities for building AI-driven solutions, establishing it as an important element in responsible AI practices, enhancing AI’s long-term relevance in real-world applications.
3. To put the spotlight back on XAI: Explainability 101
3.1. Why and when model understanding
Here is a common perception of AI systems: You put data in, and then, there is black box processing it, producing an output, but we cannot examine the system’s internal workings. But is that really the case? As AI continues to proliferate, the development of reliable, scalable, and transparent systems becomes increasingly vital. Put simply: the idea of explainable AI can be described as doing something to provide a clearer understanding of what happens between the input and output. In a broad sense, one can think about it as a collection of methods allowing us to build systems capable of delivering desirable results. Practically, model understanding can be defined as the capacity to generate explanations of the model’s behaviour that users can comprehend. This understanding is crucial in a variety of use cases across industries, including:
- Model debugging and quality assurance (e.g., manufacturing, robotics);
- Ensuring system trustability for end-users (medicine, finance);
- Improving system performance by identifying scenarios where the model is likely to fail (fraud detection in banking, e-commerce);
- Enhancing system robustness against adversaries (cybersecurity, autonomous vehicles);
- Explaining decision-making processes (finance for credit scoring, legal for judicial decisions);
- Detecting data mislabelling and other issues (customer behavior analysis in retail, medical imaging in healthcare).
The growing adoption of AI has led to its widespread use across domains and risk applications. And here is the trick: human understanding is not the same as model understanding. While AI models process information in ways that are not inherently intuitive to humans, one of the primary objectives of XAI is to create systems that effectively communicate their reasoning — in other words, “speak” — in terms that are accessible and meaningful to und users. So, the question, then, is how can we bridge the gap between what a model “knows” and how humans comprehend its outputs?
3.2. Who is it for — Stakeholders desiderata on XAI
Explainable AI is not just about interpreting models but enabling machines to effectively support humans by transferring knowledge. To address these aspects, one can think on how explainability can be tied to expectations of diverse personas and stakeholders involved in AI ecosystems. These groups usually include users, developers, deployers, affected parties, and regulators [Leluschko&Tholen,2023]. Accordingly, their desiderata — i.e. features and results they expect from AI — also vary widely, suggesting that explainability needs to cater to a wide array of needs and challenges. In the study, Langer et al., 2021 highlight that understanding plays a critical role in addressing the epistemic facet, referring to stakeholders’ ability to assess whether a system meets their expectations, such as fairness and transparency. Figure 5 presents a conceptual model that outlines the pathway from explainability approaches to fulfilling stakeholders’ needs, which, in turn, affects how well their desiderata are met. But what constitutes a “good” explanation? The study argues that it should be not only accurate, representative, and context-specific with respect to a system and its functioning, but also align with socio-ethical and legal considerations, which can be decisive in justifying certain desiderata. For instance, in high-stakes scenarios like medical diagnosis, the depth of explanations required for trust calibration might be greater [Saraswat et al., 2022].
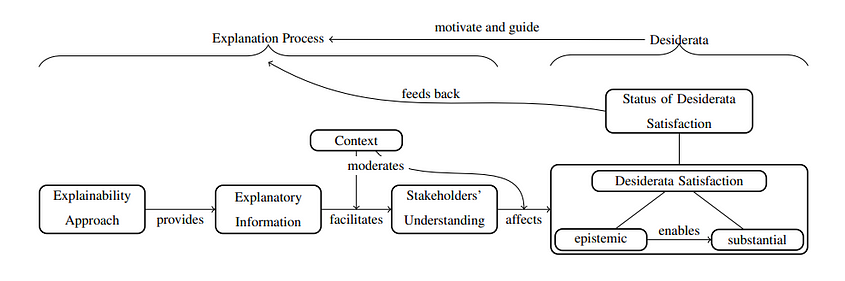
Here, we can say that the success of XAI as technology hinges on how effectively it facilitates human understanding through explanatory information, emphasizing the need for careful navigation of trade-offs among stakeholders. For instance, for domain experts and users (e.g., doctors, judges, auditors), who deal with interpreting and auditing AI system outputs for decision-making, it is important to ensure explainability results are concise and domain-specific to align them with expert intuition, while not creating information overload, which is especially relevant for human-in-the-loop applications. Here, the challenge may arise due to uncertainty and the lack of clear causality between inputs and outputs, which can be addressed through local post-hoc explanations tailored to specific use cases [Metta et al., 2024]. Affected parties (e.g., job applicants, patients) are individuals impacted by AI’s decisions, with fairness and ethics being key concerns, especially in contexts like hiring or healthcare. Here, explainability approaches can aid in identifying factors contributing to biases in decision-making processes, allowing for their mitigation or, at the very least, acknowledgment and elimination [Dimanov et al., 2020]. Similarly, regulators may seek to determine whether a system is biassed toward any group to ensure compliance with ethical and regulatory standards, with a particular focus on transparency, traceability, and non-discrimination in high-risk applications [Gasser & Almeida, 2017, Floridi et al., 2018, The EU AI Act 2024].
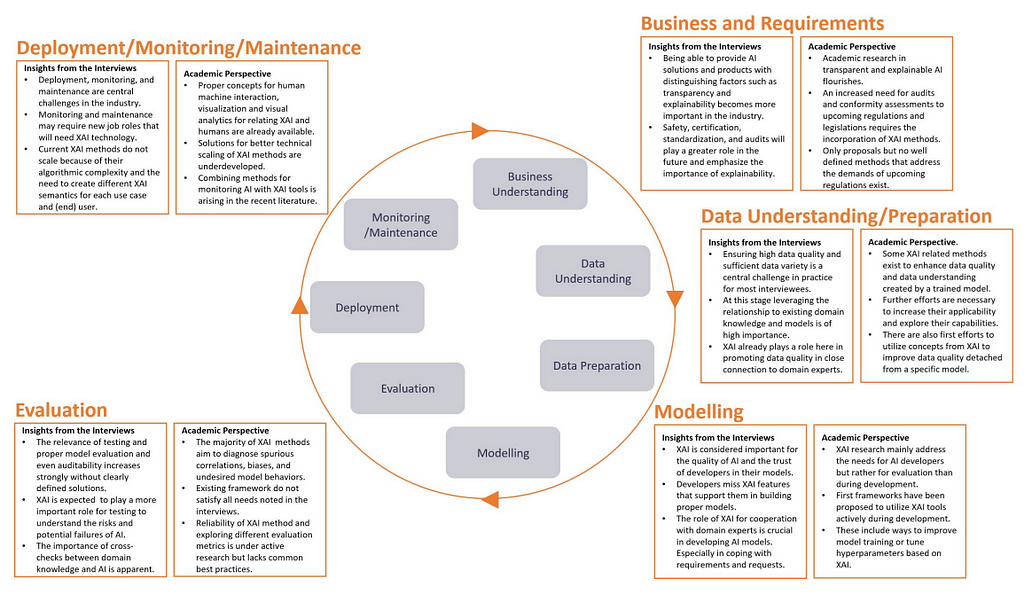
For businesses and organisations adopting AI, the challenge may lie in ensuring responsible implementation in line with regulations and industry standards, while also maintaining user trust [Ali et al., 2023, Saeed & Omlin, 2021]. In this context, using global explanations and incorporating XAI into the ML lifecycle (Figure 6), can be particularly effective [Saeed & Omlin, 2021, Microsoft Responsible AI Standard v2 General Requirements, Google Responsible AI Principles]. Overall, both regulators and deployers aim to understand the entire system to minimize implausible corner cases. When it comes to practitioners (e.g., developers and researchers), who build and maintain AI systems, these can be interested in leveraging XAI tools for diagnosing and improving model performance, along with advancing existing solutions with interpretability interface that can provide details about model’s reasoning [Bhatt et al., 2020]. However, these can come with high computational costs, making large-scale deployment challenging. Here, the XAI development stack can include both open-source and proprietary toolkits, frameworks, and libraries, such as PyTorch Captum, Google Model Card Toolkit, Microsoft Responsible AI Toolbox, IBM AI Fairness 360, for ensuring that systems built are safe, reliable, and trustworthy from development through deployment and beyond.
And as we can see — one size does not fit all. One of the ongoing challenges is to provide explanations that are both accurate and meaningful for different stakeholders while balancing transparency and usability in real-world applications [Islam et al., 2022, Tate et al., 2023, Hutsen, 2023]. Now, let’s talk about XAI in a more practical sense.
4. Model explainability for vision
4.1. Feature attribution methods
As AI systems have advanced, modern approaches have demonstrated substantial improvements in performance on complex tasks, such as image classification (Fig. 2), surpassing earlier image processing techniques that relied heavily on handcrafted algorithms for visual feature extraction and detection [Sobel and Feldman, 1973, Canny, 1987]. While modern deep learning architectures are not inherently interpretable, various solutions have been devised to provide explanations on model behavior for given inputs, allowing to bridge the gap between human (understanding) and machine (processes). Following the breakthroughs in deep learning, various XAI approaches have emerged to enhance explainability aspects in the domain of computer vision. Focusing on image classification and object detection applications, the Figure 7 below outlines several commonly used XAI methods developed over the past decades:
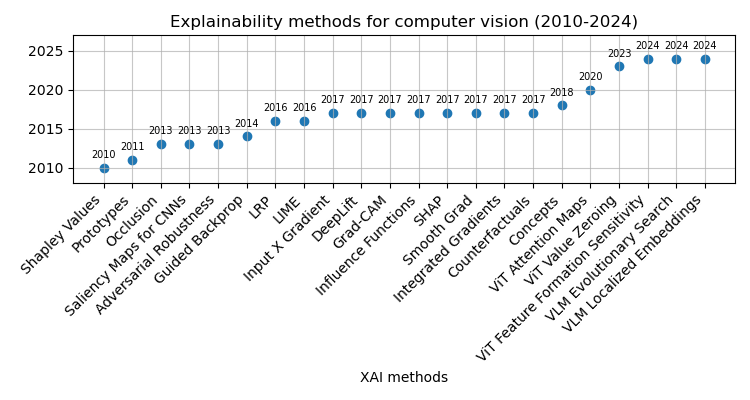
XAI methods can be broadly categorized based on their methodology into backpropagation- and perturbation-based methods, while the explanation scope is either local or global. In computer vision, these methods or combinations of them are used to uncover the decision criteria behind model predictions. Backpropagation-based approaches propagate a signal from the output to the input, assigning weights to each intermediate value computed during the forward pass. A gradient function then updates each parameter at the model to align the output with the ground truth, making these techniques also known as gradient-based methods. Examples include saliency maps [Simonyan et al., 2013], integrated gradient [Sundararajan et al., 2017], Grad-CAM [Selvaraju et al, 2017]. In contrast, perturbation-based methods modify the input through techniques like occlusion [Zeiler & Fergus, 2014], LIME [Ribeiro et al., 2016], RISE [Petsiuk et al., 2018], evaluating how these slight changes impact the network output. Unlike backpropagation-based methods, perturbation techniques don’t require gradients, as a single forward pass is sufficient to assess how the input changes influence the output.
Explainability for “black box” architectures is typically achieved through external post-hoc methods after the model has been trained (e.g., gradients for CNN). In contrast, “white-box” architectures are interpretable by design, where explainability can be achieved as a byproduct of the model training. For example, in linear regression, coefficients derived from solving a system of linear equations can be used directly to assign weights to input features. However, while feature importance is straightforward in the case of linear regression, more complex tasks and advanced architectures consider highly non-linear relationships between inputs and outputs, thus requiring external explainability methods to understand and validate which features have the greatest influence on predictions. That being said, using linear regression for computer vision isn’t a viable approach.
4.2. Evaluation metrics for XAI
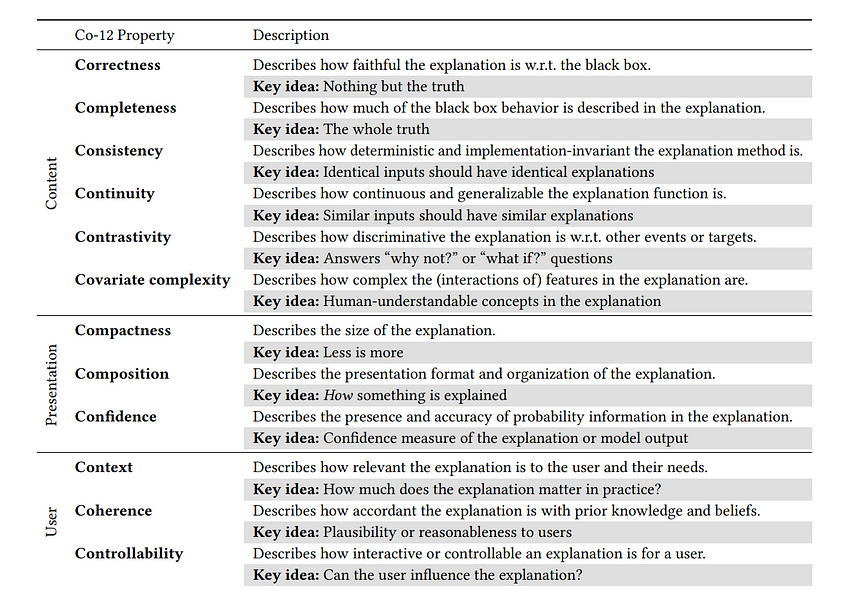
Evaluating explanations is essential to ensure that the insights derived from the model and their presentation to end-users — through the explainability interface — are meaningful, useful, and trustworthy [Ali et al., 2023, Naute et al., 2023]. The increasing variety of XAI methods necessitates systematic evaluation and comparison, shifting away from subjective “I know it when I see it” approaches. To address this challenge, researchers have devised numerous algorithmic and user-based evaluation techniques, along with frameworks and taxonomies, to capture both subjective and objective quantitative and qualitative properties of explanations [Doshi-Velez & Kim, 2017, Sokol & Flach, 2020]. Explainability is a spectrum, not a binary characteristic, and its effectiveness can be quantified by assessing the extent to which certain properties are to be fulfilled. One of the ways to categorize XAI evaluation methods is along the so-called Co-12 properties [Naute et al., 2023], grouped by content, presentation, and user dimensions, as summarized in Table 1.
At a more granular level, quantitative evaluation methods for XAI can incorporate metrics, such as faithfulness, stability, fidelity, and explicitness [Alvarez-Melis & Jaakkola, 2018, Agarwal et al., 2022, Kadir et al., 2023], enabling the measurement of the intrinsic quality of explanations. Faithfulness measures how well the explanation aligns with the model’s behavior, focusing on the importance of selected features for the target class prediction. Qi et al., 2020 demonstrated a method for feature importance analysis with Integrated Gradients, emphasizing the importance of producing faithful representations of model behavior. Stability refers to the consistency of explanations across similar inputs. A study by Ribeiro et al., 2016 on LIME highlights the importance of stability in generating reliable explanations that do not vary drastically with slight input changes. Fidelity reflects how accurately an explanation reflects the model’s decision-making process. Doshi-Velez & Kim, 2017 emphasize fidelity in their framework for interpretable machine learning, arguing that high fidelity is essential for trustworthy AI systems. Explicitness involves how easily a human can understand the explanation. Alvarez-Melis & Jaakkola, 2018 discussed robustness in interpretability through self-explaining neural networks (SENN), which strive for explicitness alongside stability and faithfulness.
To link the concepts, the correctness property, as described in Table 1, refers to the faithfulness of the explanation in relation to the model being explained, indicating how truthful the explanation reflects the “true” behavior of the black box. This property is distinct from the model’s predictive accuracy, but rather descriptive to the XAI method with respect to the model’s functioning [Naute et al., 2023, Sokol & Vogt, 2024]. Ideally, an explanation is “nothing but the truth”, so high correctness is therefore desired. The faithfulness via deletion score can be obtained [Won et al., 2023] by calculating normalized area under the curve representing the difference between two feature importance functions: the one built by gradually removing features (starting with the Least Relevant First — LeRF) and evaluating the model performance at every step, and another one, for which the deletion order is random (Random Order — RaO). Computing points for both types of curves starts with providing the full image to the model and continues with a gradual removal of pixels, whose importance, assigned by an attribution method, lies below a certain threshold. A higher score implies that the model has a better ability to retain important information even when redundant features are deleted (Equation 1).
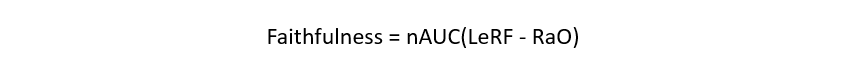
Another approach for evaluating faithfulness is to compute feature importance via insertion, similar to the method described above, but by gradually showing the model the most relevant image regions as identified by the attribution method. The key idea here: include important features and see what happens. In the demo, we will explore both qualitative and quantitative approaches for evaluating model explanations.
5. Feature importance for fine-grained classification
In fine-grained classification tasks, such as distinguishing between different vehicle types or identifying bird species, small variations in visual appearance can significantly affect model predictions. Determining which features are most important for the model’s decision-making process can help to shed light on misclassification issues, thus allowing to optimize the model on the task. To demonstrate how explainability can be effectively applied to leverage understanding on deep learning models for vision, we will consider a use case of bird classification. Bird populations are important biodiversity indicators, so collecting reliable data of species and their interactions across environmental contexts is quite important to ecologists [Atanbori et al., 2016]. In addition, automated bird monitoring systems can also benefit windfarm producers, since the construction requires preliminary collision risk assessment and mitigation at the design stages [Croll et al., 2022]. This part will showcase how to apply XAI methods and metrics to enhance model explainability in bird species classification (more on the topic can be found in the related article and tutorials).
Figure 8 below presents the feature importance analysis results for fine-grained image classification using ResNet-50 pretrained on ImageNet and fine-tuned on the Caltech-UCSD Birds-200–2011 dataset. The qualitative assessment of faithfulness was conducted for the Guided Grad-CAM method to evaluate the significance of the selected features given the model. Quantitative XAI metrics included faithfulness via deletion (FTHN), with higher values indicating better faithfulness, alongside metrics that reflect the degree of non-robustness and instability, such as maximum sensitivity (SENS) and infidelity (INFD), where lower values are preferred. The latter metrics are perturbation-based and rely on the assumption that explanations should remain consistent with small changes in input data or the model itself [Yeh et al., 2019].
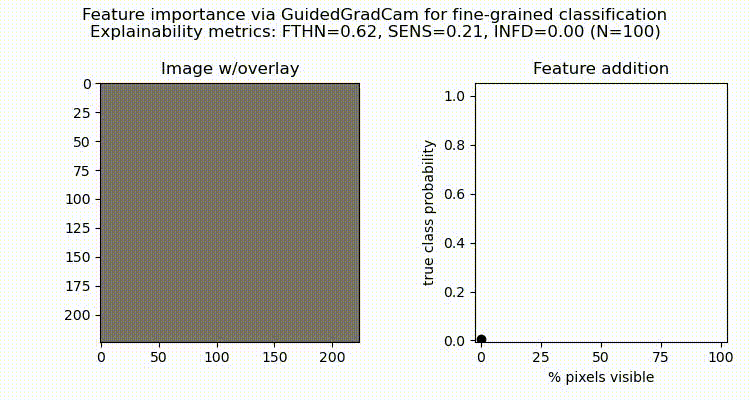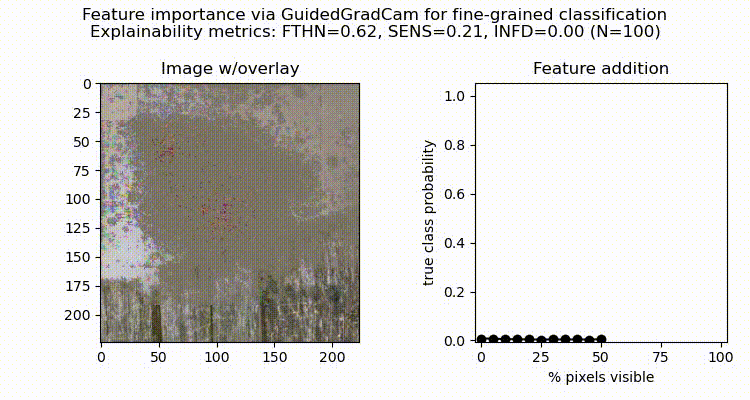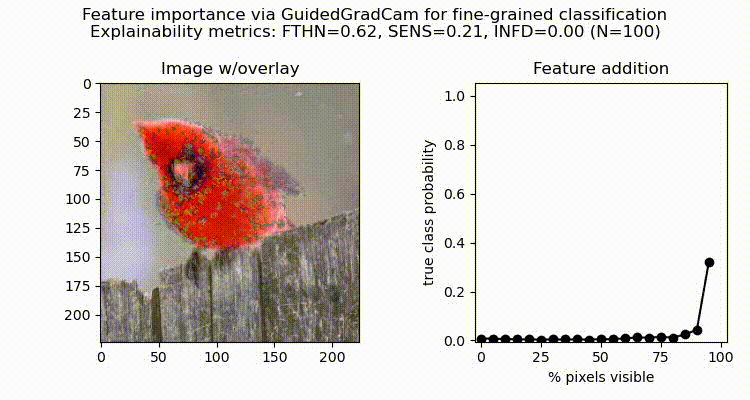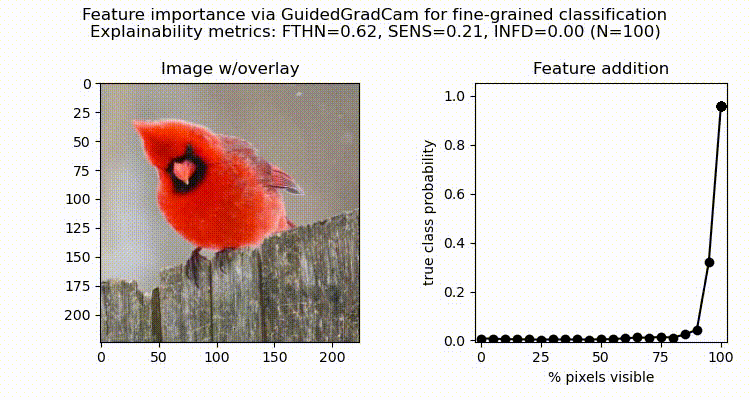
When evaluating our model on an independent test image of Northern Cardinal, we notice that slight changes in the model’s scores during the initial iterations are followed by a sharp increase toward the final iteration as the most critical features are progressively incorporated (Fig. 8). These results suggest two key interpretations regarding the model’s faithfulness with respect to the evaluated XAI methods. Firstly, attribution-based interpretability using Guided GradCAM is faithful to the model, as adding regions identified as redundant (90% of LeRF, axis-x) caused minimal changes in the model’s score (less than 0.1 predicted probability score). This implies that the model did not rely on these regions when making predictions, in contrast to the remaining top 10% of the most relevant features identified. Another category — robustness — refers to the model resilience to small input variations. Here, we can see that changes in around 90% of the original image had little impact on the overall model’s performance, maintaining the target probability score despite changes to the majority of pixels, suggesting its stability and generalization capabilities for the target class prediction.
To further assess the robustness of our model, we compute additional metrics, such as sensitivity and infidelity [Yeh et al., 2019]. Results indicate that while the model is not overly sensitive to slight perturbations in the input (SENS=0.21), the alterations to the top-important regions may potentially have an influence on model decisions, in particular, for the top-10% (Fig. 8). To perform a more in-depth assessment of the sensitivity of the explanations for our model, we can further extend the list of explainability methods, for instance, using Integrated Gradients and SHAP [Lundberg & Lee, 2017]. In addition, to assess model resistance to adversarial attacks, the next steps may include quantifying further robustness metrics [Goodfellow et al., 2015, Dong et al., 2023].
Conclusions
This article provides a comprehensive overview of scientific literature published over past decades encompassing key milestones in deep learning and computer vision that laid the foundation of the research in the field of XAI. Reflecting on recent technological advances and perspectives in the field, we discussed potential implications of XAI in light of emerging AI regulatory frameworks and responsible AI practices, anticipating the increased relevance of explainability in the future. Furthermore, we examined application domains and explored stakeholders’ groups and their desiderata to provide practical suggestions on how XAI can address current challenges and needs for creating reliable and trustworthy AI systems. We have also covered fundamental concepts and taxonomies related to explainability, commonly used methods and approaches used for vision, along with qualitative and quantitative metrics to evaluate post-hoc explanations. Finally, to demonstrate how explainability can be applied to leverage understanding on deep learning models, the last section presented a case in which XAI methods and metrics were effectively applied to a fine-grained classification task to identify relevant features affecting model decisions and to perform quantitative and qualitative assessment of results to validate quality of the derived explanations with respect to model reasoning.
What’s next?
In the upcoming article, we will further explore the topic of explainability and its practical applications, focusing on how to leverage XAI in design for optimizing model performance and reducing classification errors. Interested to keep it on? Stay updated on more materials at — https://github.com/slipnitskaya/computer-vision-birds and https://medium.com/@slipnitskaya.
100 Years of (eXplainable) AI was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
100 Years of (eXplainable) AI